 第8章-控制器Deployment
第8章-控制器Deployment
原创
本博客原创文章,转载请注明出处
- name: 原创
desc: 本博客原创文章,转载请注明出处
bgColor: '#F0DFB1'
textColor: '#1078E6'
2
3
4
# 第8章-控制器Deployment
| 本章要点 |
|---|
| 创建和删除 Deployment |
| 修改 Deployment 副本数 |
| 为 Deployment 配置水平自动扩缩 HPA |
# 11. 控制器Deployment
# 1.11.1 什么是控制器?
在之前的章节中,我们曾通过命令行或 yaml 文件的方式创建一个独立的 Pod。但这种 Pod 是不稳定、不健壮的,在运行过程中,一旦某个 Pod 被意外终止,那么这个 Pod 就是真的没了,它不会自己再创建并重新运行。
控制器,顾名思义,这是一种用来控制集群资源的工具。在 k8s 中有很多种控制器,而 deployment (opens new window)(简称 deploy)是最常用的其中一种控制器。
# 1.21.2 deployment 的作用是什么?
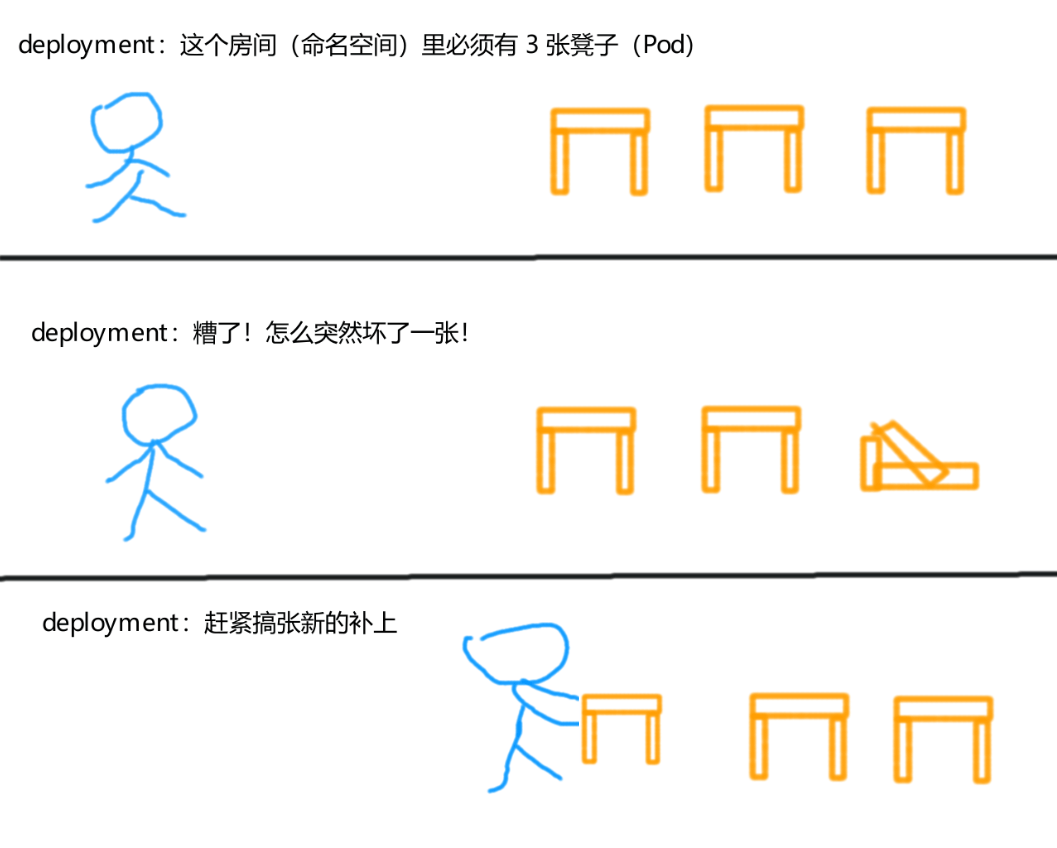
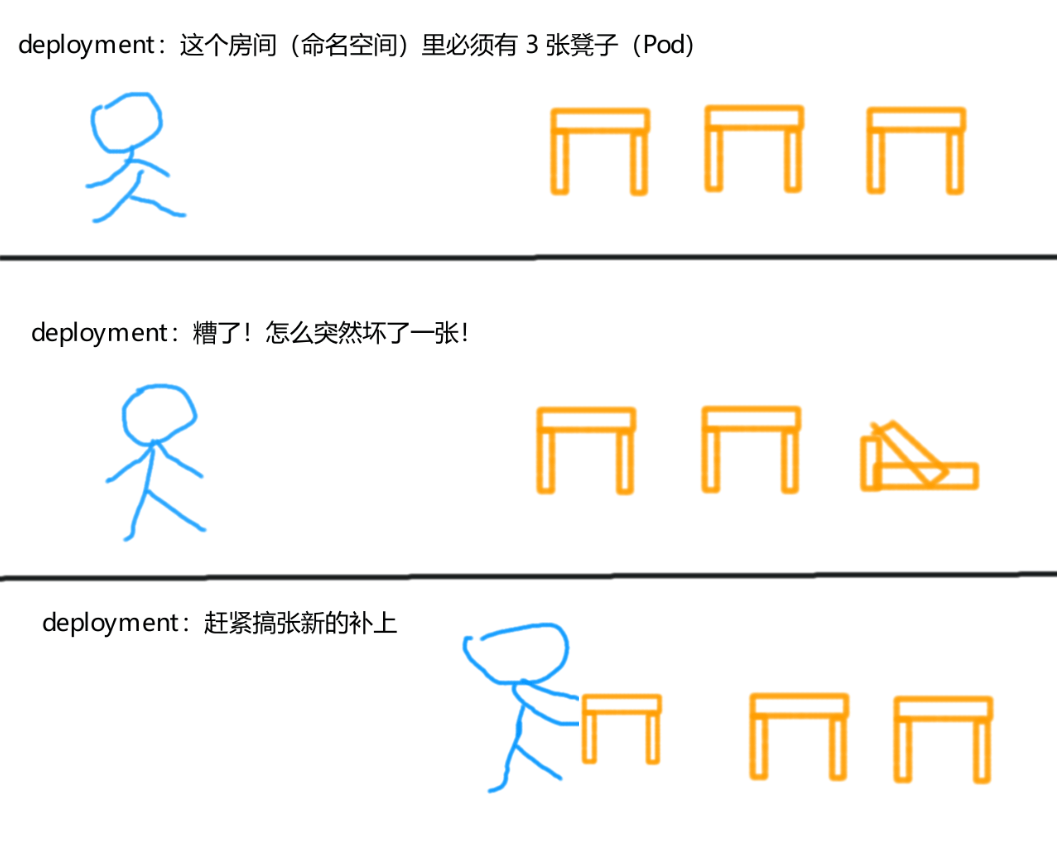
在某个命名空间中,你只需要告诉 deployment 你需要多少个 Pod,那么 deployment 就会帮你维持多少个 Pod。
例如,你在命名空间default中始终需要 3 个 Pod 来承载业务:
- deployment 会自动在
default中创建 3 个 Pod,并确保 Pod 的数量始终保持在 3 个; - 假如其中的某一个 Pod 意外终止了(挂掉),那么 deployment 就会立马重新运行一个 Pod,以填补这个空缺
# 22. 创建Deployment
和 Pod 一样,Deployment 也可以通过命令行工具kubectl进行创建。
也和 Pod 一样,官方推荐你通过 yaml 文件的方式来创建 Deployment。
从 kubernetes v1.18.x 版本开始,Deployment 在命令行中只支持--image选项,其余选项都不支持。所以,为了给 Deployment 配置更多的功能特性,我们只能选择 yaml 这一种方式了(官方强迫)。
# 2.12.1 通过yaml文件创建Deployment
在之前的章节中,我们曾通过--dry-run=client和-o yaml选项,来快速生成一个 Pod 的 yaml 配置文件。就像这样:
--dry-run=client:试运行,并不会真的创建资源-o yaml:以 YAML 文件的格式输出该资源的配置信息
kubectl run pod1 --image nginx --dry-run=client -o yaml > pod1.yaml
除了使用的子命令不同以外,我们也可以使用相同的选项来创建一个 Deployment 的 yaml 配置文件:
# 格式
kubectl create deployment <Deployment名称> <选项>
# 例如
kubectl create deployment deploy-test --image nginx --dry-run=client -o yaml > deploy-test.yaml
2
3
4
5
创建一个名为deploy-test的 deployment,将其配置信息导出至deploy-test.yaml文件中。
随后,我们打开这个 yaml 文件,你将看到以下内容:
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: deploy-test
name: deploy-test
spec:
replicas: 1
selector:
matchLabels:
app: deploy-test
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: deploy-test
spec:
containers:
- image: nginx
name: nginx
resources: {}
status: {}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
Deployment 的配置字段和我们之前看到的资源(例如 Pod 或 LimitRange)有一点不同:
apiVersion:Deployment 的 API 版本是固定的apps/v1kind:写的是资源名称Deploymentmetadata和其他资源一样,包含当前资源的元数据信息spec包含 Deployment 的具体配置内容
# (1)spec.replicas
需要维持的 Pod 数量(副本数),你需要几个 Pod 就写几个。
spec:
replicas: 1
2
# (2)spec.template
要创建的 Pod 模板,这部分内容和 Pod 的 yaml 配置完全一样,只不过除去了 Pod 的apiVersion和kind字段,只保留了 Pod 的元数据信息(metadata)和具体的配置项(spec)。
还有一个小细节,这个 Pod 模板没有名称(metadata.name),因为 deployment 在创建 Pod 的时候,会自动赋予它们一个随机的名称。
spec:
template:
metadata:
creationTimestamp: null
labels:
app: deploy-test
spec:
containers:
- image: nginx
name: nginx
resources: {}
2
3
4
5
6
7
8
9
10
11
# (3)spec.selector.matchLabels
由 Deployment 创建出来的 Pod 都具有相同的标签app=deploy-test,Deployment 刚好可以通过这个标签来识别和追踪这些 Pod。
