 第11章-控制器与节点驱逐
第11章-控制器与节点驱逐
原创
本博客原创文章,转载请注明出处
- name: 原创
desc: 本博客原创文章,转载请注明出处
bgColor: '#F0DFB1'
textColor: '#1078E6'
2
3
4
# 第11章-控制器与节点
| 本章要点 |
|---|
| 掌握节点的停止、恢复、驱逐和删除 |
| 了解驱逐特性 |
| 了解停止、驱逐和删除这三者之间的区别 |
在第 3 章和第 4 章中,我们曾通过kubectl drain命令将节点设置成维护模式。现在,将详细介绍其作用,以及这些命令之间的区别。
# 11. 创建测试Pod和Deployment
在开始实验之前,我们先创建一些独立的 Pod 和控制器 Deployment:
# pod1.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod1
spec:
nodeSelector:
kubernetes.io/hostname: www.k11.com
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: c1
2
3
4
5
6
7
8
9
10
11
12
apiVersion: v1
kind: Pod
metadata:
name: pod2
spec:
nodeSelector:
kubernetes.io/hostname: www.k12.com
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: c2
2
3
4
5
6
7
8
9
10
11
# d-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: d-test
spec:
replicas: 4
selector:
matchLabels:
run: deploy
template:
metadata:
labels:
run: deploy
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: cc
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
创建以上 Pod 和控制器:
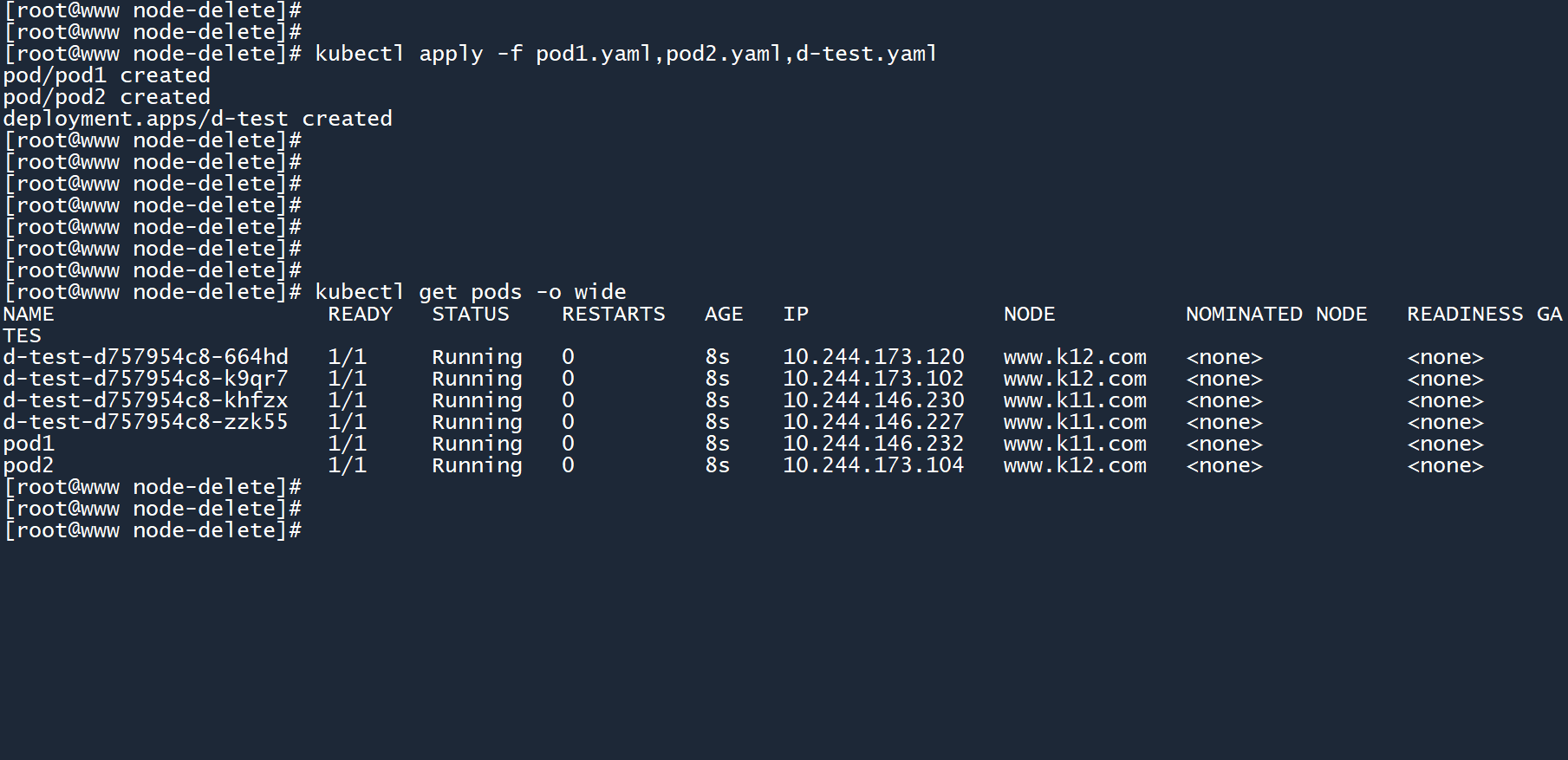
kubectl apply -f pod1.yaml,pod2.yaml,d-test.yaml
kubectl get pods -o wide
2
3
现在,节点 worker01 和 worker02 上各有三个 Pod。
- 其中两个是独立的 Pod
- 其中四个是由控制器所控制的 Pod
# 22. 节点的停止(封锁)
如果你想停止调度一个节点,让后续创建的 Pod 都不会在其上运行,则可以使用以下命令:
kubectl cordon <节点名称>
cordon又叫 “封锁”,所以kubectl cordon又被称为 “封锁节点”。
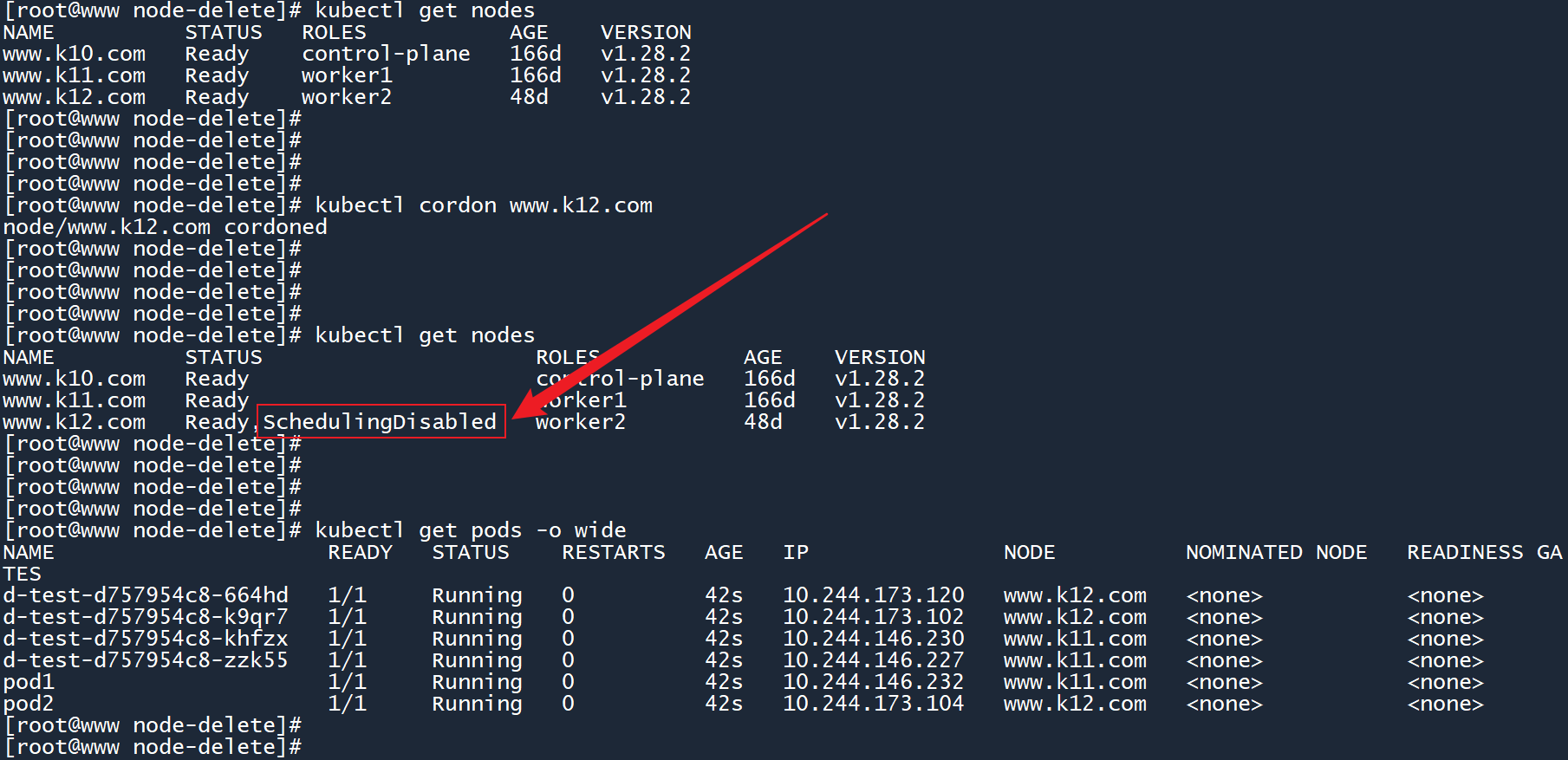
1、下面尝试停止 worker02 节点:
kubectl cordon www.k12.com
停止 worker02 节点后,状态栏中会多出一个状态值 “SchedulingDisabled”(禁止调度)。
在 worker02 节点上,原来已经存在的 Pod 依然会正常运行,不会受到影响。而后续创建的 Pod 不会在其上运行。
2、我们来验证一下 “后续创建的 Pod 不会在其上运行” 这段话。创建以下 Pod,通过字段nodeSelector和标签kubernetes.io/hostname,强制该 Pod 运行在 worker02 节点上:
# cordon-test.yaml
apiVersion: v1
kind: Pod
metadata:
name: cordon-test
spec:
nodeSelector:
kubernetes.io/hostname: www.k12.com
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: cordon-test
2
3
4
5
6
7
8
9
10
11
12
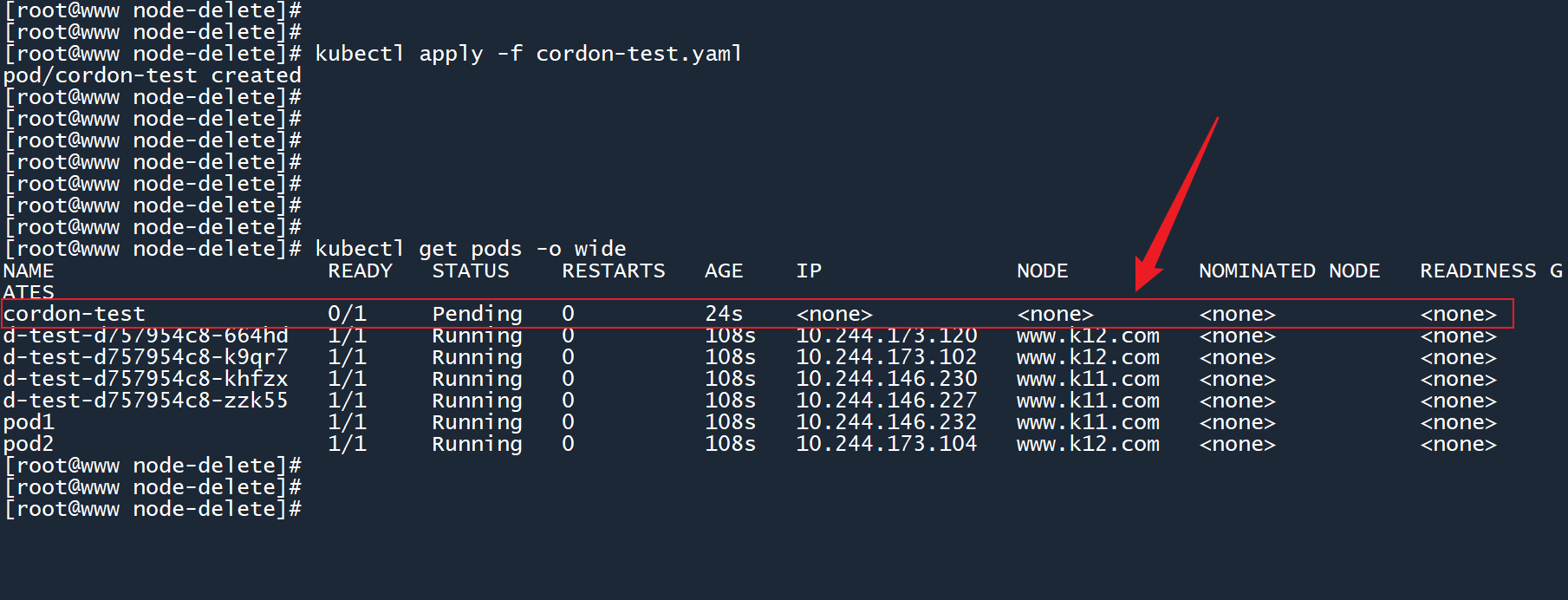