- 如果 Pod 的标签和 Deployment 的追踪标签不匹配,那么 Deployment 就无法找到要维持的 Pod(相当于失去效果)
- Pod 可以同时具有多个标签,Deployment 的追踪标签只需要匹配其中的一个标签即可
spec:
selector:
matchLabels:
app: deploy-test
2
3
4
# 2.22.2 测试Deployment
1、我们以上面的 yaml 文件为基础,对其进行一点小小的修改:
- 将需要维持的 Pod 数量(
spec.replicas)修改为3个 - 为 Pod 模板(
spec.template)添加镜像下载策略IfNotPresent
# deploy-test.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: deploy-test
name: deploy-test
spec:
replicas: 3
selector:
matchLabels:
app: deploy-test
strategy: {}
template:
metadata:
creationTimestamp: null
labels:
app: deploy-test
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
resources: {}
status: {}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
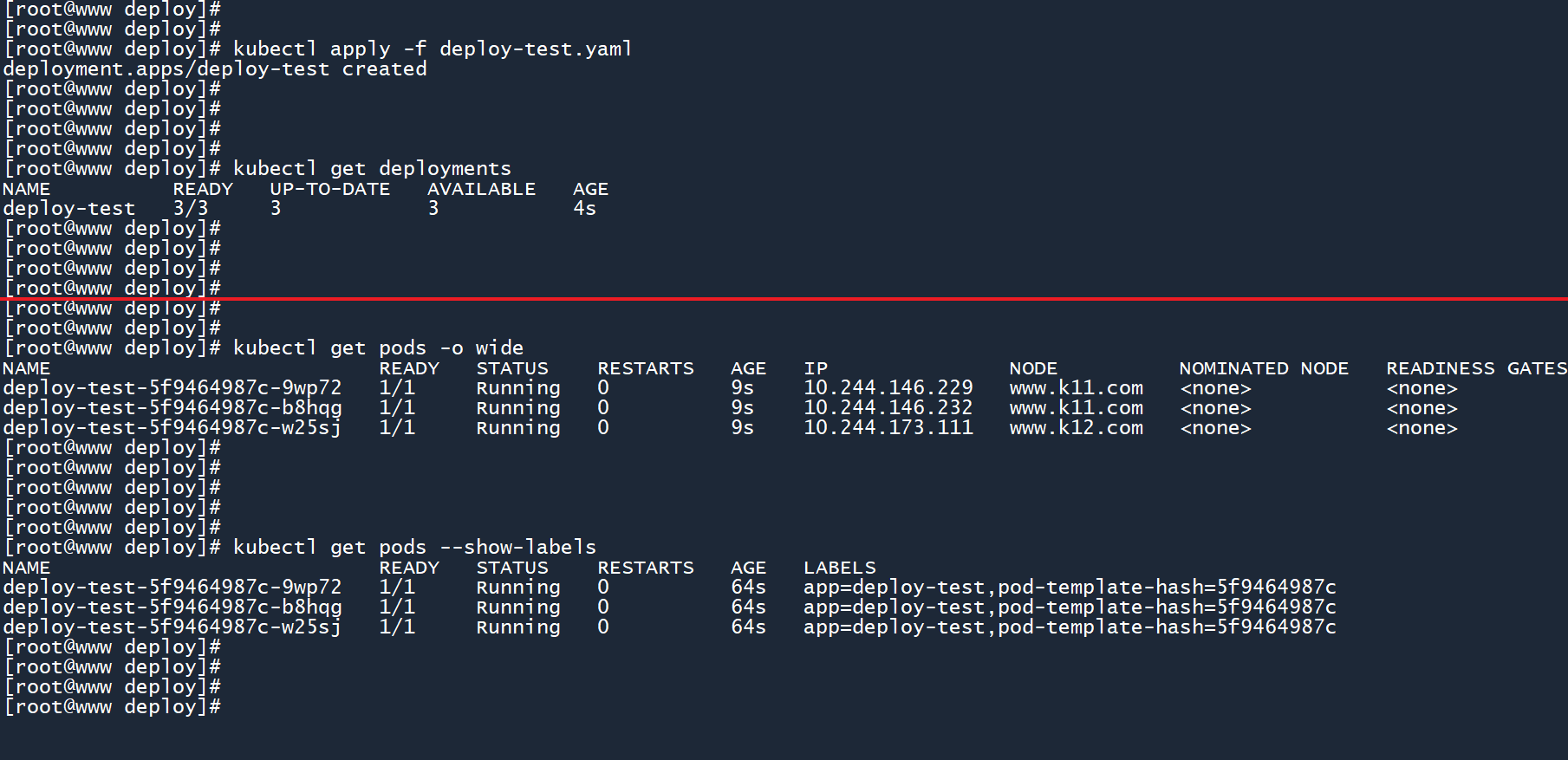
2、然后创建这个 deployment,并查看 Pod 的运行状态:
kubectl apply -f deploy-test.yaml
kubectl get deployments
kubectl get pods -o wide
kubectl get pods --show-labels
2
3
4
5
如图所示,deployment 顺利地创建出了 3 个 Pod,并且这些 Pod 都具有相同的名称格式(<控制器名称>-<模板hash>-<随机的Pod名称>),且具有相同的两个标签。
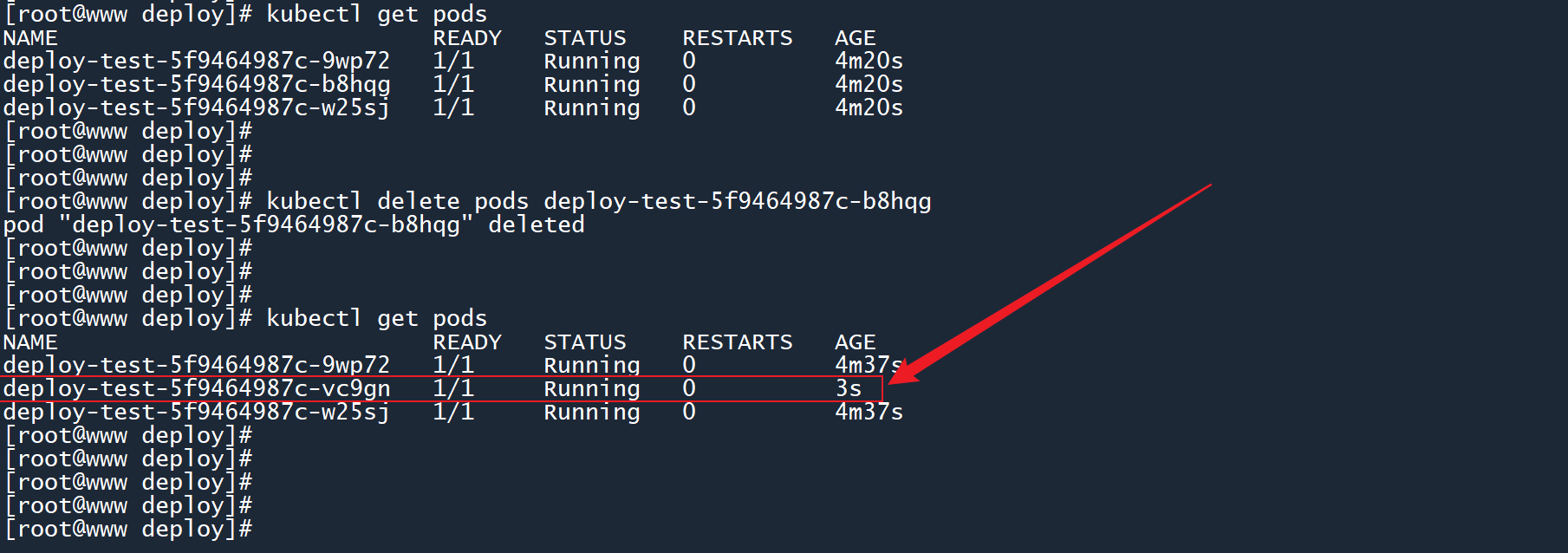
3、删除其中的某个 Pod,看看 deployment 是否会填补这个空缺。
kubectl delete pods <Pod名称>
可以看到,当我将 Pod b8hqg删除之后,deployment 立马创建了一个新的 Pod vc9gn来顶替它的位置。
(和 1.2 小节的漫画一样)
# 2.2.12.2.1 无法追踪Pod的情况
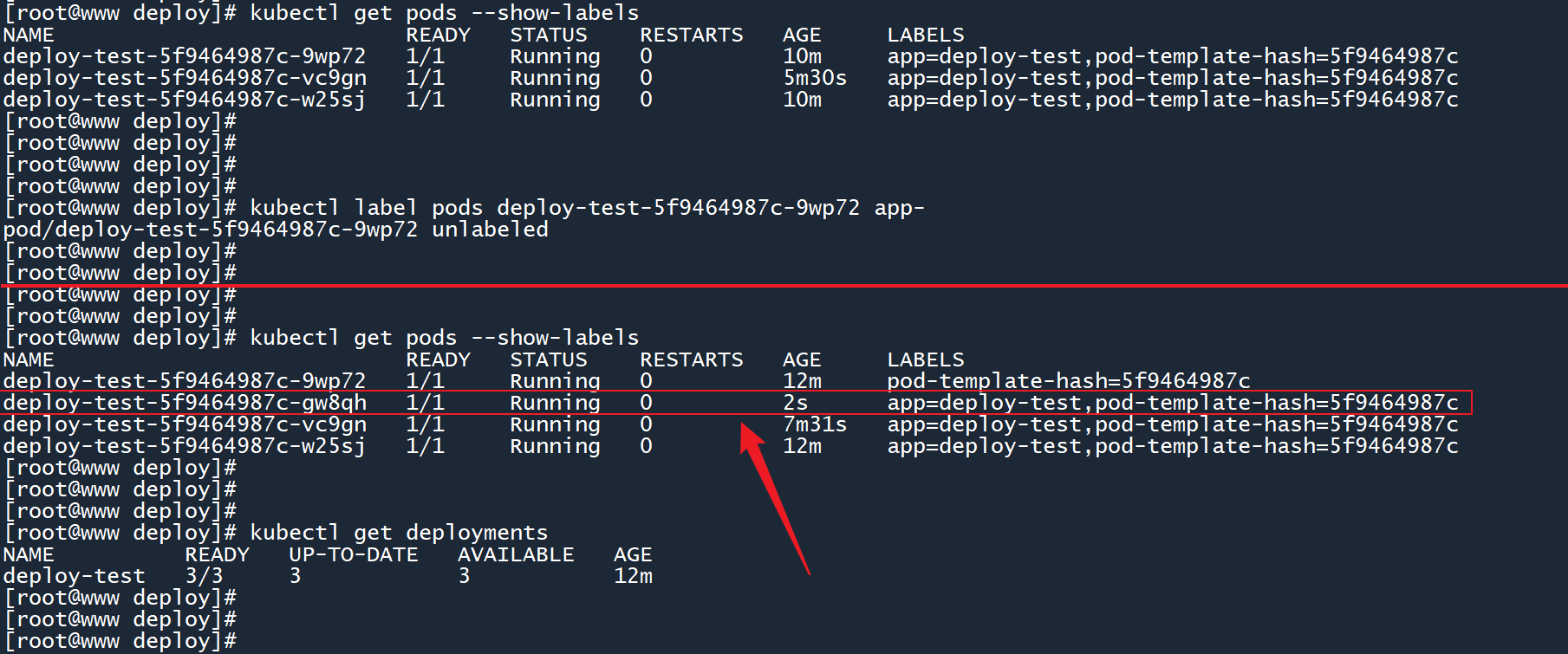
前面介绍spec.selector.matchLabels字段的时候提到过,deployment 通过标签来追踪 Pod,这样它就知道哪些 Pod 是需要它来维持的。
删除其中某个 Pod 的app标签,看看会发生什么:
# 删除某个 Pod 上名为 app 标签
kubectl label pods <Pod名称> app-
2
如图所示,当我把 Pod 9wp72上的app标签删除之后,deployment 丢失了与这个 Pod 的连接。
由于 deployment 找不到这个 Pod,因此它会认为这个 Pod 已经挂掉了,随后会创建一个新的 Pod gw8qh来顶替它的位置。
(丢失一个 Pod,需要创建另一个 Pod 来填补空缺)
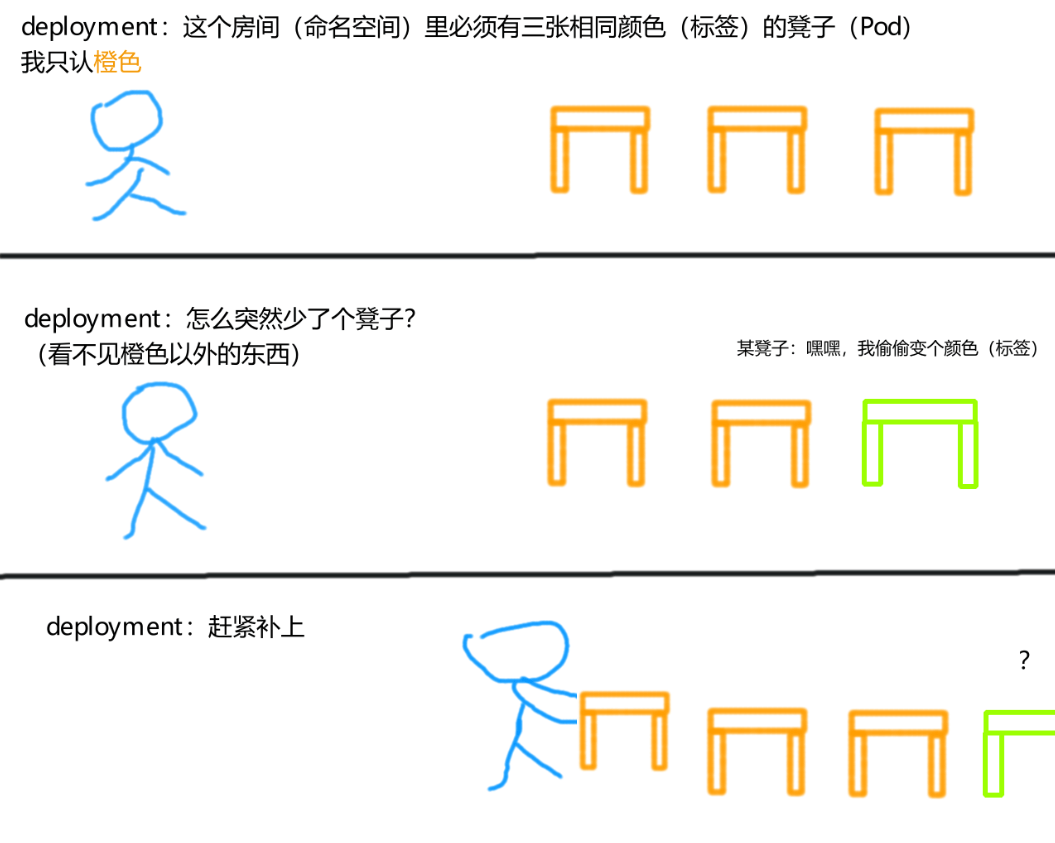
# 2.2.22.2.2 超出上限的时候
前面我们创建了一个名为deploy-test的 deployment,它通过标签app=deploy-test来追踪 Pod,并让这些 Pod 的数量始终保持在 3 个。
在上一节中,我们删除了 Pod 9wp72的app标签,导致 deployment 丢失了这个 Pod,并另外生成了一个新的 Pod。
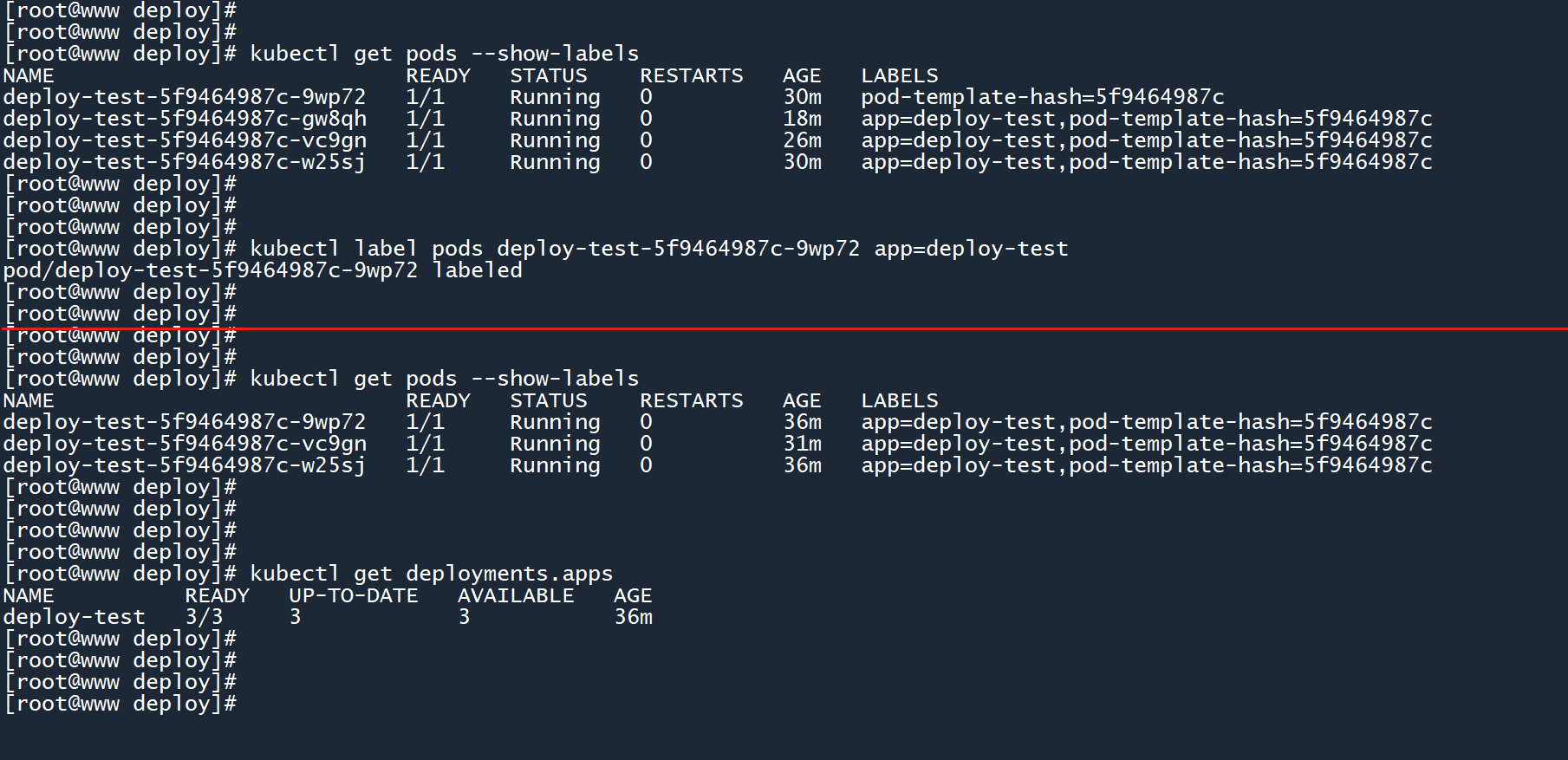
我们帮这个 Pod 把标签加回去,这样一来 deployment 就会得到 4 个 Pod:
kubectl label pods <Pod名称> app=deploy-test
如图所示,当 Pod 9wp72回归这个大家庭后,就会超出 deployment 所维持的 Pod 数量上限,这时它将会删除其中的某个 Pod,将 Pod 数量缩减为 3 个。
(突然多出一个 Pod,需要将 Pod 数量缩减为三个)
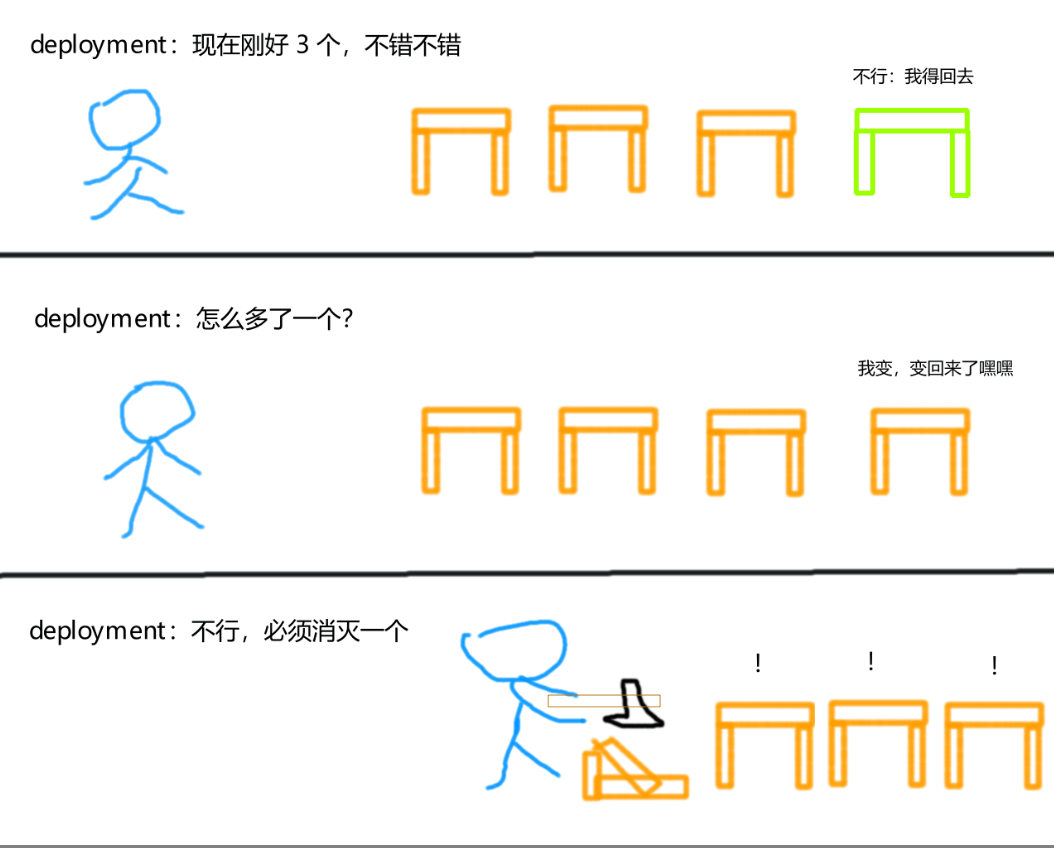
另外,你也可以单独创建一个 Pod,并为其设置标签app=deploy-test,这同样会超出数量上限,并产生相同的缩减效应。
# 2.42.4 删除deployment
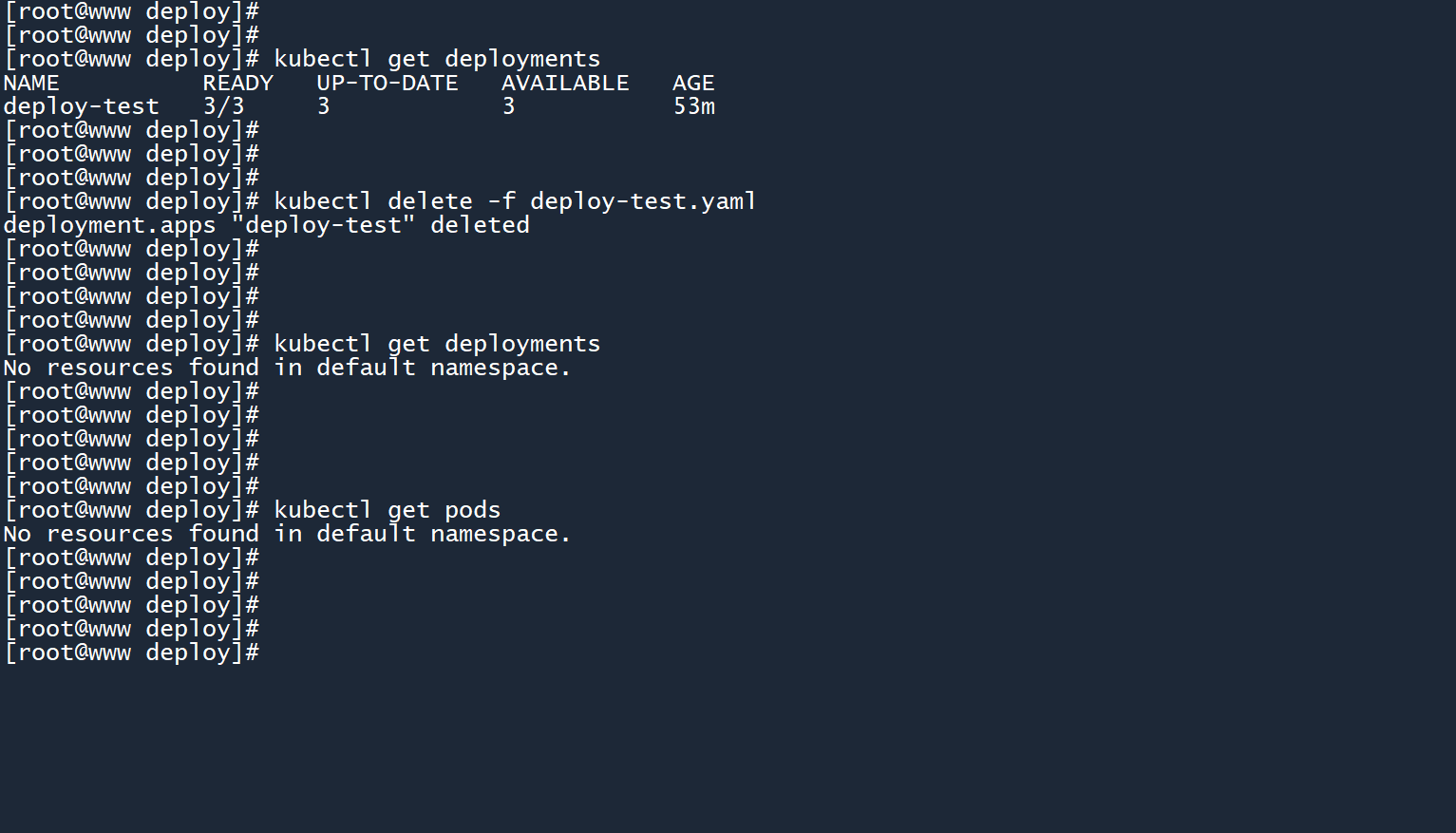
和其他的资源一样,有两种删除 Deployment 的方式:
# 通过名称删除 Deployment
kubectl delete deployments <资源名称>
# 通过原始文件删除 Deployment
kubectl delete -f <文件名称>
2
3
4
5
这里我以文件的方式,删除刚刚创建出来的deploy-test:
kubectl delete -f deploy-test.yaml
删除控制器之后,由该控制器创建出来的 Pod 也会一并被删除。
# 33. 修改deployment副本数
由控制器维持的 Pod 数量上限,也被称为 Pod 的 “副本数”。
在创建 deployment 的时候,我们可以通过修改spec.replicas字段来控制所产生的副本数。但当 deployment 被创建出来之后,我们如何修改这个数量呢?