kubectl apply -f cordon-test.yaml
创建这个 Pod 之后,可以看到这个 Pod 的状态一直停留在 “Pending”(等待)。
由于 worker02 节点被停止调度,其他的节点又无法满足nodeSelector所设置的条件,所以该 Pod 会一直处于 “Pending” 状态,直到出现合适的节点。
# 33. 节点的恢复
恢复一个节点的使用状态:
kubectl uncordon <节点名称>
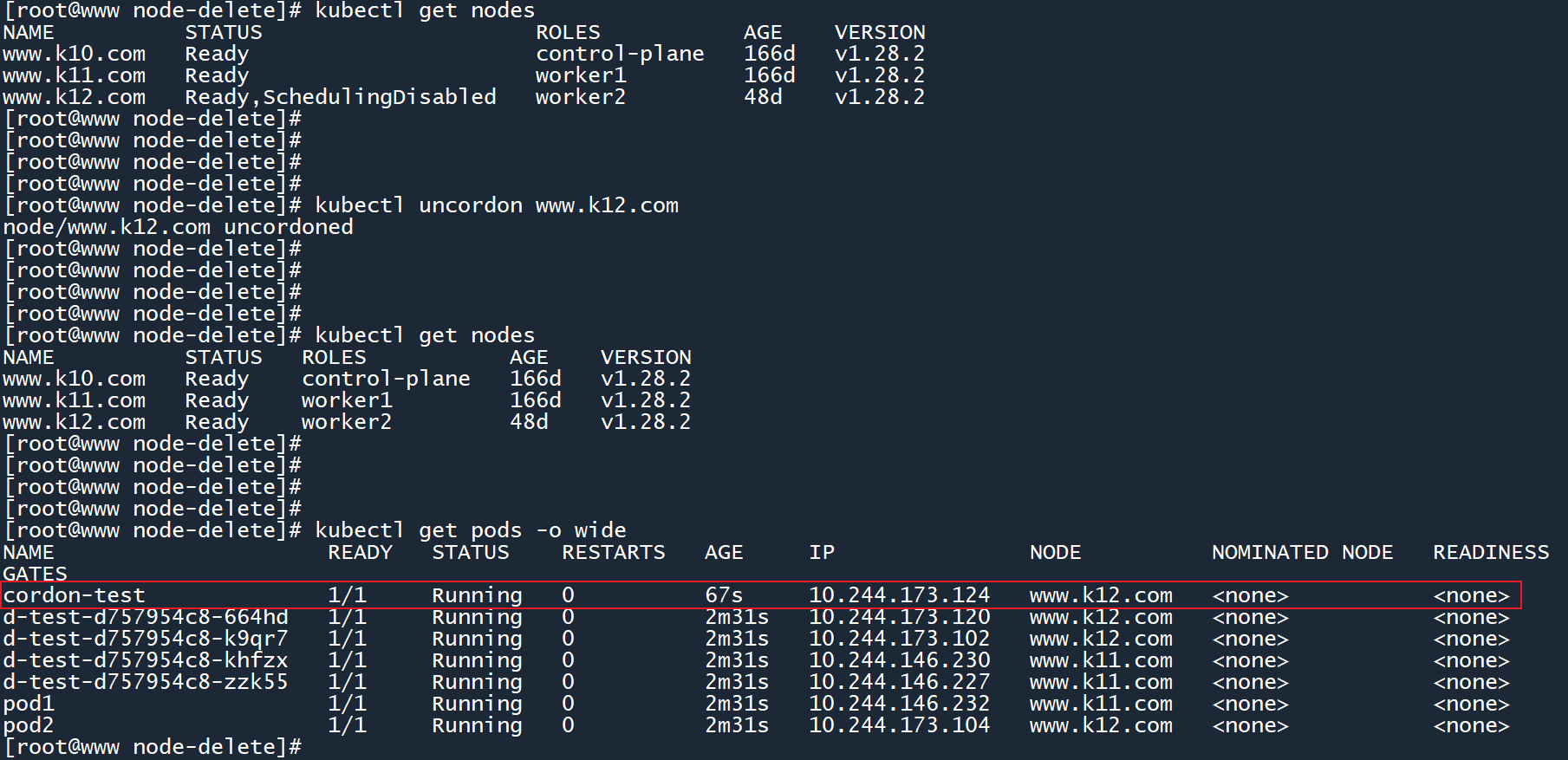
恢复 worker02 节点,将其转变为可调度状态:
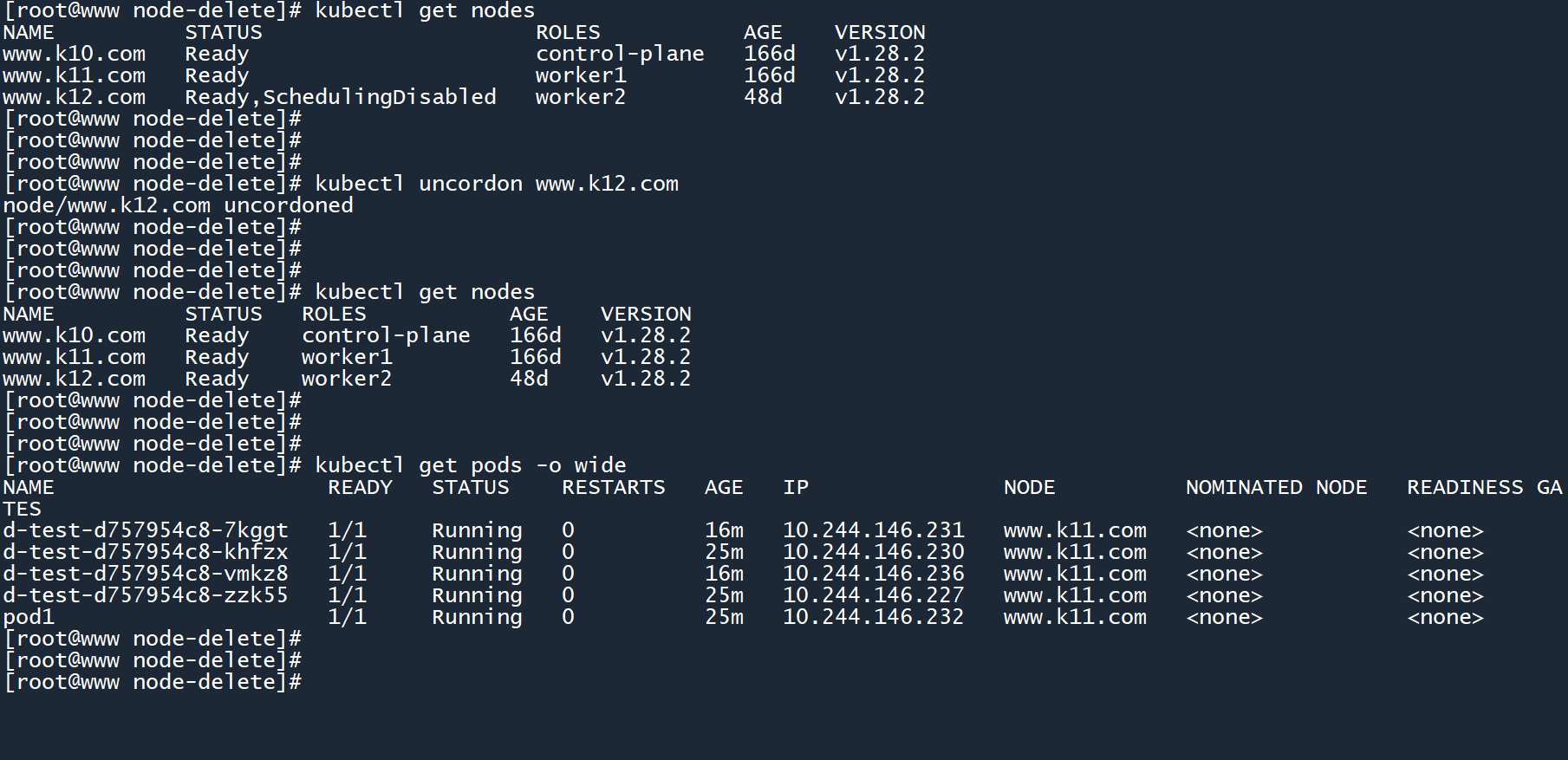
kubectl uncordon www.k12.com
执行命令后,worker02 节点的 “SchedulingDisabled”(禁止调度)状态消失了,并且cordon-test的状态也从 “Pending” 变为了 “Running”。
# 44. 节点的驱逐
这个命令在之前的章节中使用过:
kubectl drain <节点名称>
drain类似于cordon,都可以用于停止一个节点。但是drain多了一个操作:驱逐。
什么意思呢?
cordon会停止一个节点,已经运行在该节点上的 Pod 不受影响,会继续正常运行。drain除了停止一个节点之外,还会将该节点上的 Pod 全部驱逐到其他节点上运行。这可以完全清空一个节点。
1、我们来尝试一下,通过drain停止 worker02 节点,并驱逐上面运行的所有 Pod:
kubectl drain www.k12.com
第一次执行drain命令,你会发现返回了一堆错误信息。但此时 worker02 节点的状态已经变为 “停止调度” 了,看起来貌似没什么问题?
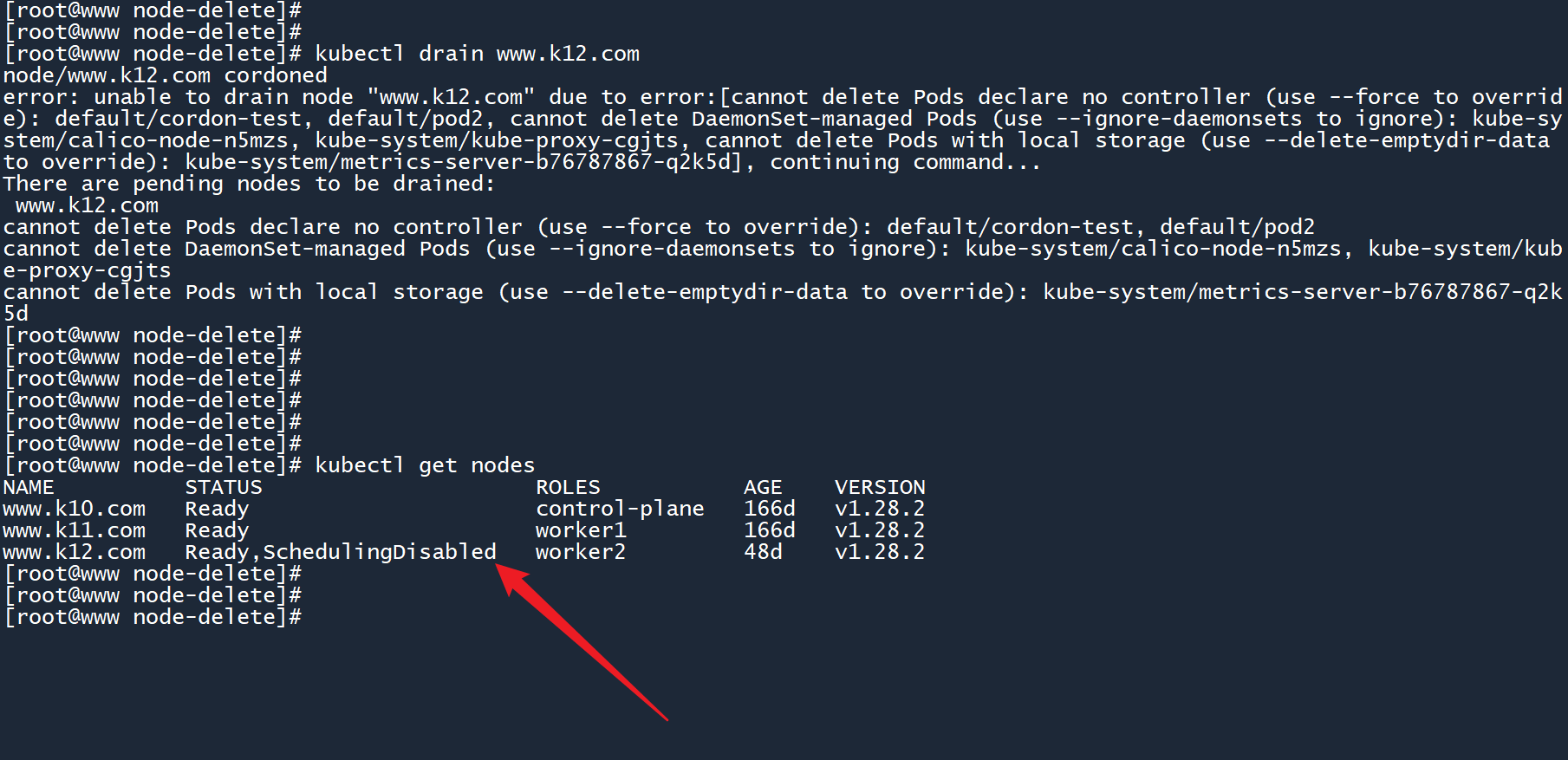
2、查看 Pod,发现这些 Pod 依然运行在 worker02 节点上,为什么?答案就在错误信息中:
- 无法删除没有控制器的 Pod,你可以使用
--force(强制删除)来执行操作。 - 无法删除由 DaemonSet 所管理的 Pod,你可以使用
--ignore-daemonsets选项来忽略这些 Pod,因为 DaemonSet 一般是用于监控节点、维护节点通信的,所以不能删除 要忽略。 - 无法删除某些 Pod,因为这些 Pod 在所运行的节点上创建了一些临时数据,你需要使用选项
--delete-emptydir-data来删除这些临时数据(删除后一般不影响集群运行)。
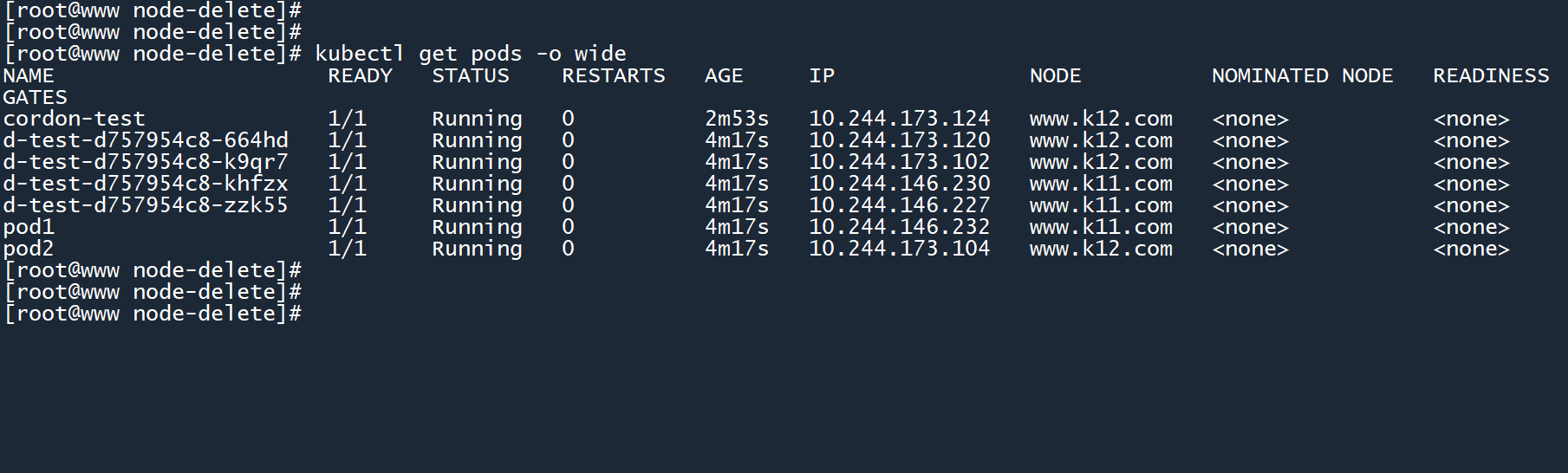
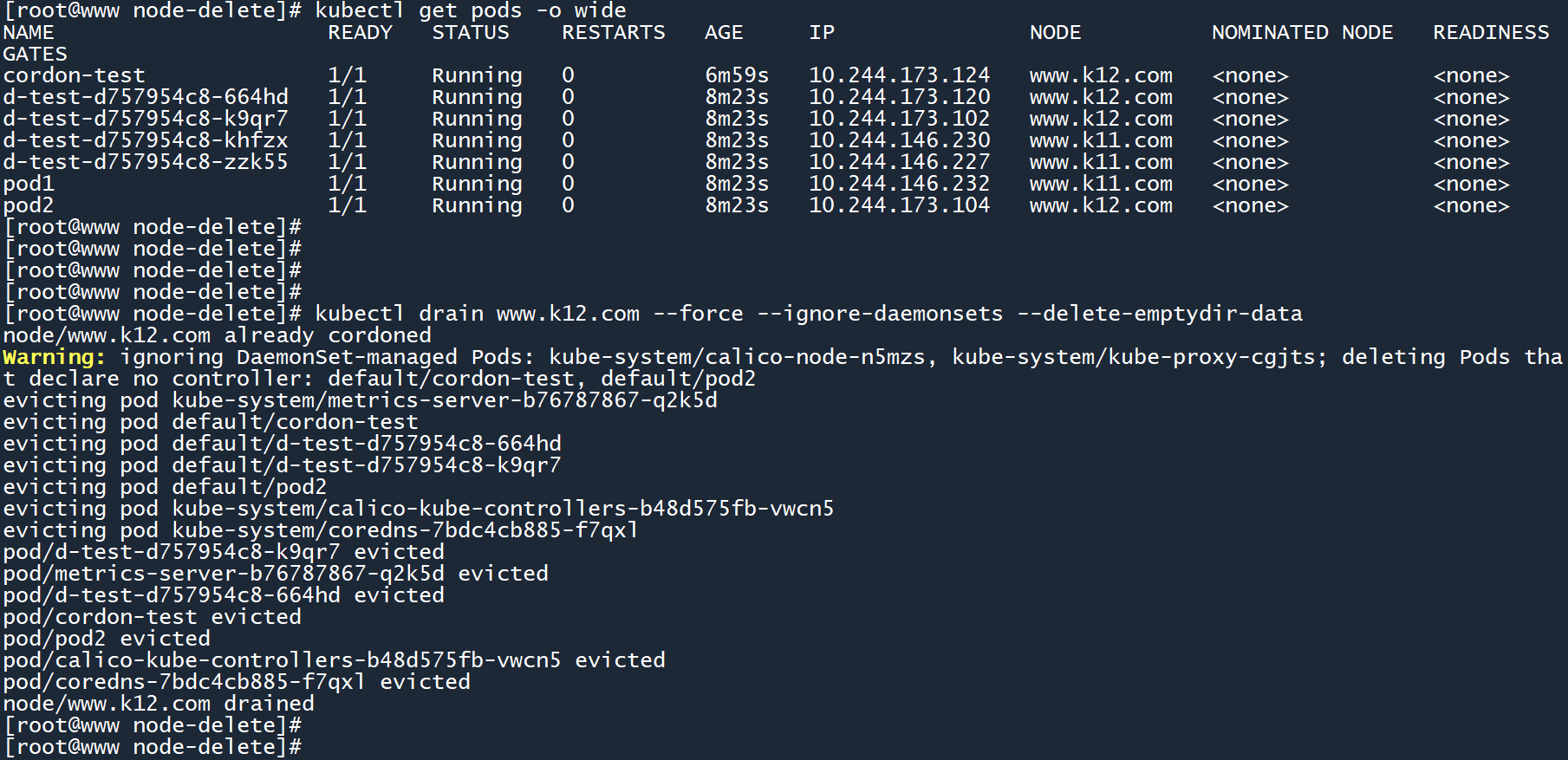
3、重新执行命令,驱逐 worker02 节点上的所有 Pod:
# 再次驱逐节点
kubectl drain www.k12.com --force --ignore-daemonsets --delete-emptydir-data
2
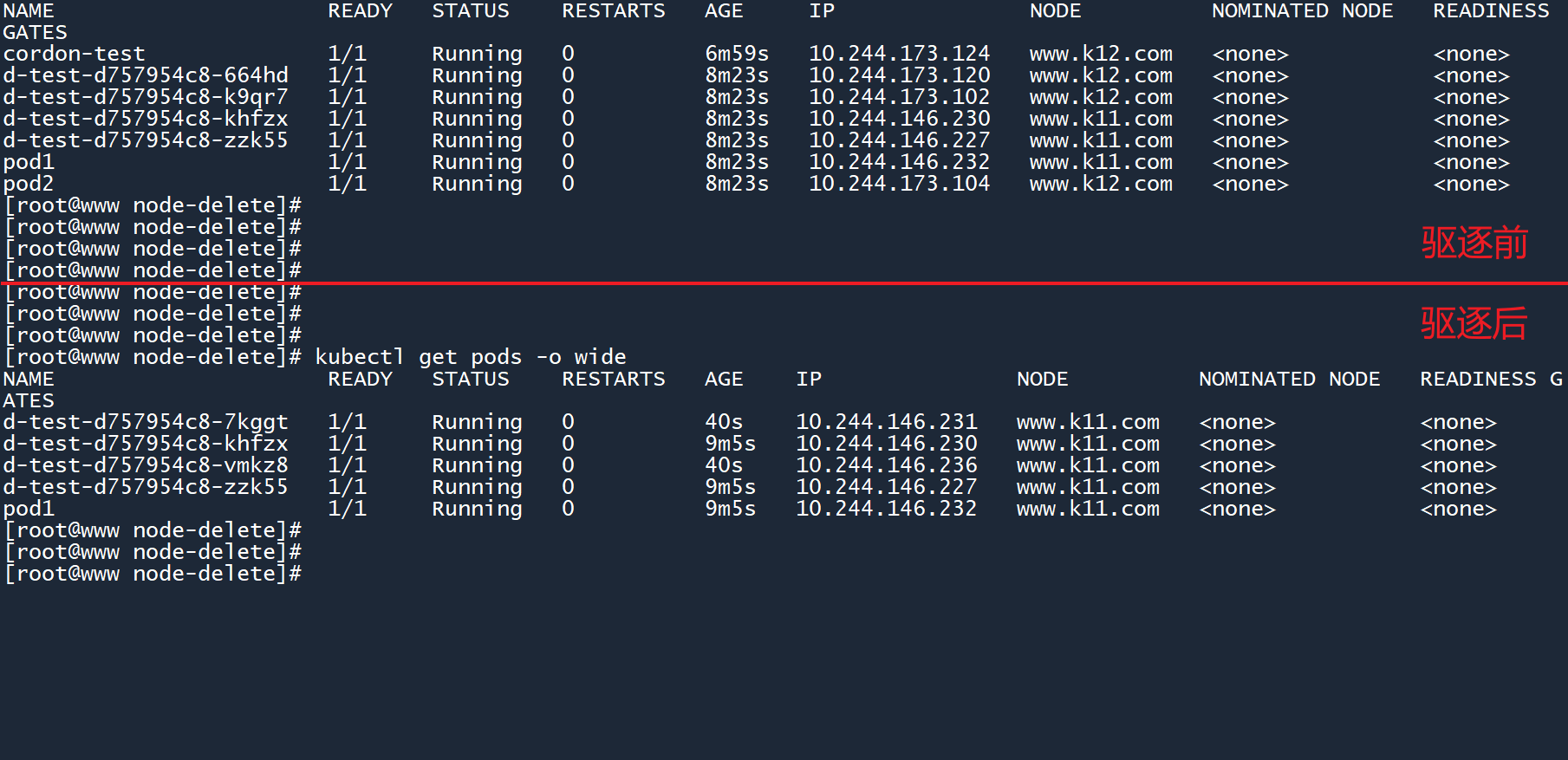
4、再次查看 Pod:
kubectl get pods -o wide
你会发现,原本位于 worker02 上的独立 Pod pod2已经被删除了。
而原本位于 worker02 上拥有控制器的 Pod,被驱逐至 worker01 节点上运行了(两个运行时间为40s的 Pod)。这些 Pod 并不是被 “移动” 到 worker01 节点上的,而是被 Deployment 新创建出来的。
驱逐原理
驱逐一个节点,其实就是将节点设置为不可用状态,然后删除这个节点上所有 Pod。
- 对于独立创建的 Pod,它会被彻底删除。这是个敏感操作,所以 k8s 要求你添加选项
--force(强制删除)来确认操作。 - 对于拥有控制器的 Pod,并不是小心翼翼地 “移动” 这些 Pod 到另一个节点之上,也是直接删除这些 Pod,当控制器 Deployment 监测到 Pod 数量变少了的时候,它就会自动创建新的 Pod 以填补副本数的空缺。此时 worker02 节点已经处于不可用状态了,所以这些新的 Pod 会被调度到 worker01 节点上运行。
- 对于控制器类型为 DaemonSet 的 Pod,这类 Pod 一般被用于集群自身的运行,所以需要使用