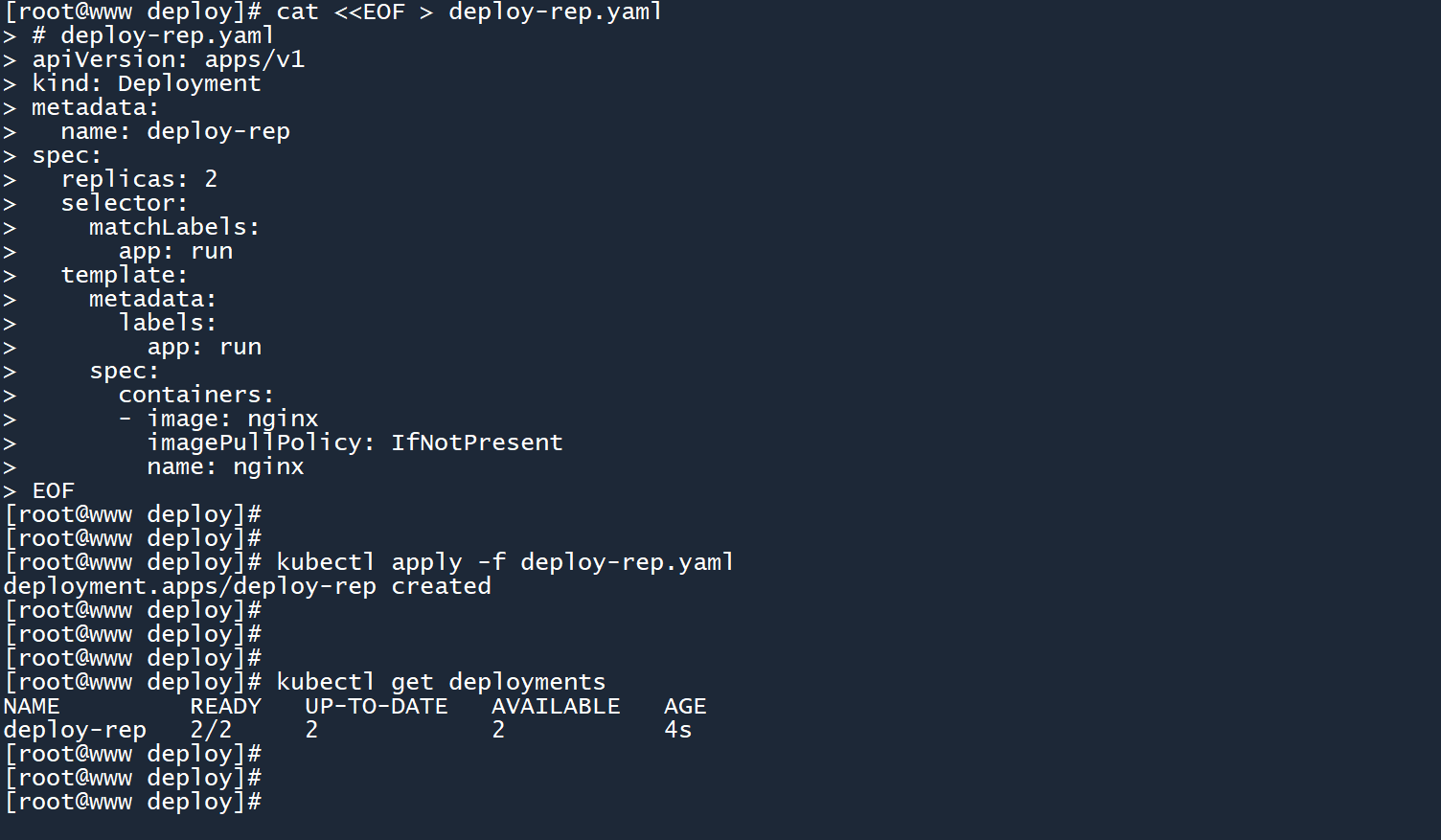
在这之前,我们先创建一个用于实验的新 deployment:
# deploy-rep.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-rep
spec:
replicas: 2
selector:
matchLabels:
app: run
template:
metadata:
labels:
app: run
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: nginx
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
这个 deployment 的初始副本数被设置为2个。
# 创建控制器
kubectl apply -f deploy-rep.yaml
kubectl get deployments
2
3
# 3.13.1 通过命令行修改副本数
这是最简单的一种修改方式,通过使用kubectl scale命令以及--replicas选项,即可轻松修改一个 deployment 的副本数。
kubectl scale deployments <名称> --replicas=<新的副本数>
1、刚刚创建出来的 deployment 副本数为2个,最近双十一要到来了,两个 Pod 可能顶不住那么大的流量,我们将其副本数扩展为5个:
kubectl scale deployment deploy-rep --replicas=5
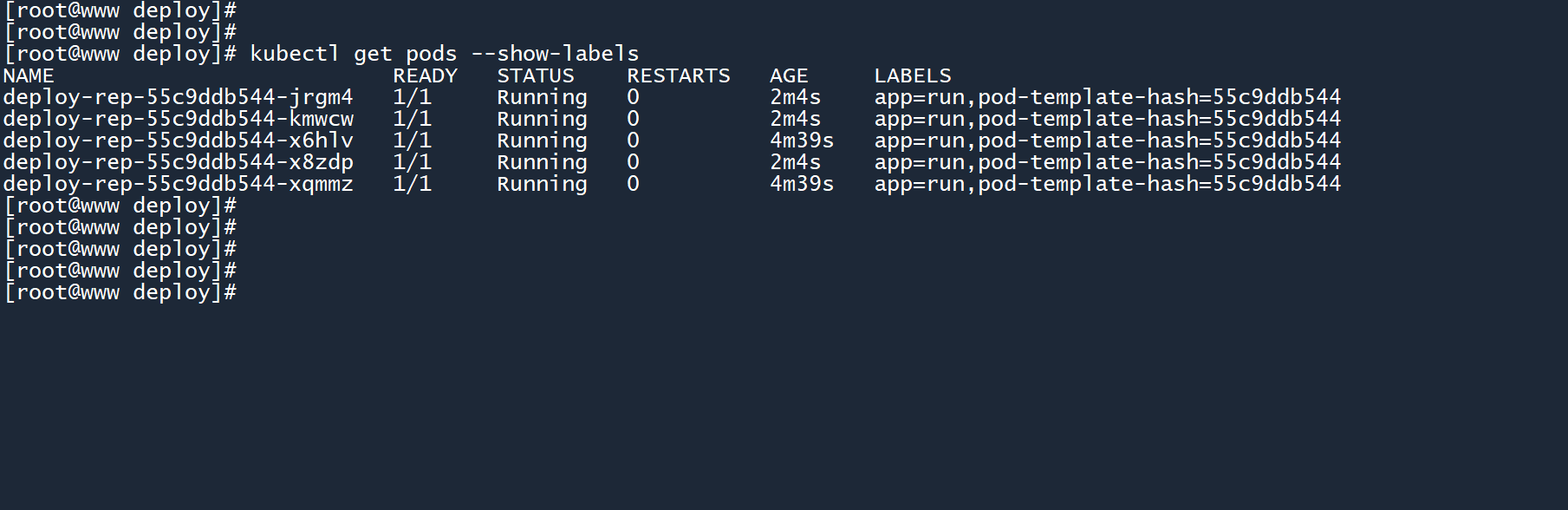
2、如图所示,当扩展副本数为5个时,由于当前只有2个 Pod,所以 deployment 会依次创建三个新的 Pod,以填补这些位置的空缺。
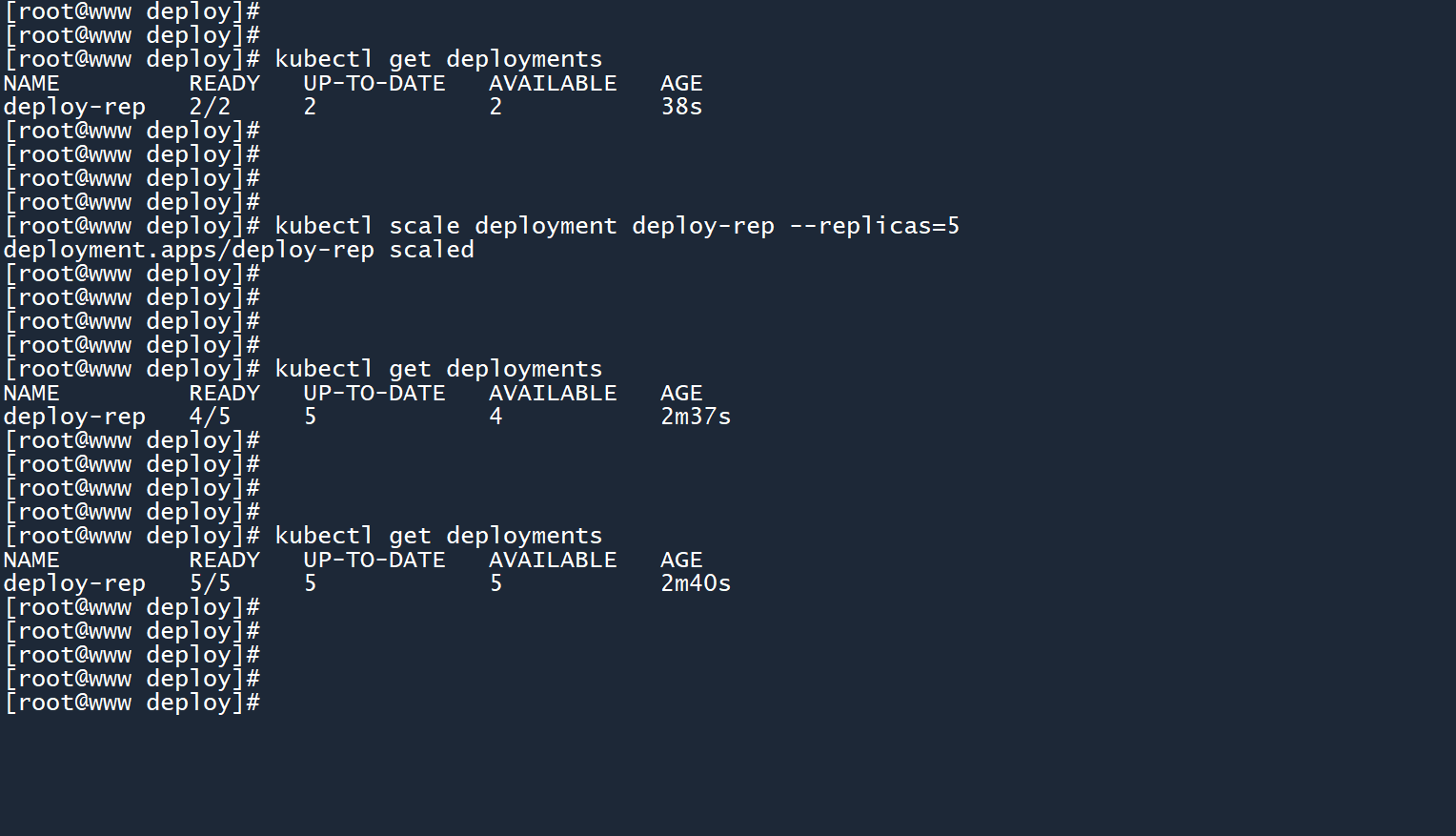
3、可以看到,有两个 Pod 的运行时间比较长(4m39s),它们就是最初的那两个 Pod。而新创建出来的三个 Pod 运行时间比较短(2m4s)。
# 3.23.2 应用新的yaml配置
和其他资源(例如 Pod)一样,我们可以修改原始 yaml 配置文件,然后将新的配置应用到正在运行的资源上。
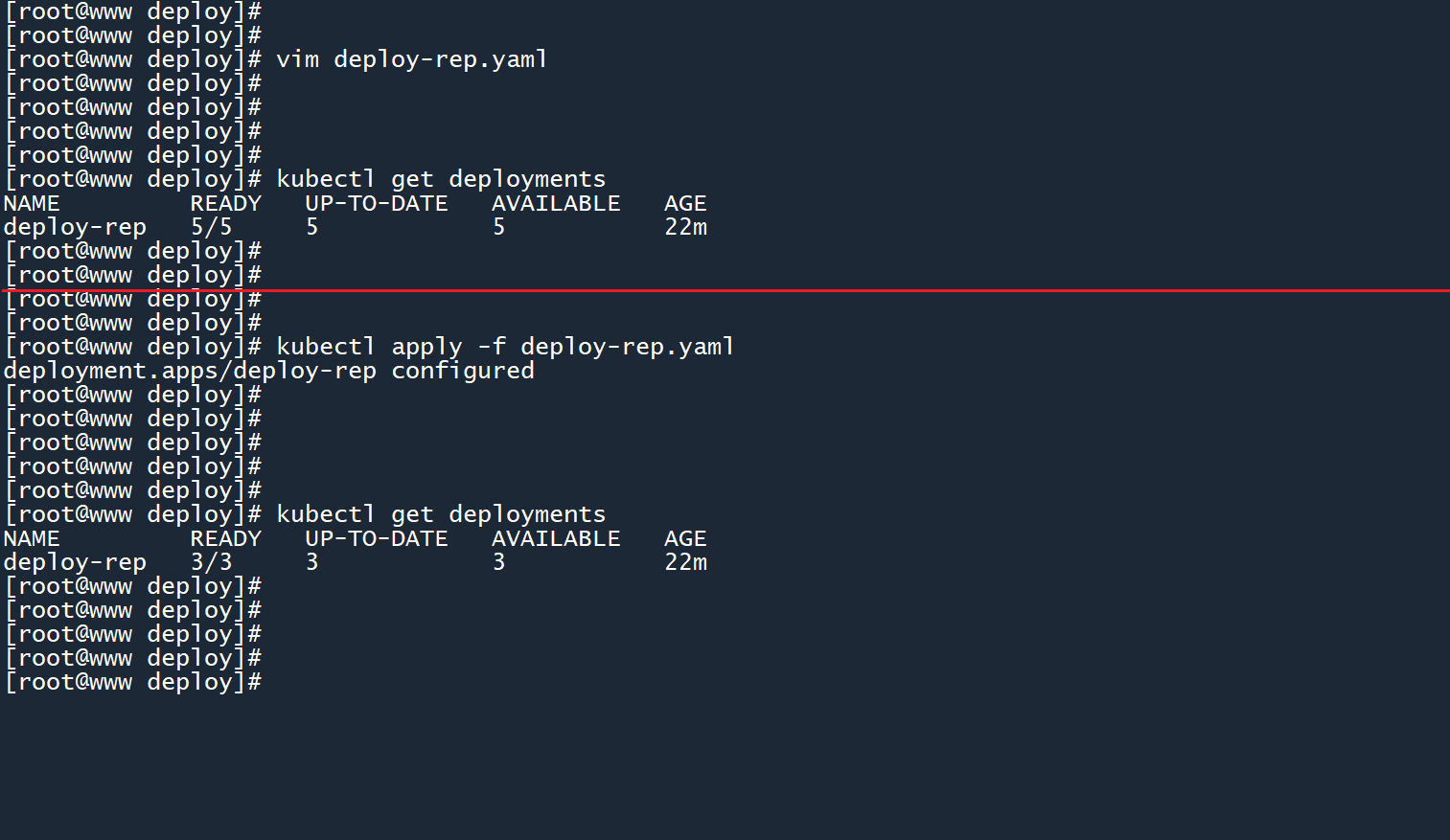
双十一过完了,系统不再需要那么多的 Pod 了,于是打开这个 deployment 的原始配置文件,将副本数修改为3个:
vim deploy-rep.yaml

然后应用修改过后的配置:
kubectl apply -f deploy-rep.yaml
如果资源不存在,则kubectl apply会创建该资源。
如果资源已经存在,则kubectl apply会根据 yaml 文件中的配置项,更新当前资源的对应信息。
# 3.33.3 编辑deployment运行属性
k8s 允许你编辑某个正在运行的资源,你对其的修改会实时应用到当前资源中。
kubectl edit deployment <名称>
1、例如,我们可以对deploy-rep进行编辑:
kubectl edit deployment deploy-rep
执行命令之后,你就会进入配置视图,当前资源的所有配置信息都会以 yaml 的格式向你展现。你可以修改其中的某些字段,当你保存退出之后,所做更改会自动应用到当前的资源中。
这有点像编辑原始 yaml 文件,然后通过apply更新配置。而edit简化了这个过程。
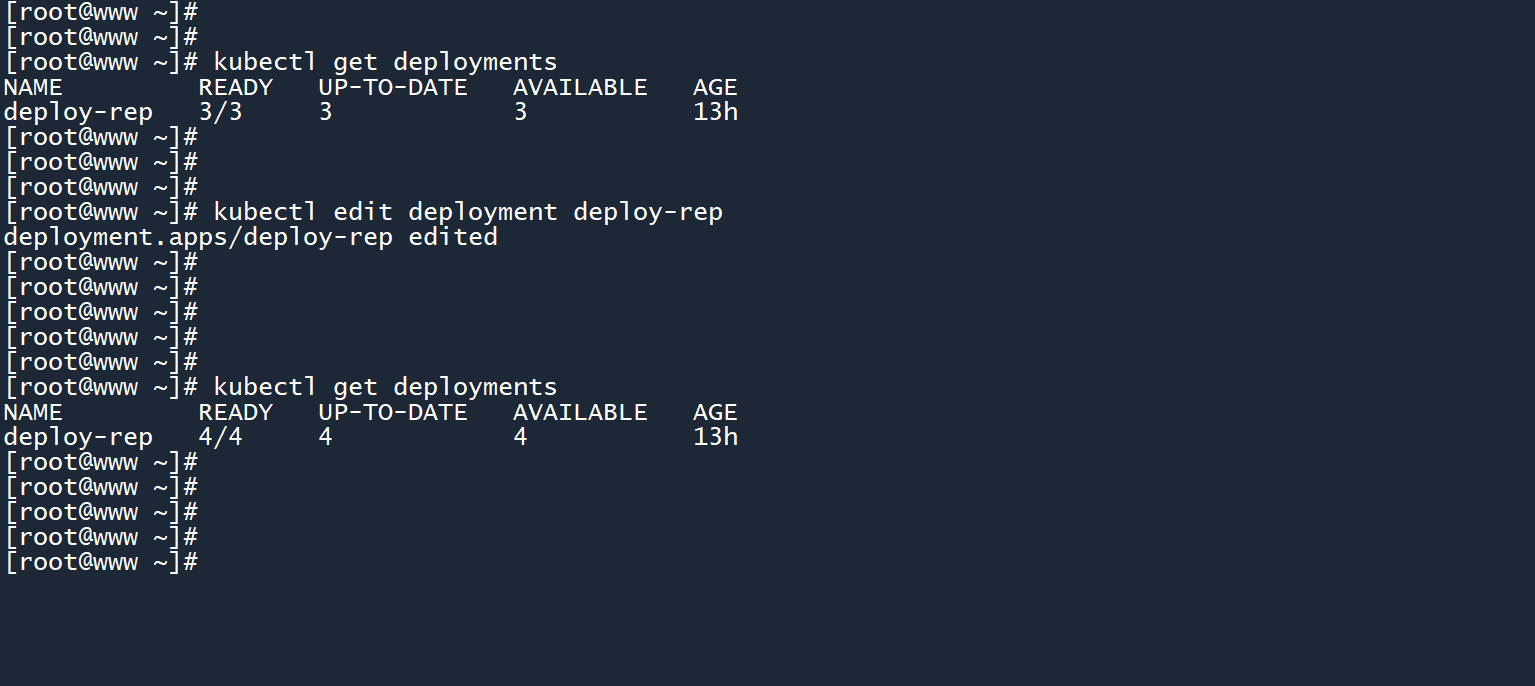
2、在配置视图中找到spec.replicas字段,将其修改为4,然后像使用 vim 一样保存退出。
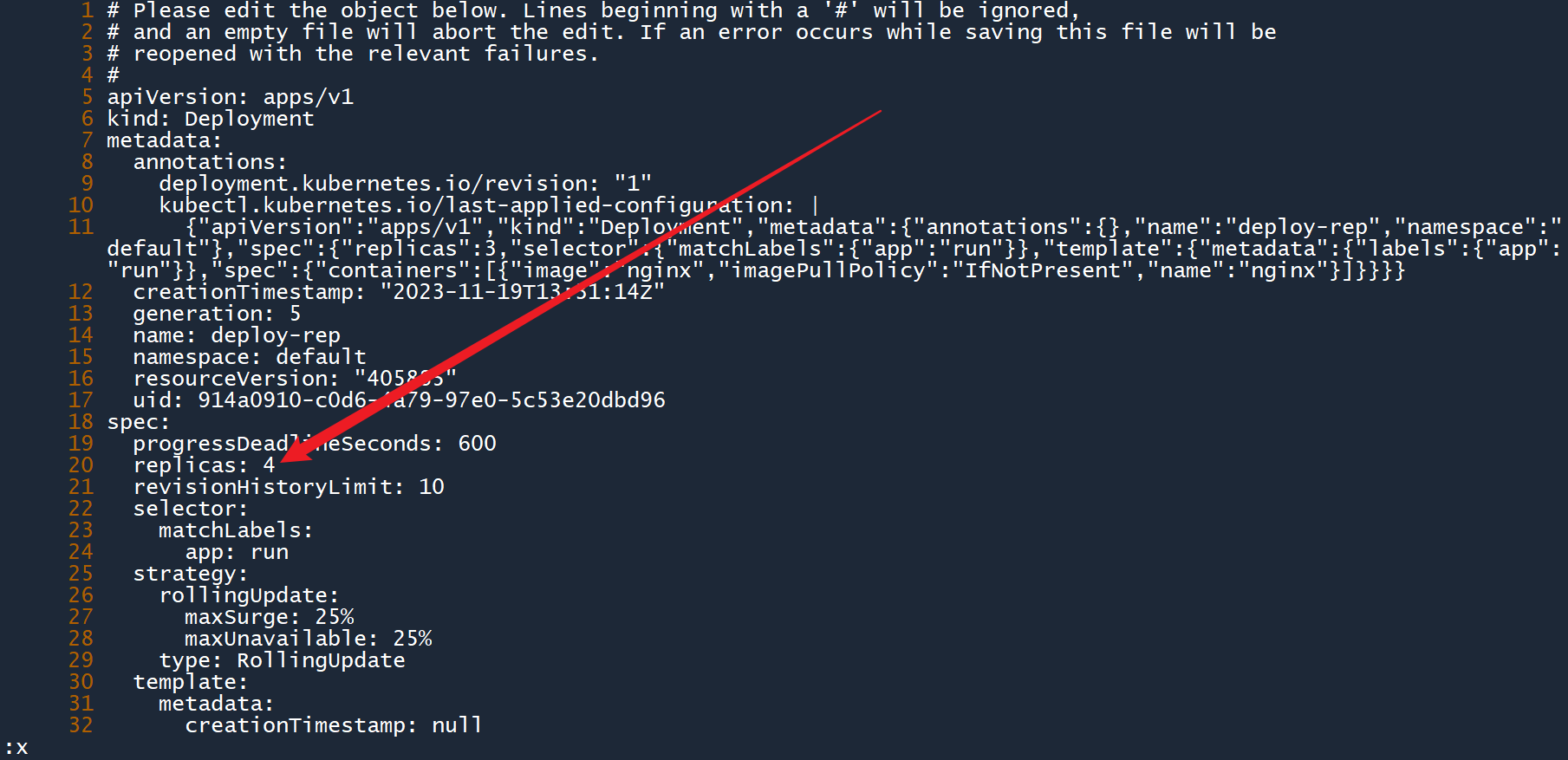
3、如图所示,成功通过edit将副本数修改为了4。
# 44. 水平自动扩缩HPA
在上一节中,我们介绍了三种修改 deployment 副本数的方式。但是这种修改方式也存在缺点:
- 当业务量大的时候(例如遇到了双十一),管理员需要手动将副本数调高
- 当业务量小的时候,管理员又需要手动将副本数调低
这是一个繁琐的修改过程。有没有一种方法,可以根据 Pod 的负载情况,自动扩展或缩减 Pod 数量呢?
这时候就要用到 HPA(水平自动扩缩)了,它又被称为 “水平自动更新”。
# 4.14.1 根据CPU负载情况自动扩缩
HPA 可以根据每个 Pod 的负载情况(CPU 使用率或内存使用率),自动对 Deployment 的副本数进行扩展或缩减。
# 为 Deployment 设置 HPA 策略
kubectl autoscale deployment <目标控制器名称> --min=<最小Pod数> --max=<最大Pod数> --cpu-percent=<CPU百分比>
2
# 4.1.14.1.1 配置HPA
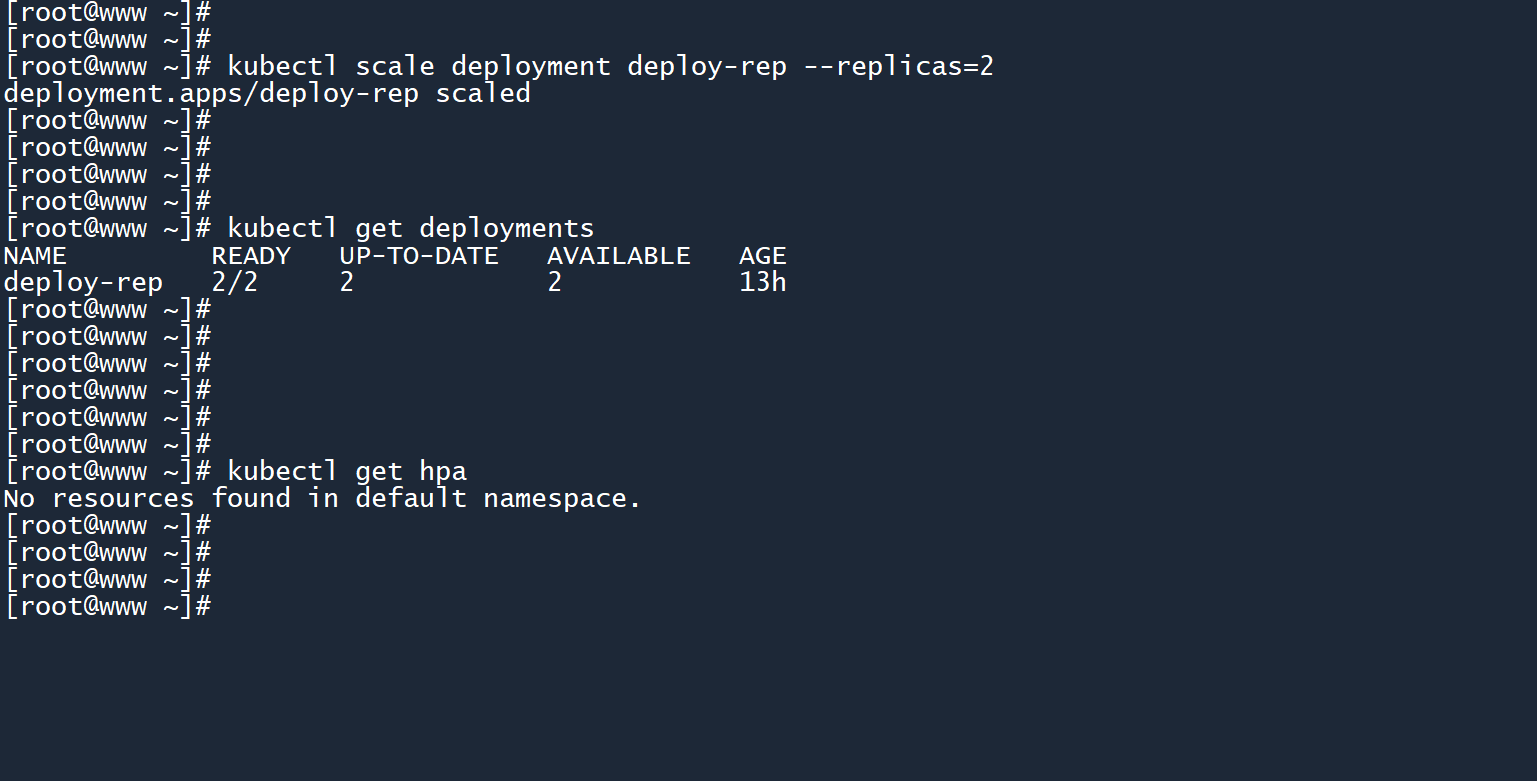
1、我们先把之前那个 deployment 的副本数设置为2个,然后查看当前是否有 HPA。
# 修改副本数
kubectl scale deployment deploy-rep --replicas=2
kubectl get deployments
# 列出 HPA
kubectl get hpa
2
3
4
5
6
可以看到,当前命名空间中没有 HPA。
2、为deploy-rep创建一个 HPA 策略,这个 HPA 没有名称,且会自动绑定到所提供的 deployment 上。
--min=2:这个 deployment 的副本数最少为2个--max=7:这个 deployment 的副本数最多为7个--cpu-percent=60:确保其中每个 Pod 的 CPU 使用率保持在60%以下
kubectl autoscale deployment deploy-rep --min=2 --max=7 --cpu-percent=60
例如,当前的 CPU 负载量为 90%,那么这两个 Pod 就会各自分担 45%。
这个 HPA 会确保这些 Pod 的平均负载保持在 60% 以下,平均负载超过了 60%,那么 HPA 就会创建更多的 Pod 来分担负载量。
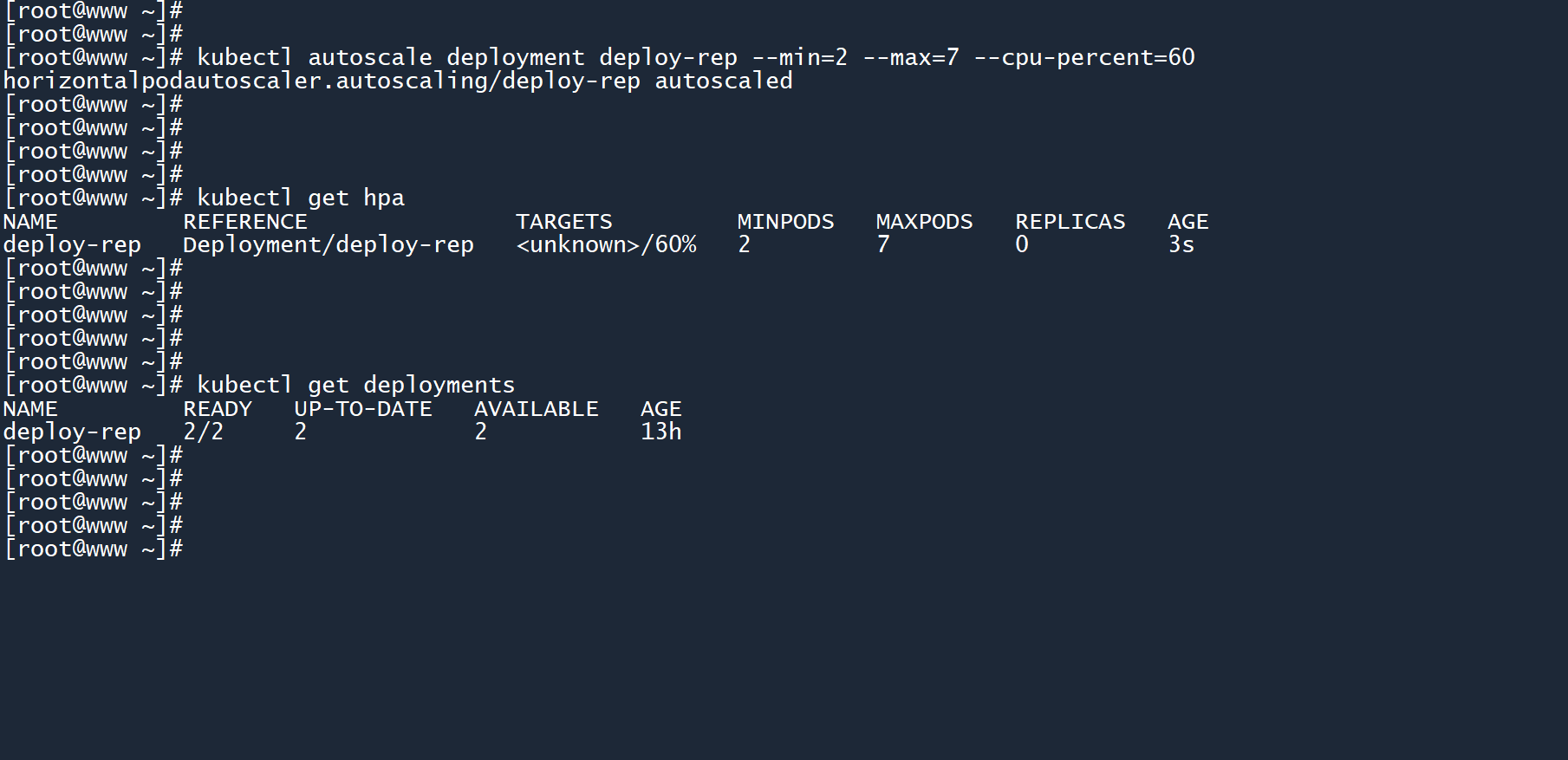
此时,这个 HPA 的计量指标为<unknown>/60%,为什么这里显示的是unknown(未知)呢?这其中肯定存在问题。
# 4.1.24.1.2 为控制器中的Pod配置资源限制
并不是创建 HPA 之后就万事大吉了,我们还需要为 deployment 所控制的 Pod 配置资源限制。
我们刚刚通过选项--cpu-percent=60将扩展触发量定为了 60%,那么这个百分比计算的是哪个数值呢?这个数值和 Pod 的资源限制字段spec.containers.resources有关。例如,考虑一个这样的 Pod:
...
spec:
containers:
resources:
limits:
cpu: 400m
2
3
4
5
6
在这个 Pod 当中,其 CPU 资源使用上限被设置成了400个 CPU 微核心。那么对于 HPA 来说,60% 的资源就相当于400 * 0.6 = 240个 CPU 微核心。
也就是说,当这些 Pod 的平均 CPU 负载超过了240m的时候,HPA 就会通知 Deployment 扩展副本数,创建更多的 Pod 来分担业务量,将这些 Pod 的平均 CPU 负载降低至240m以下。
1、通过edit命令编辑刚刚的 deployment,打开配置视图后,找到 Pod 模板的所在位置(spec.template):
kubectl edit deployment deploy-rep
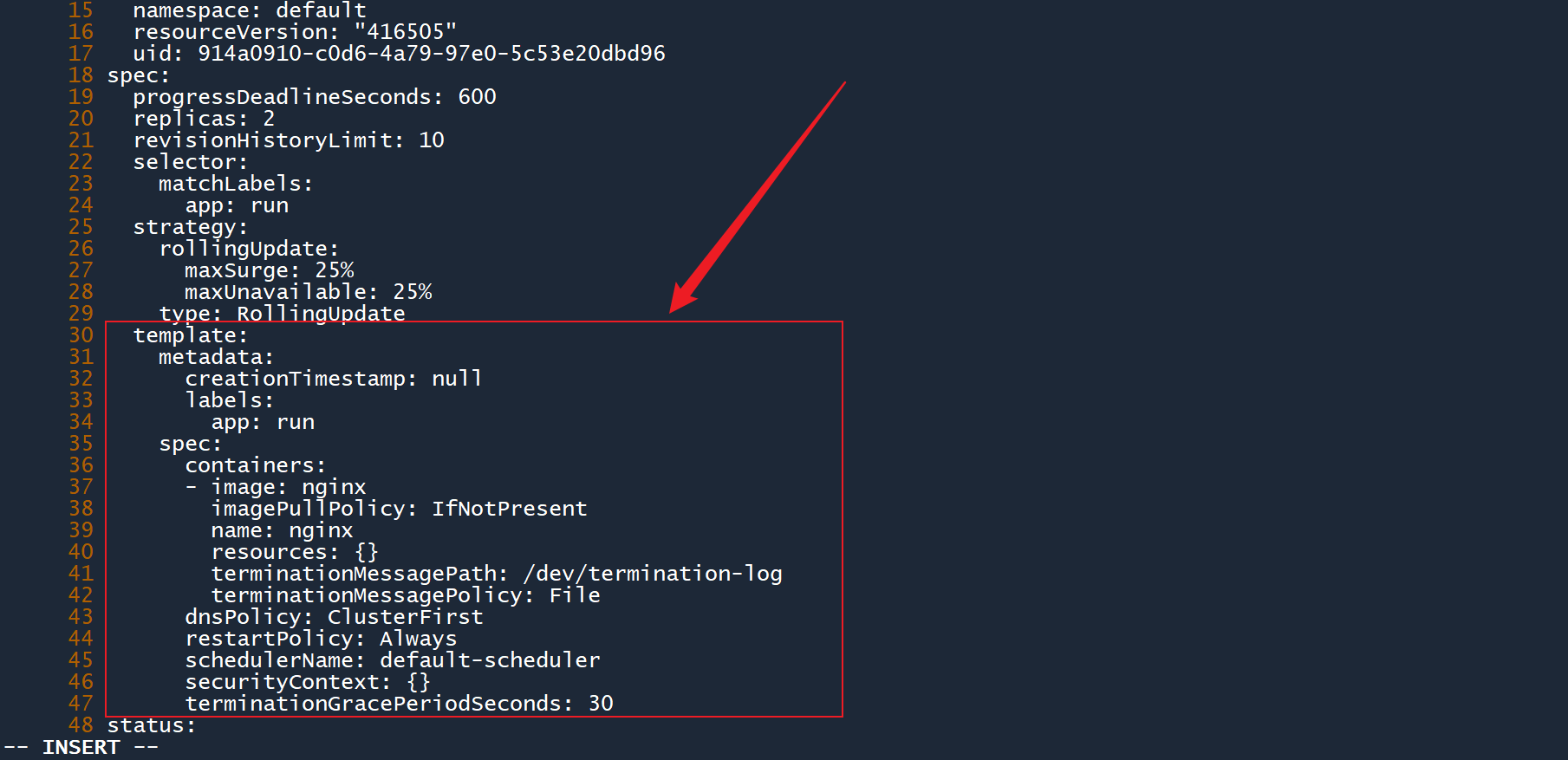
2、为 Pod 模板添加资源限制,将 CPU 使用上限设置为400m,然后保存退出:
...