--ignore-daemonsets选项来忽略它们。 - 对于存储了临时数据的 Pod,也是个敏感操作,所以 k8s 要求你添加选项
--delete-emptydir-data(删除临时数据)来确认操作。
5、“驱逐节点” 只不过是在 “停止节点” 的基础之上增加了一个驱逐 Pod 的操作而已,所以该节点同样可以使用uncordon命令来恢复运行:
kubectl uncordon www.k12.com
kubectl get nodes
2
但原本运行在 worker02 节点上的 Pod 不会自己跑回去。
# 55. 节点的删除
这个命令在之前也使用过:
kubectl delete nodes <节点名称>
1、你可以在节点处于运行状态的时候,直接删除节点,这比较简单粗暴:
# 不推荐直接删除节点
kubectl delete ndoes <节点名称>
2
如果你直接删除了节点,而没有清空上面的 Pod,则这些 Pod 都会被强制删除。
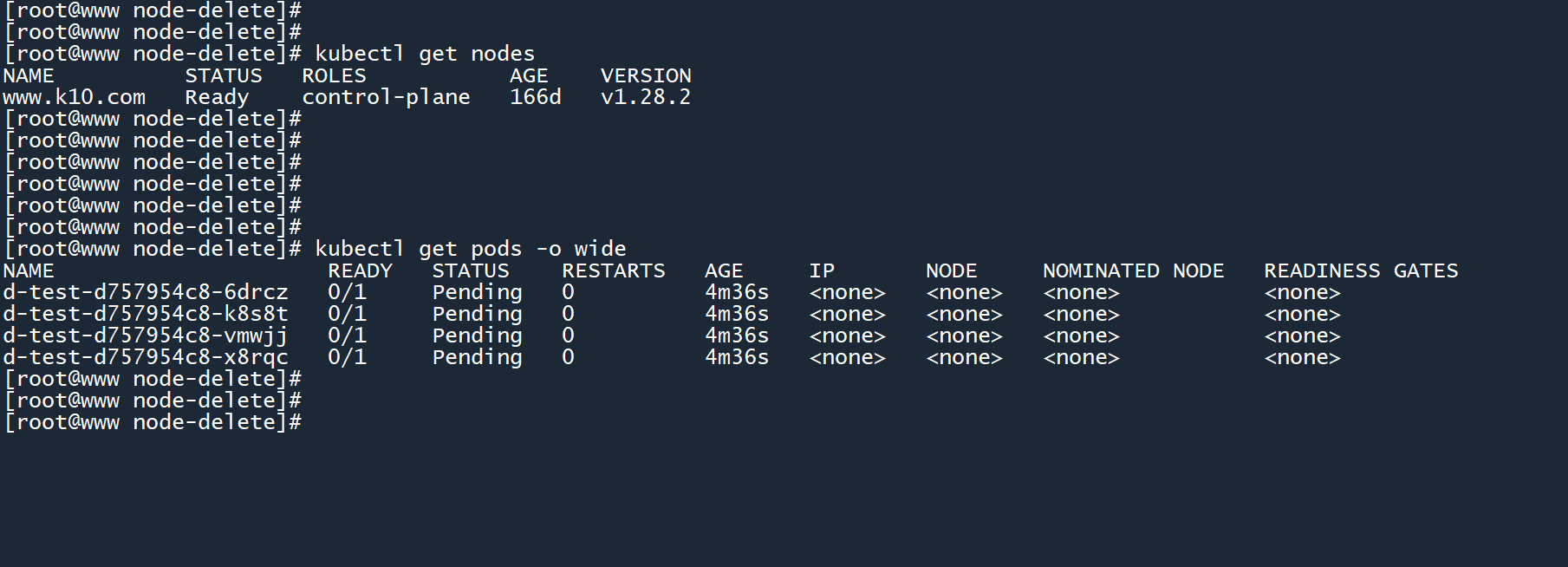
2、正常来说,我们会先 “驱逐” 一个节点以清空其上运行的所有 Pod,最后再删除节点:
# 推荐
kubectl drain <节点名称>
kubectl delete ndoes <节点名称>
2
3
3、被删除的节点可以通过kubeadm join命令重新加入集群:
# (1)在 master 上获取一个新的加入命令
kubeadm token create --print-join-command
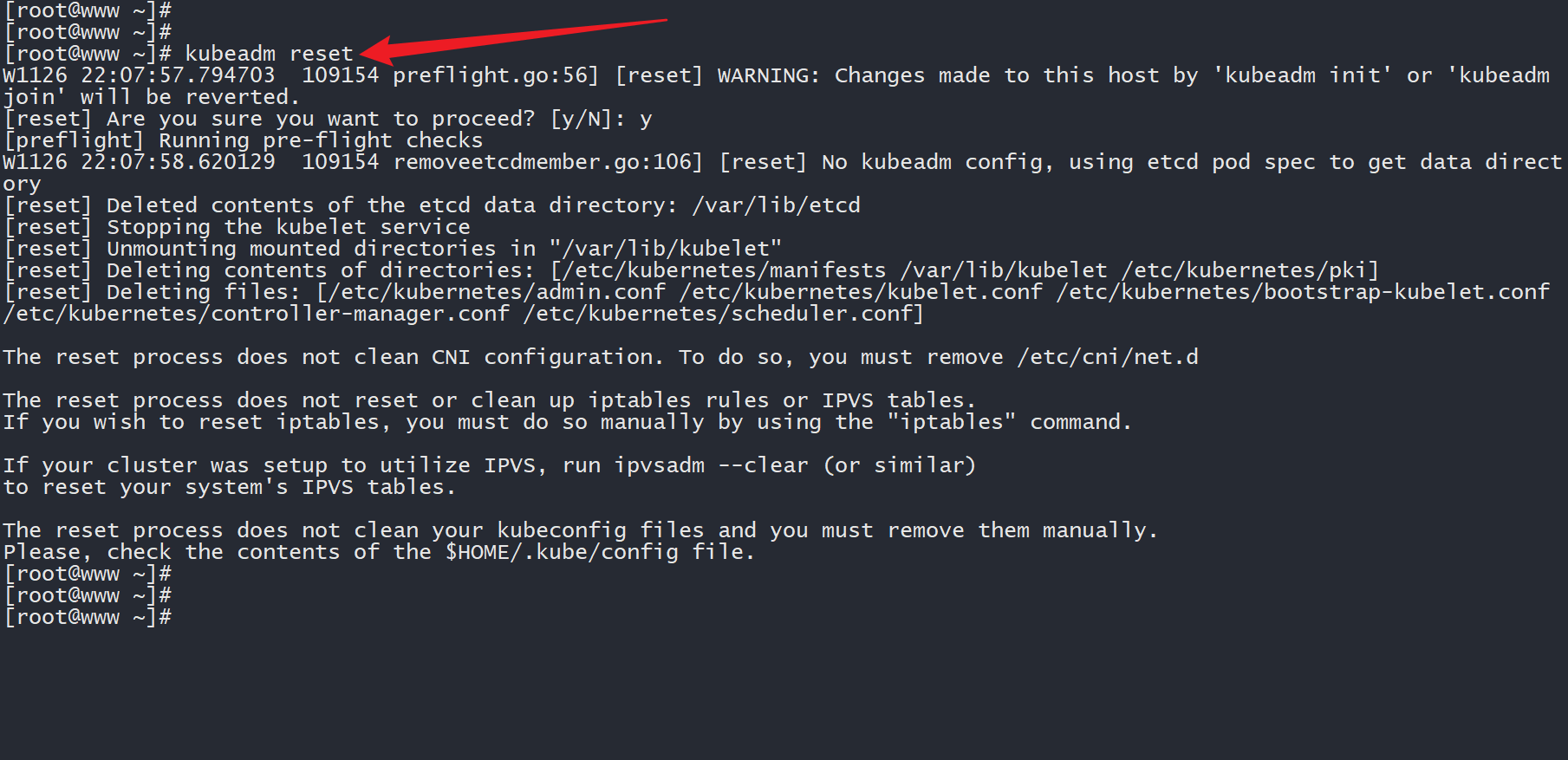
# (2)在 worker 上初始化原来的集群设置,然后加入集群
kubeadm reset
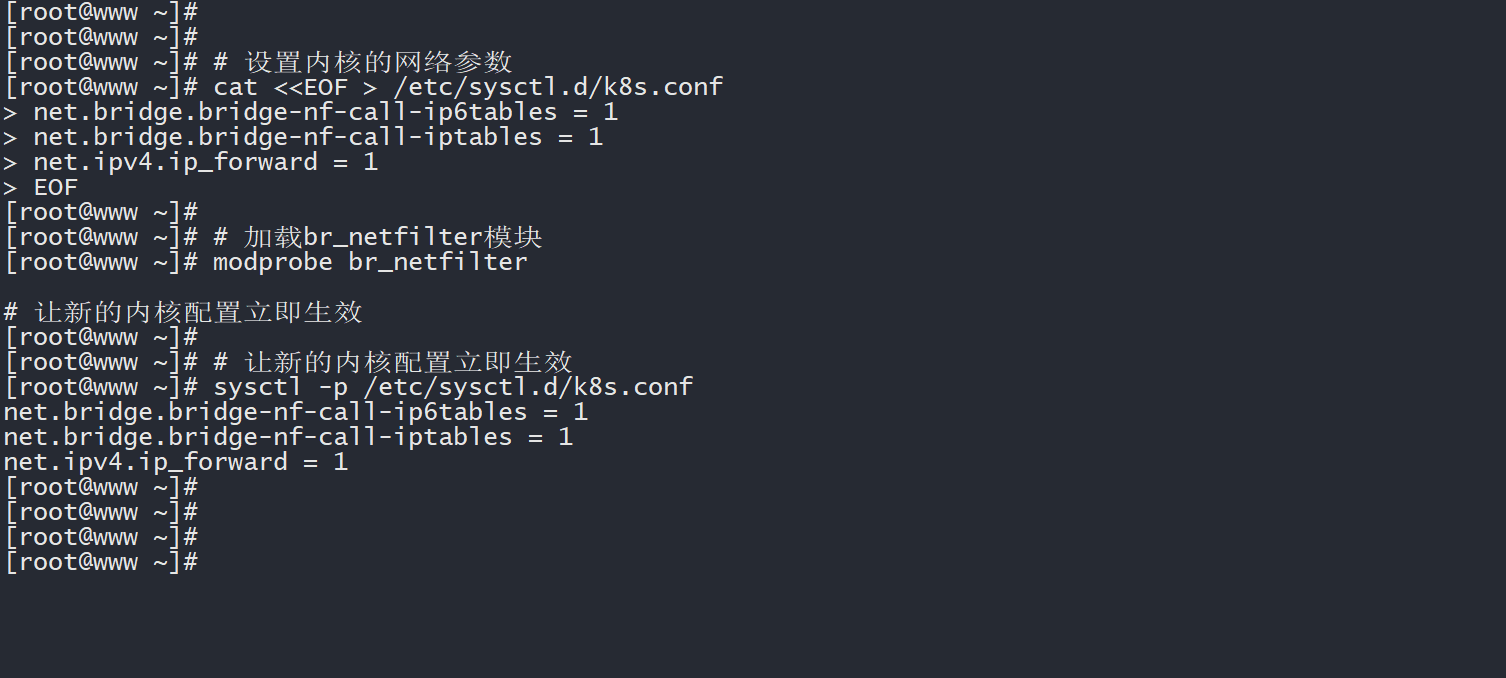
# (3)在 worker 上重新配置内核参数
cat <<EOF > /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
modprobe br_netfilter
sysctl -p /etc/sysctl.d/k8s.conf
# (4)在 worker 上重新加入集群
kubeadm join 192.168.80.10:6443 --token <你的集群令牌> --discovery-token-ca-cert-hash <你的集群证书哈希>
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
worker 重置集群设置。
worker 重新设置内核参数。
worker 加入集群。
master 查看节点。
# 66. 小结
本章内容较为简单,只需要掌握节点的三停(停止、驱逐、删除)和一复(恢复)即可。
本章没有练习,只需要熟读 2~5 小节的内容、并进行相应的实操即可。