resources:
limits:
cpu: 400m
2
3
4
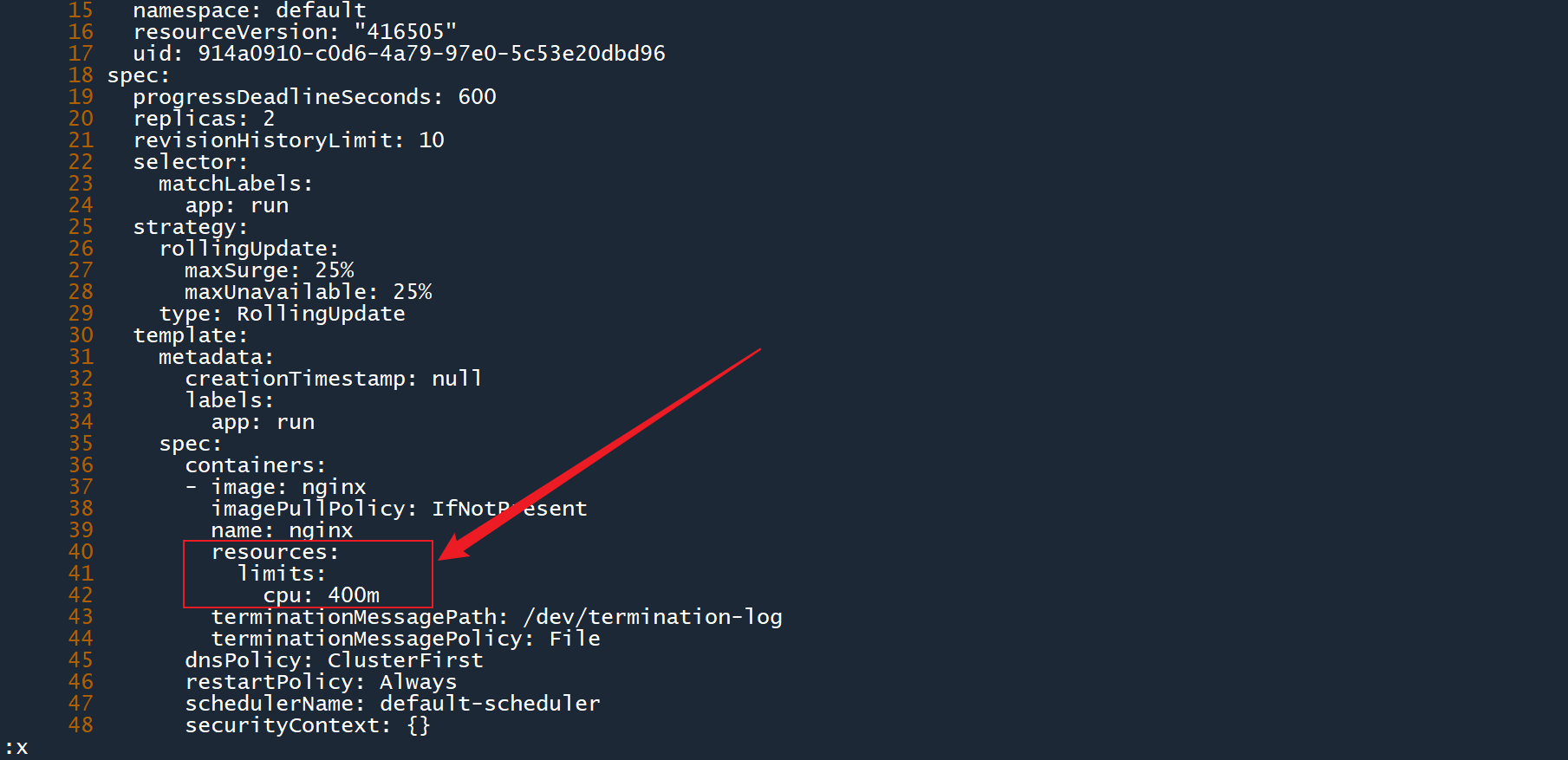
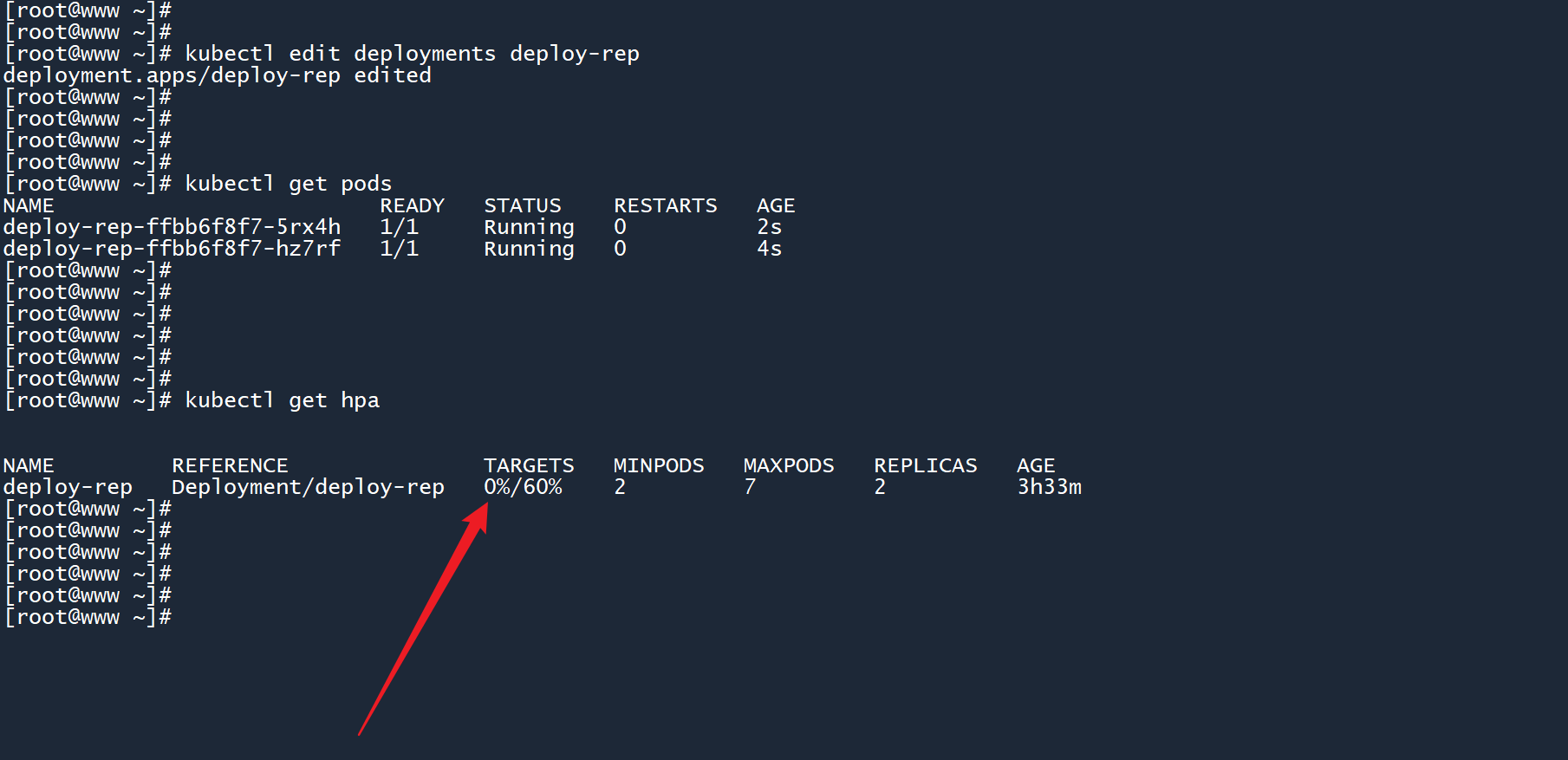
3、可以看到,当你修改了 Pod 模板之后,deployment 会删除之前的 Pod,并根据新的模板重新创建 Pod。
而且 HPA 的计量从之前的unknown(未知)变为了0%,说明它现在已经能够正确监测负载信息了。
# 4.1.34.1.3 测试HPA
1、为了测试这个 deployment 的可扩展性,我们需要执行以下命令:
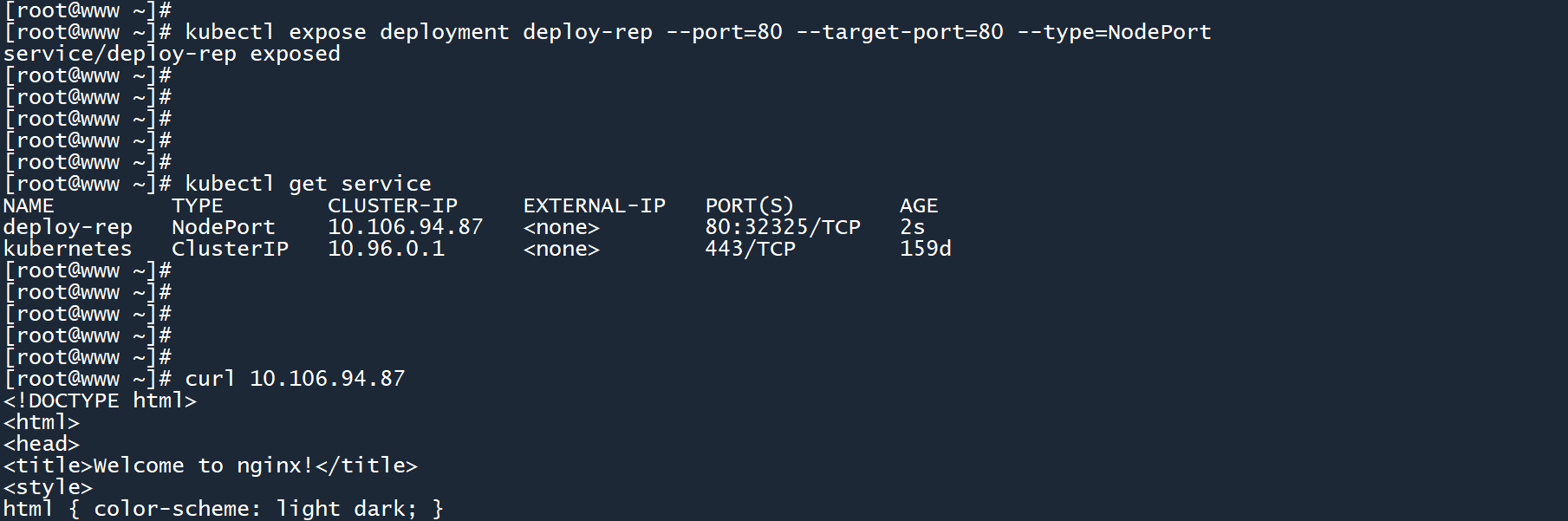
kubectl expose deployment deploy-rep --port=80 --target-port=80 --type=NodePort
该命令会为 deployment 创建一个网络服务,并为其分配一个 IP 地址(在这里为10.106.94.87)。deployment 在这里面充当了一个负载均衡器的角色,当你不断请求这个 IP 地址时,你的请求会被依次转发到 deployment 所控制的每个 Pod 中。
你暂时不需要了解这其中的参数原理,这将在后面的章节中介绍,你只需要简单地执行这条命令即可。
2、切换至任意工作节点,在主机上安装网络压力测试工具:
# worker
yum install httpd-tools -y
2
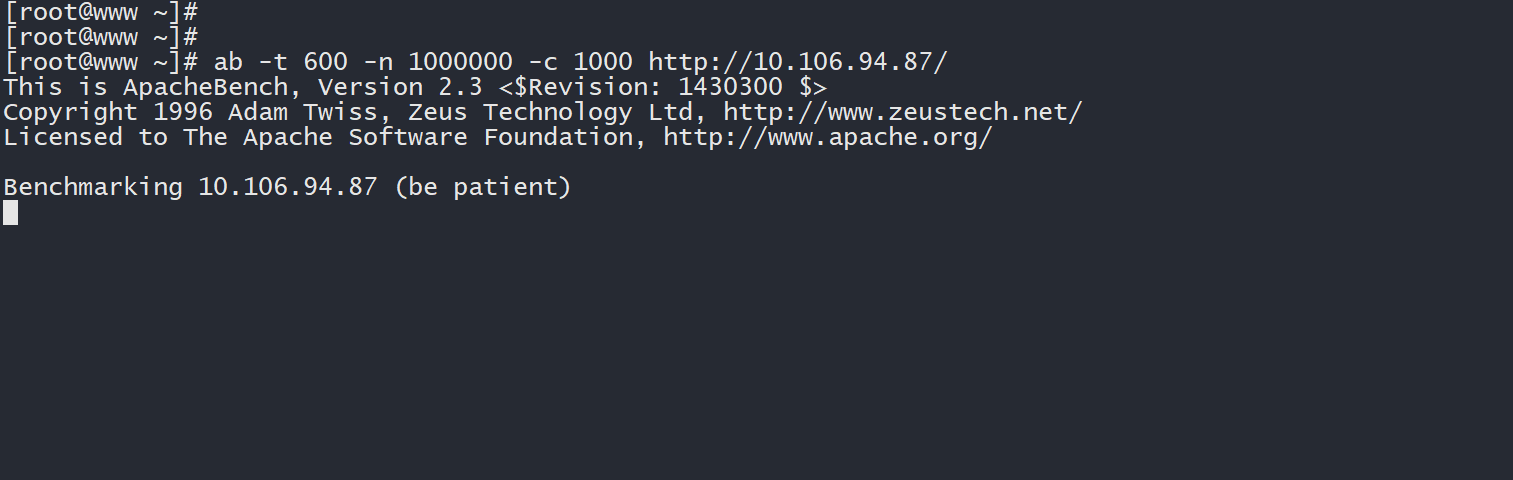
3、在安装了压力测试工具的主机上,对目标 deployment 发起大量网络请求,迫使其负载增加:
ab -t 600 -n 1000000 -c 1000 http://<目标IP地址>/
# 例如
ab -t 600 -n 1000000 -c 1000 http://10.106.94.87/
2
3
4
4、回到 master 主机上,不断查看 Pod 负载信息以及 HPA 的情况:
kubectl top pods ; echo ; kubectl get hpa
此时压力测试刚刚开始,两个 Pod 应付起来还能游刃有余。
Pod 限制 CPU 资源使用上限为400m,HPA 保持 CPU 利用率为60%,所以阈值为400m * 60% = 240m。
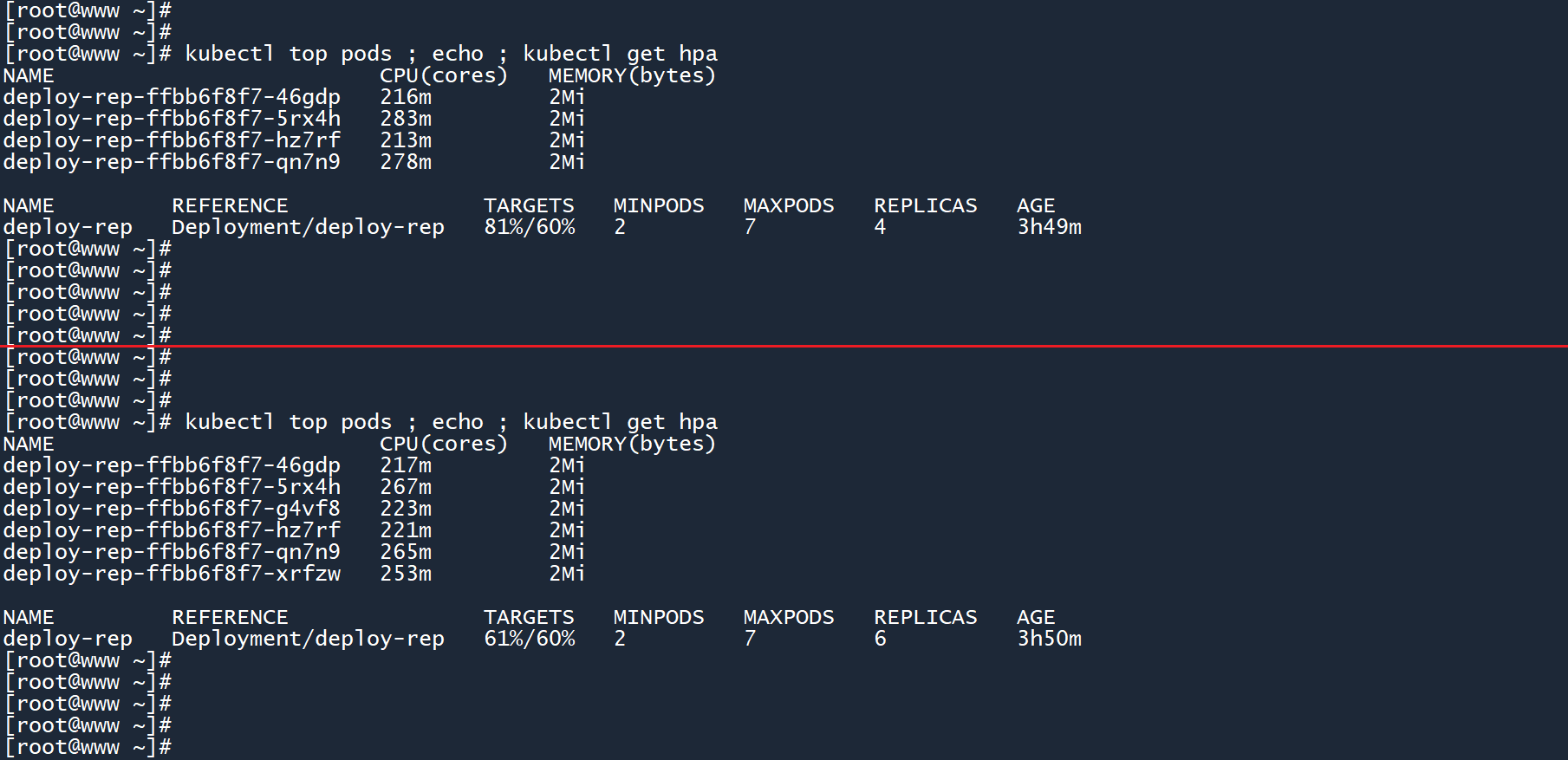
此时,这两个 Pod 的平均 CPU 负载都已经超过了阈值240m,因此 HPA 需要做出反应。

稍后,HPA 将 deployment 的副本数扩展为了4个,此时有四个 Pod 分担业务流量,平均 CPU 负载为81%。
还是超过了 HPA 所设定的阈值,四个 Pod 不够!

HPA 也意识到了这个问题,所以继续将副本数扩展至6个,用更多的 Pod 来分担业务流量。
此时平均 CPU 负载为61%,HPA 还会继续扩展吗?
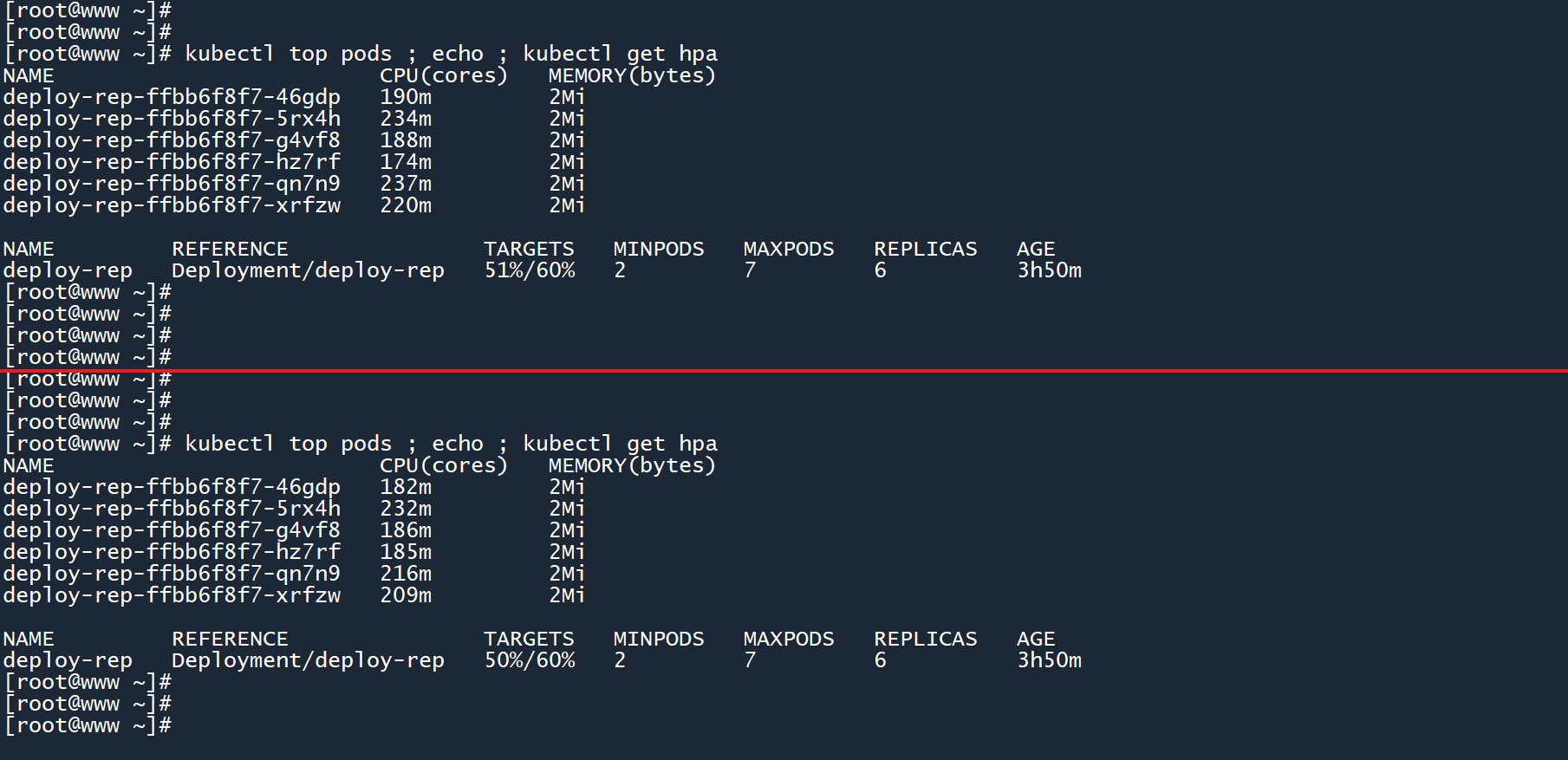
等待一会之后,平均 CPU 负载下降到了51%。从 Pod 负载信息中也可以看出,现在这六个 Pod 的 CPU 负载都位于240m以下,并没有超过阈值。
HPA 并不会一股脑地增加 Pod 数量,而是循序渐进,并观察是否符合预期要求。在确认 CPU 平均利用率稳定下来之后,HPA 便不会再扩展副本数。
过了一会之后,另一台主机上的压力测试工具也运行完毕了(你也可以Ctrl+C提前终止运行)。
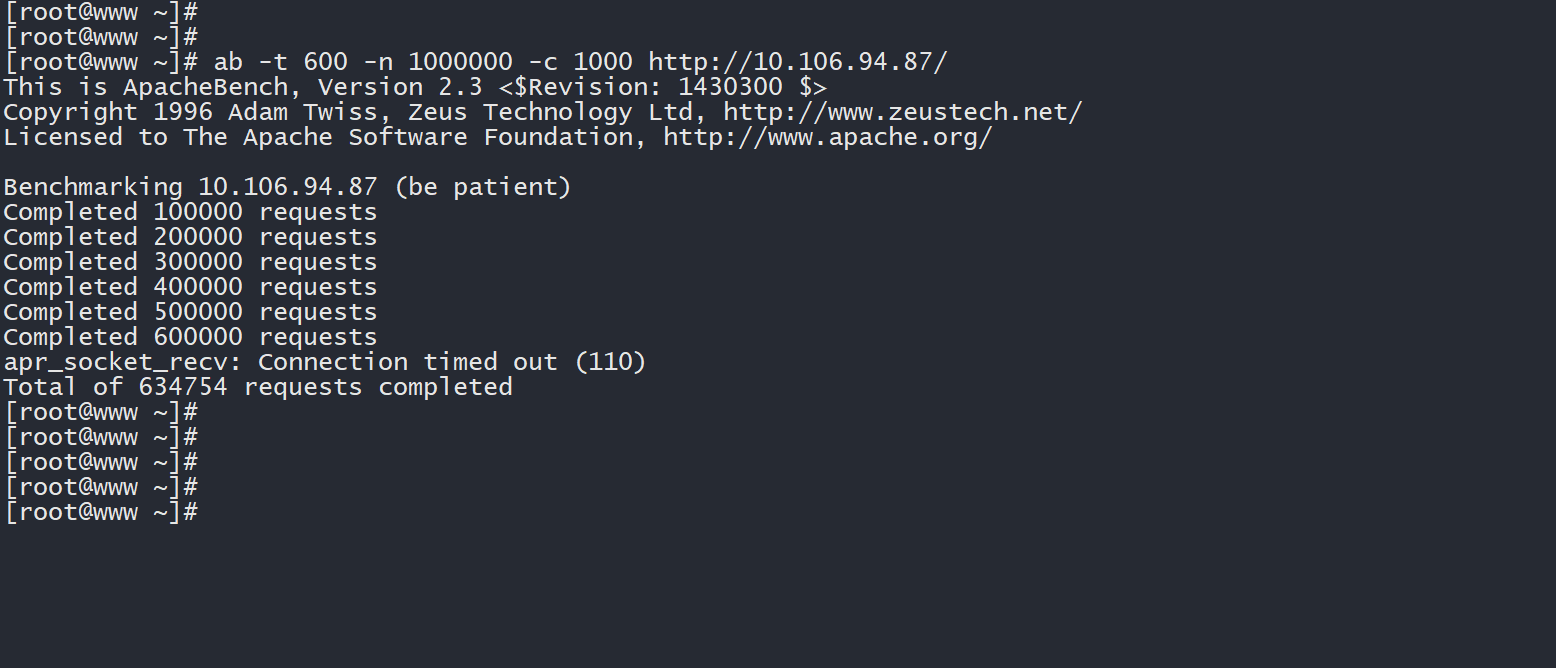
5、在压力测试工具停止以后,再次查看 Pod 以及 HPA 信息:
kubectl top pods ; echo ; kubectl get hpa
此时平均 CPU 使用率已经降低至0%,而且所有 Pod 的 CPU 负载也都处于0m,说明没有业务流量需要处理。
但 Pod 数量始终保持在6个,难道 HPA 只会扩不会缩?
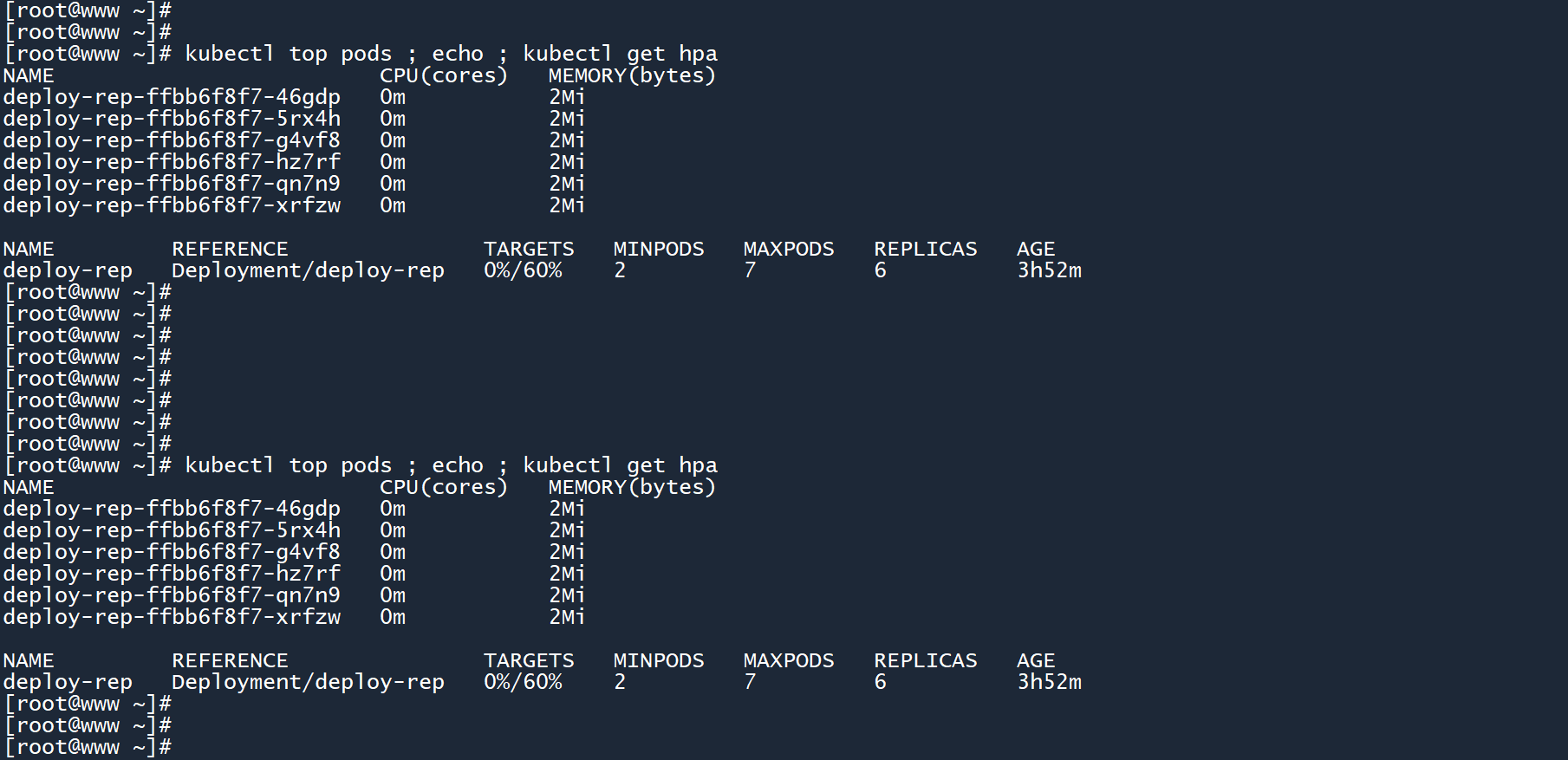
其实这是 HPA 的一种防抖机制。
笔记
当平均负载超过阈值,HPA 会迅速扩展副本数,以应对即将到来的业务量。
当平均负载低于阈值时,HPA 会等待一段时间(默认5分钟),确认平均负载不会再次升高以后,才会缩减副本数。这可以有效地防止 Pod 数量抖动。
仔细想想,如果负载量一时高一时低,变来变去。而 Pod 一会被创建出来,没几秒又被删除,等会又被创建出来,又被删除......
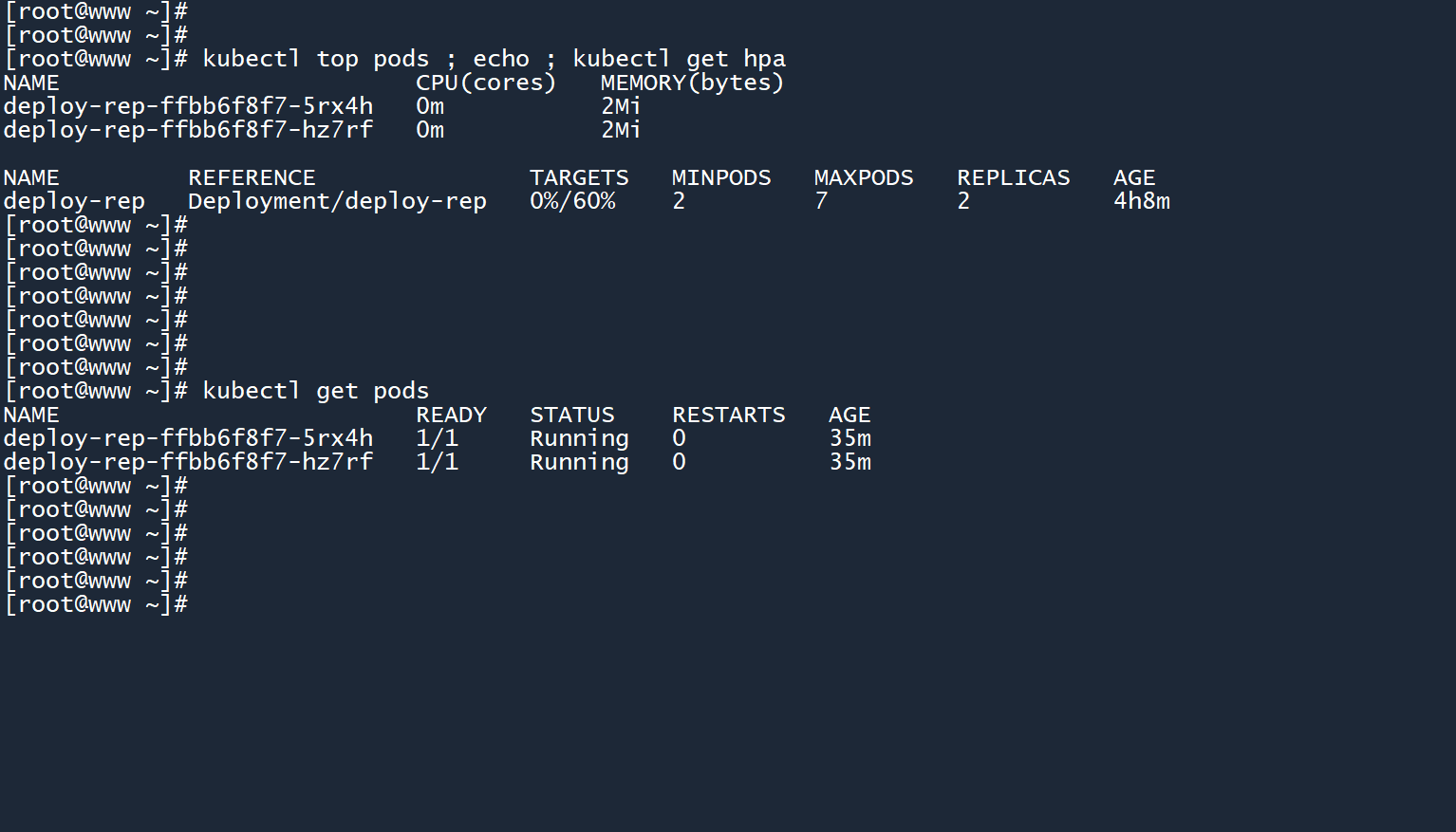
6、等待一段时间之后,再次查看 Pod 以及 HPA 信息:
kubectl top pods ; echo ; kubectl get hpa
HPA 确认业务量稳定之后,已经将副本数缩减为了2个。
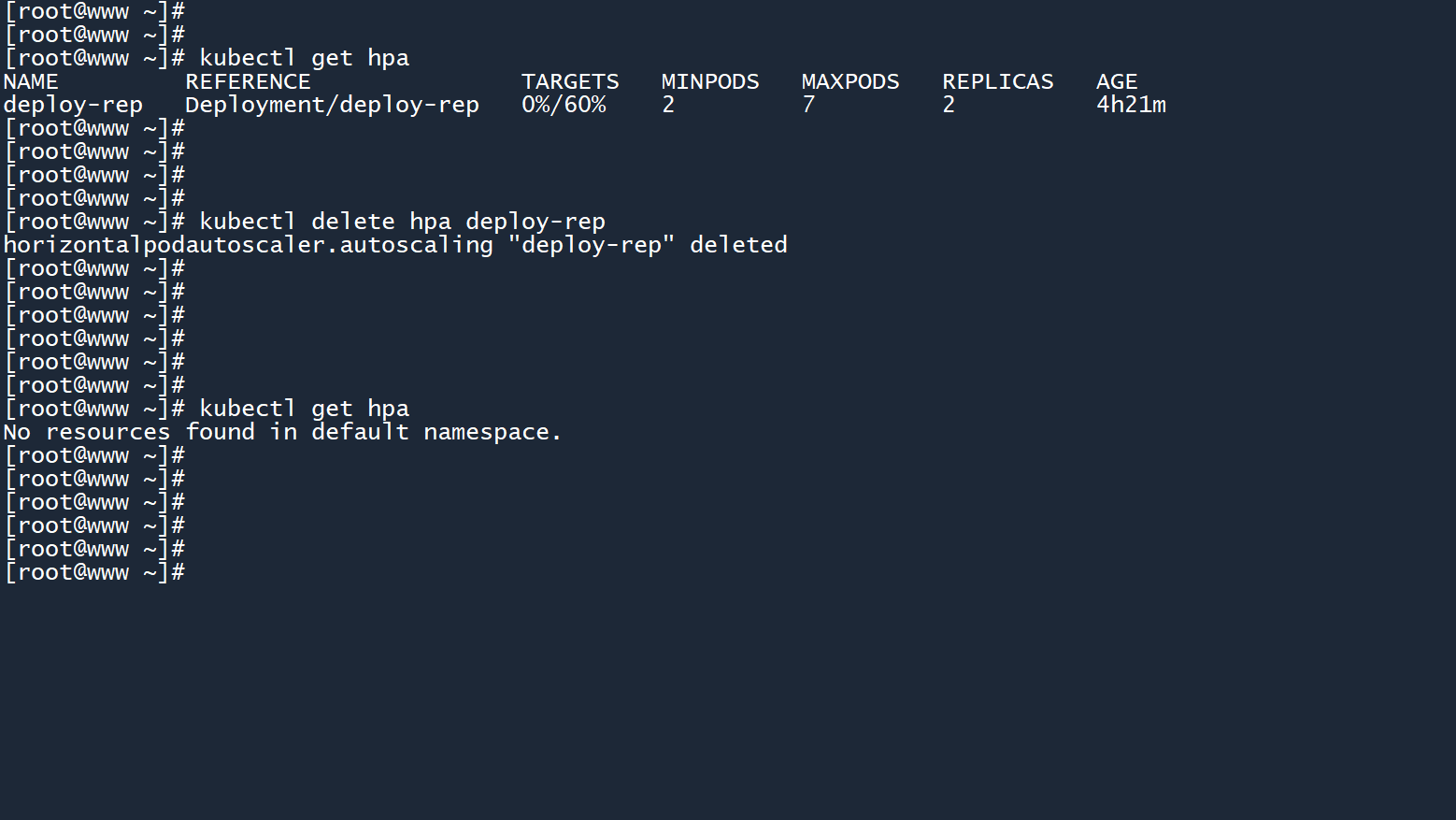
7、本次实验成功,将这个 HPA 删除:
kubectl delete hpa deploy-rep
# 4.24.2 HPA的v2版本
在 yaml 文件中,HPA 的apiVersion参数值为autoscaling/v1,例如:
# 快速生成一个 HPA 的配置文件
kubectl autoscale deployment deploy-rep --min=2 --max=7 --cpu-percent=60 --dry-run=client -o yaml > deploy-rep.yaml
2
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
creationTimestamp: null
name: deploy-rep
spec:
maxReplicas: 7
minReplicas: 2
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deploy-rep
targetCPUUtilizationPercentage: 60
2
3
4
5
6
7
8
9
10
11
12
13
这是一代版本的 HPA,可以用于设置 CPU 阈值。当 Pod 平均 CPU 负载超过阈值时,HPA 就会自动扩展副本数。
如果你曾运行过kubectl api-versions命令,你可能会发现 HPA 还有二代版本:
kubectl api-versions
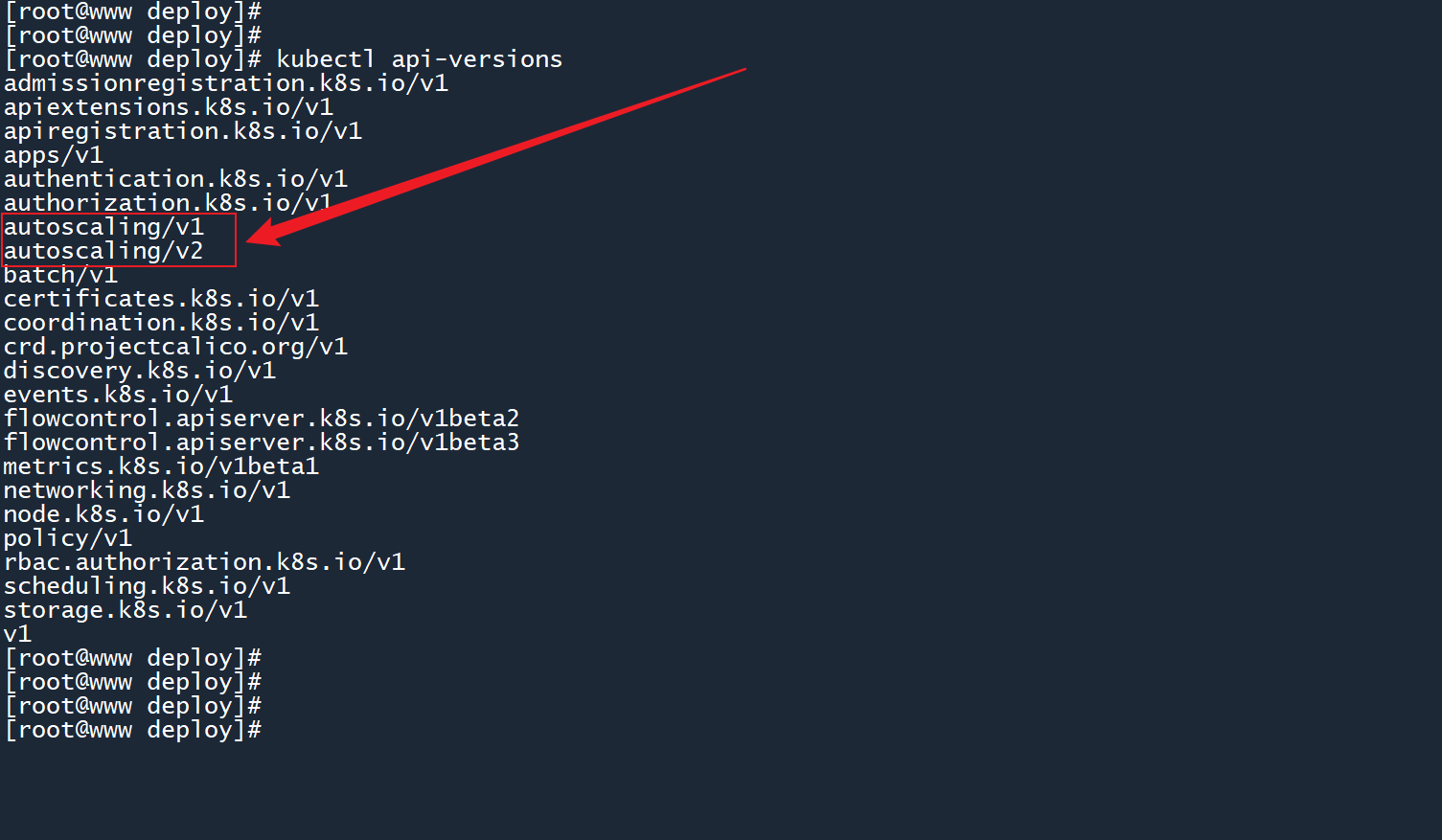
二代 HPA 无法通过命令行创建,但是可以通过 yaml 文件来生成:
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: deploy-rep
spec:
minReplicas: 2
maxReplicas: 7
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deploy-rep
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
你看出一代和二代 yaml 文件之间的细微区别了吗?二代 HPA 在一代的基础上增加了很多新功能,包括对内存使用率的自动扩缩。
# 4.34.3 根据内存负载情况自动扩缩
由于二代 HPA 无法通过命令行创建,kubectl也没有提供内存阈值的参数选项。
所以,如果你想根据内存使用率对 deployment 进行自动扩缩,则必须通过 yaml 文件来创建二代 HPA。
# 4.3.14.3.1 阈值-百分比
1、将 “4.2” 章节中展示的二代 HPA 另存至rep-hpa2.yaml文件当中:
cat <<EOF > rep-hpa2.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: deploy-rep
spec:
minReplicas: 2
maxReplicas: 7
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deploy-rep
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
EOF
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
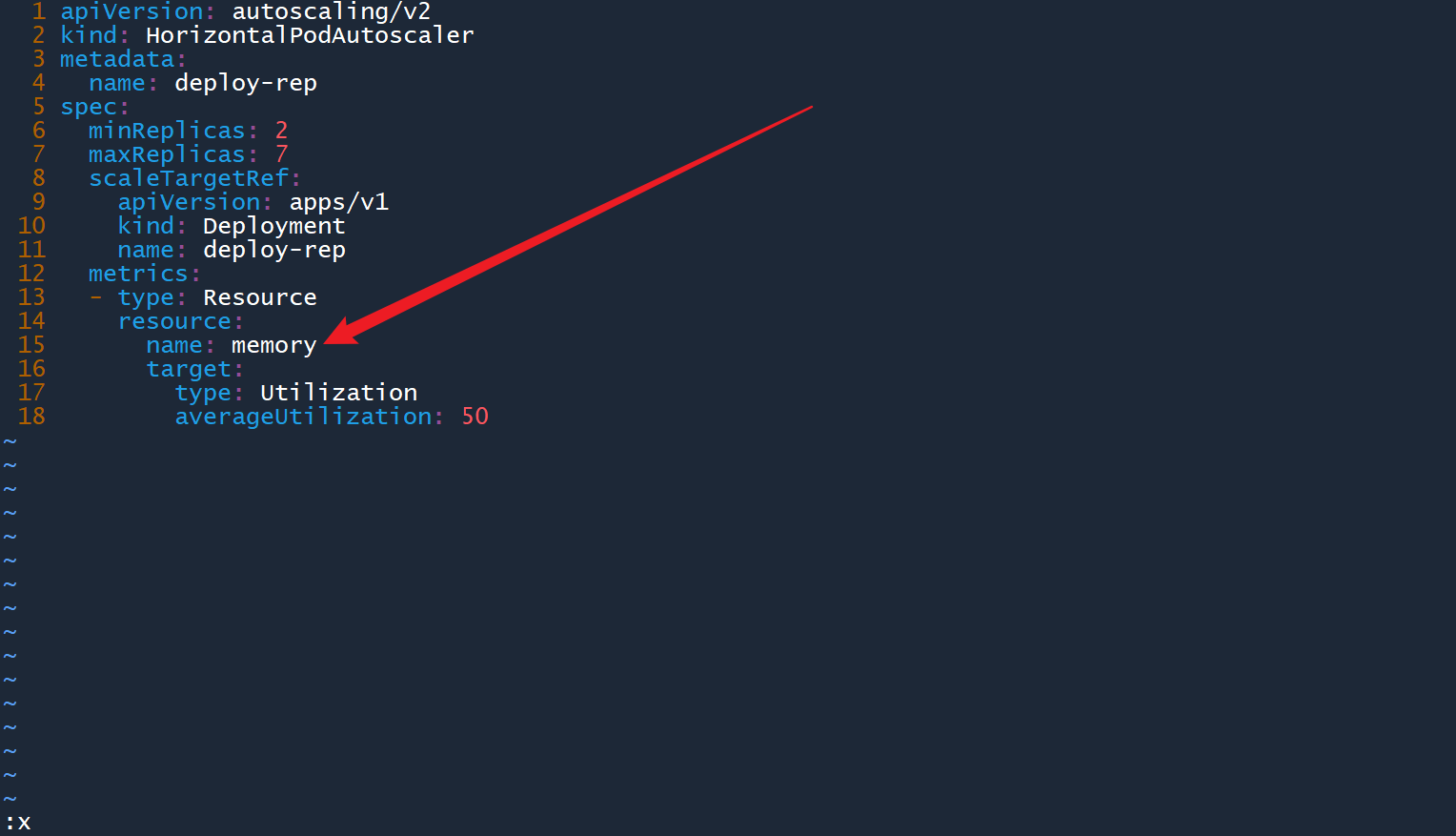
2、编辑rep-hpa2.yaml文件,将字段spec.metrics.resource.name修改为memory,然后保存退出:
vim rep-hpa2.yaml
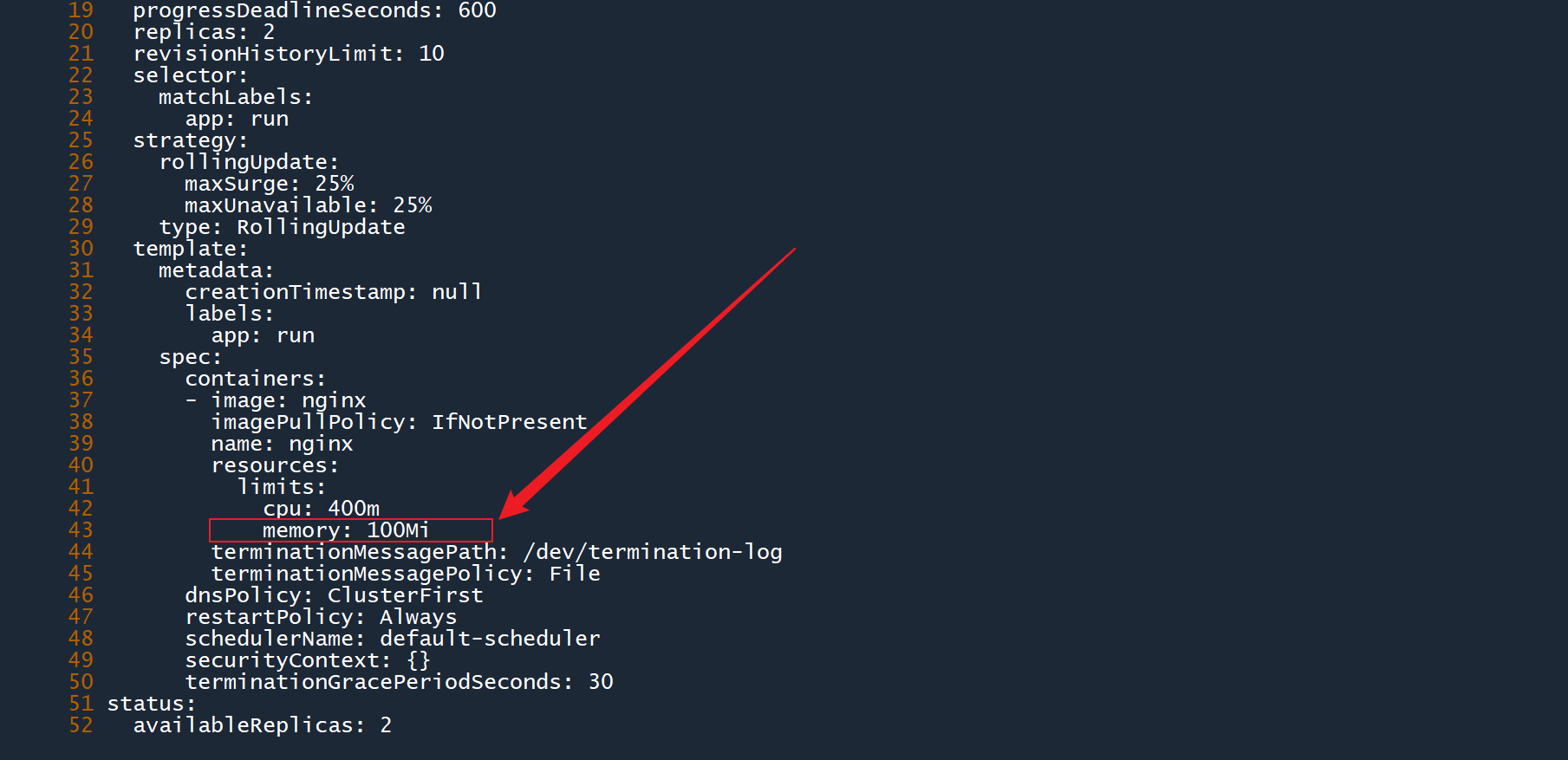
3、编辑控制器deploy-rep,在之前实验的基础上,为 Pod 模板添加内存资源限制,将内存使用上限设置为100Mi,然后保存退出:
kubectl edit deployment deploy-rep
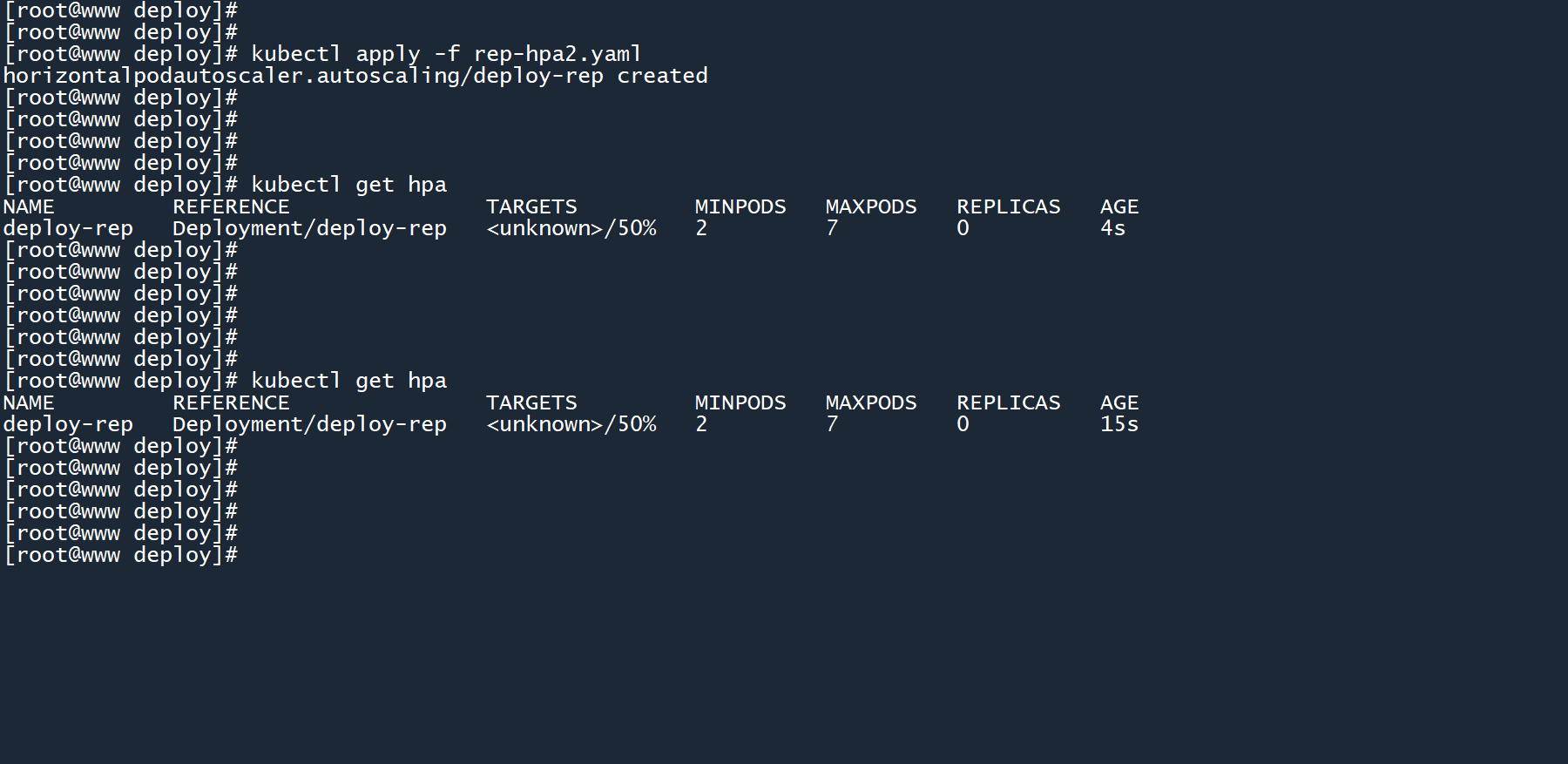
4、创建这个二代 HPA:
kubectl apply -f rep-hpa2.yaml
由于 HPA 刚刚被创建出来,所以当前的内存使用率会显示为<unknown>(未知)。
5、等待一段时间,再次查看 HPA:
kubectl get hpa
此时 HPA 已经正确识别了所有 Pod 的平均内存使用率,之前的<unknown>变为了2%。
当两个 Pod 的平均内存使用率达到资源上限(100Mi)的50%(阈值50Mi)的时候,HPA 就会自动扩展 deployment 的副本数。
# 4.3.24.3.2 阈值-绝对数值
前面的阈值都是通过资源上限 * 百分比 = ?来计算的,我能否提供一个具体的数值,而不是一个百分比?
1、当然可以,我在rep-hpa2.yaml的基础上添加了 CPU 阈值,它是一个具体的值:
vim rep-hpa2.yaml
# rep-hpa2.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: deploy-rep
spec:
minReplicas: 2
maxReplicas: 7
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: deploy-rep
metrics:
- type: Resource
resource:
name: memory
target:
type: Utilization
averageUtilization: 50
- type: Resource
resource:
name: cpu
target:
type: AverageValue
averageValue: 280m
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
你看出来两者的不同了吗?
- 对于百分比阈值,需要通过
type: Utilization和averageUtilization: <百分比>来设置 - 对于绝对数值,需要通过
type: AverageValue和averageValue: <值>来设置
2、应用新的 yaml 配置:
kubectl apply -f rep-hpa2.yaml
kubectl get hpa
2
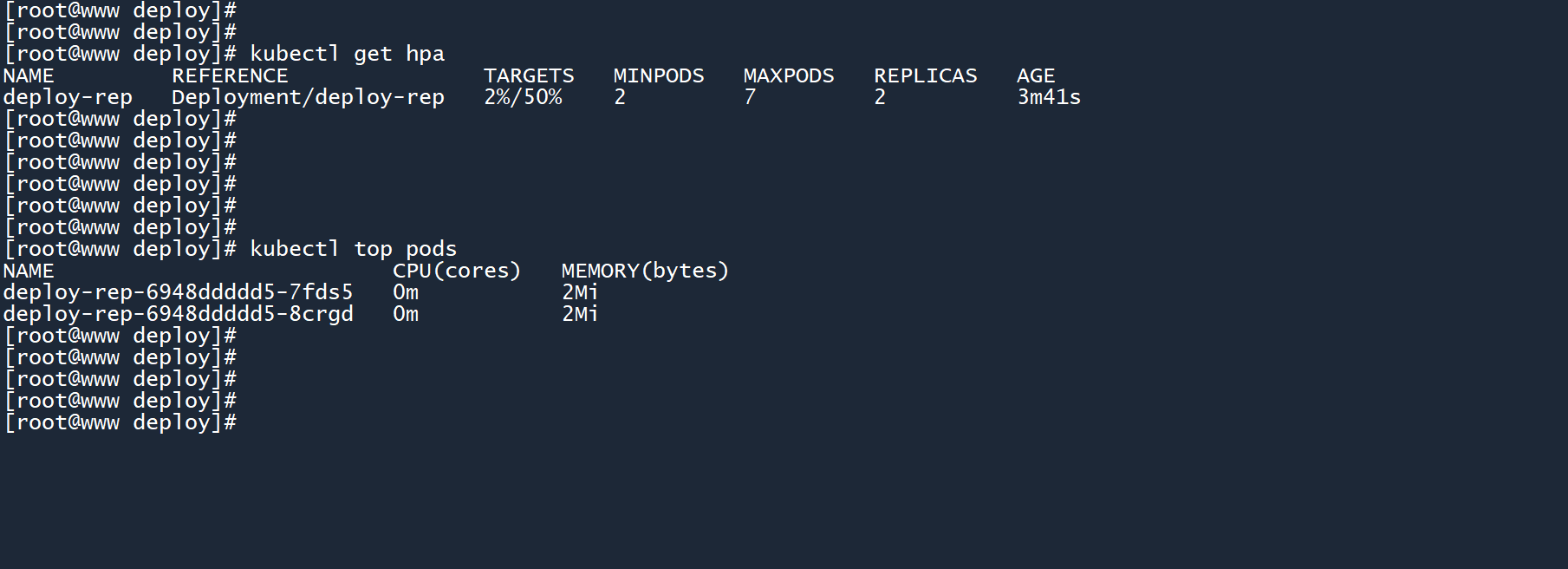
应用更改之后,现在 HPA 可以同时监测 CPU 和内存的平均使用率,从而动态扩缩 deployment 副本数。
那么问题来了,扩缩的条件是超过一个阈值,还是同时超过两个阈值?
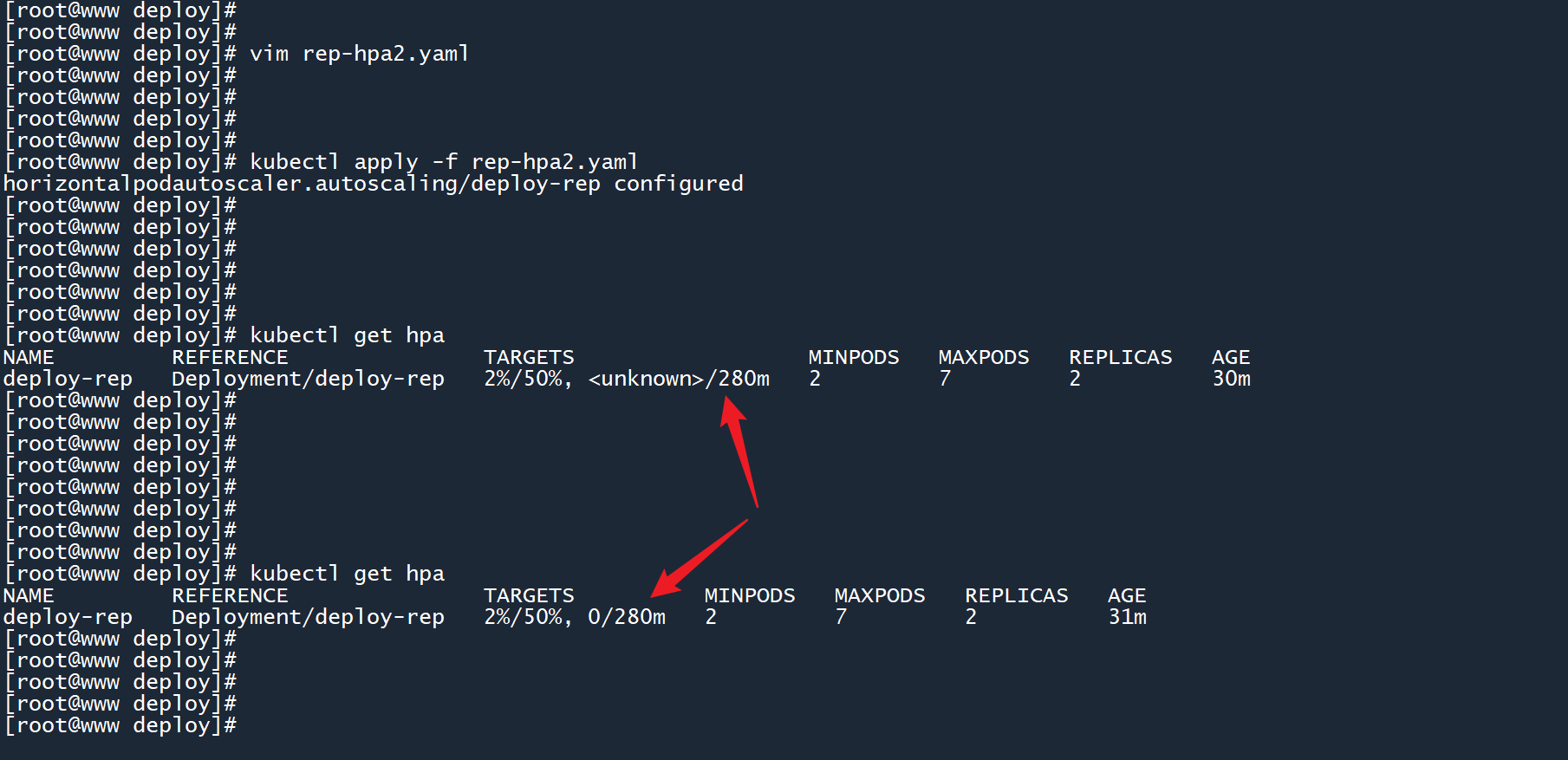
3、让我们回到之前安装了压力测试工具的主机上,再次运行压力测试工具,对 deployment 网络服务的地址发起请求:
# worker
ab -t 600 -n 1000000 -c 1000 http://10.106.94.87/
2
4、在 master 上不断查看 HPA 情况:
kubectl top pods ; echo ; kubectl get hpa
此时,两个 Pod 的平均 CPU 使用率已经超过了阈值,但 HPA 毫无动作。
难道要同时满足两个条件?别急,再看看。
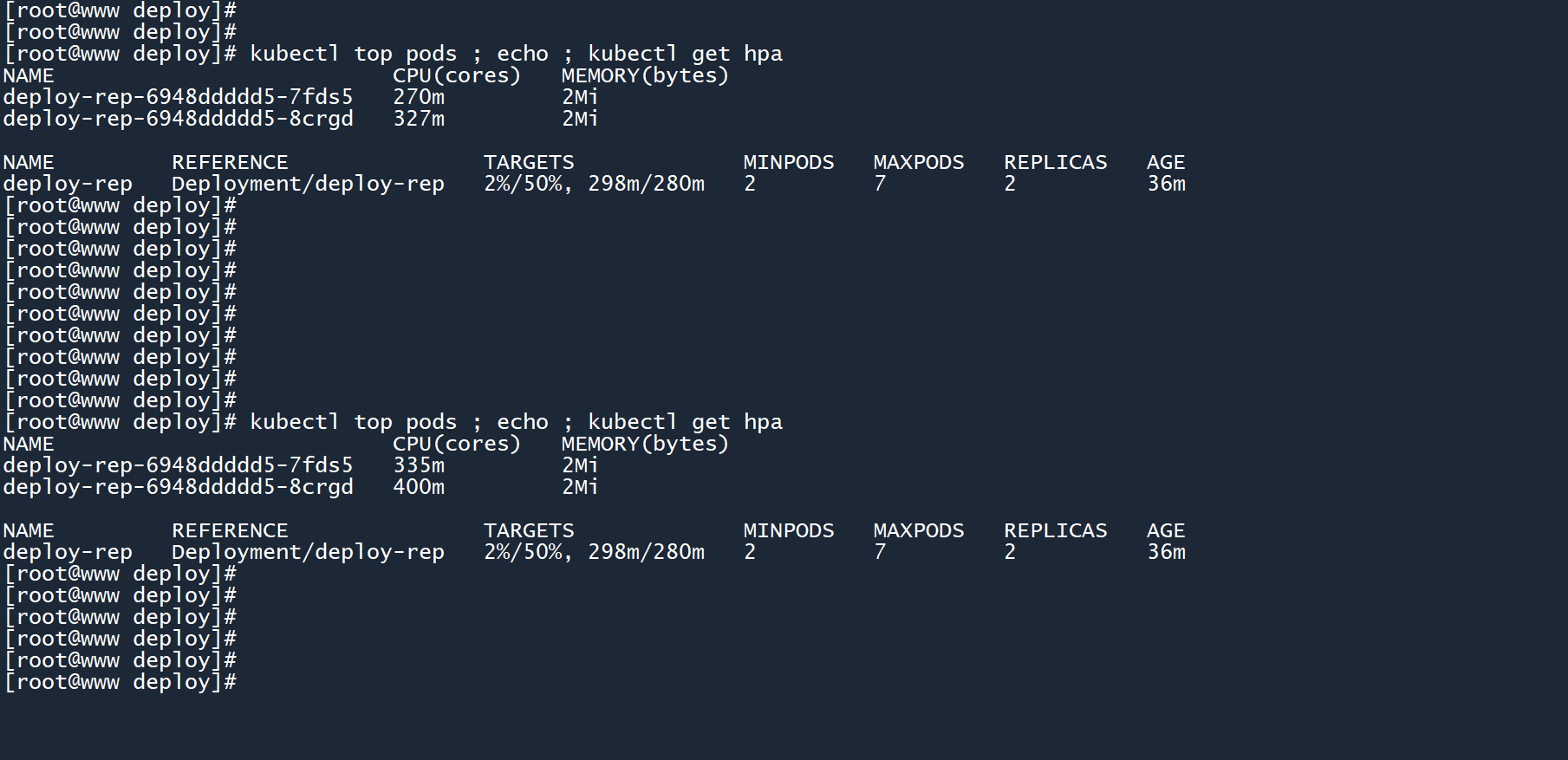
等待一会之后,HPA 出手了。
由于平均 CPU 负载过高,HPA 扩展了副本数,创建更多的 Pod 来分担业务量,将平均负载降到了280m以下。
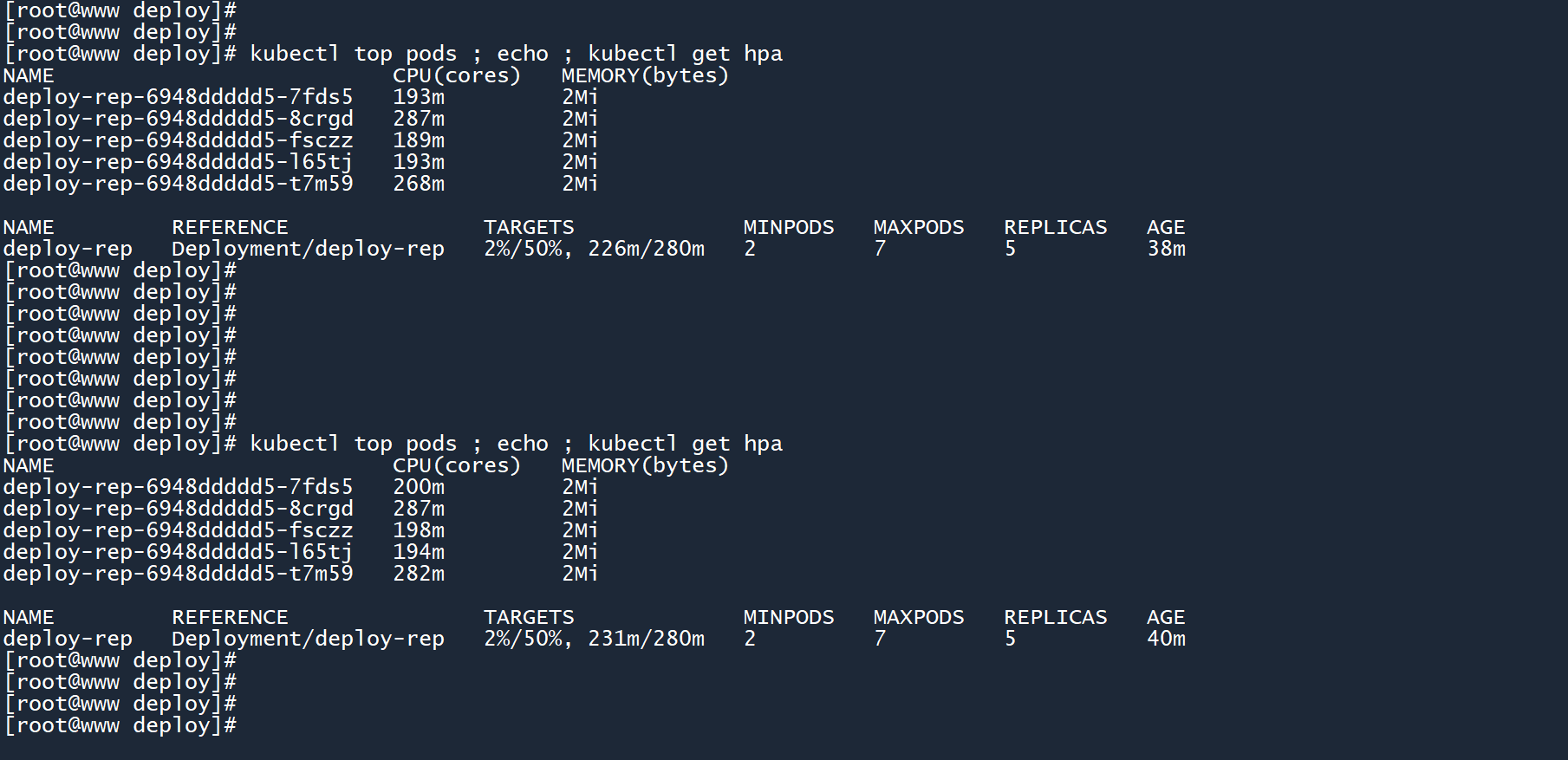
笔记
如果 HPA 同时配置了 CPU 和内存阈值,则它们是 “或” 的关系。只要其中一个超出了阈值,就会自动扩展副本数。
5、当平均负载稳定降下来之后,HPA 会等待一段时间(防抖期),然后缩减副本数。
kubectl top pods ; echo ; kubectl get hpa
6、最后,删除 HPA、Deployment 和网络服务:
kubectl delete hpa deploy-rep
kubectl delete deployment deploy-rep
kubectl delete service deploy-rep
2
3
# 5小结
本章对控制器 Deployment 做了一个了解,并学习了如何创建、删除和编辑 Deployment。
还学习了如何为 Deployment 配置水平自动扩缩(HPA 和 HPAv2),通过 HPA 来监测 CPU 和内存平均使用情况,然后自动扩缩 Pod 数量。
通过本章的学习,你应该掌握以下技能:
- 创建和删除 Deployment,根据标签来追踪 Pod 群体
- 配置 Deployment 副本数和 Pod 模板
- 编辑正在运行的 Deployment
- 为一个 Deployment 配置水平自动更新 HPA
- 二代 HPA 的使用
如果你已经掌握以上内容,可以去做些练习题巩固一下(练习题-6)。