 第6章-Pod生命周期与资源限制
第6章-Pod生命周期与资源限制
原创
本博客原创文章,转载请注明出处
- name: 原创
desc: 本博客原创文章,转载请注明出处
bgColor: '#F0DFB1'
textColor: '#1078E6'
2
3
4
# 第6章-Pod生命周期与资源限制
| 本章要点 |
|---|
| Pod 的生命周期(lifecycle)和钩子的使用 |
| Pod 的资源限制 |
| 创建和删除 LimitRange |
| 创建和删除 ResourceQuota |
# 11. Pod生命周期
# 1.11.1 概念
# (1)生命周期
当 Pod 成功运行容器的那一刻起,这个 Pod 的生命周期就开始了,这是创建和启动 Pod。
当 Pod 中的所有容器都终止运行了,那么这个 Pod 的生命周期也就结束了,这是停止和删除 Pod。
# (2)Pod延期删除
有时,删除 Pod 的时候如果不添加--force(强制删除)选项的话,删除 Pod 的时间就会明显变长。这是因为 k8s 在删除 Pod 的时候会有一个延迟删除期(宽限期),宽限的时间一般为30秒。
(第一次画图,有点潦草,请见谅)
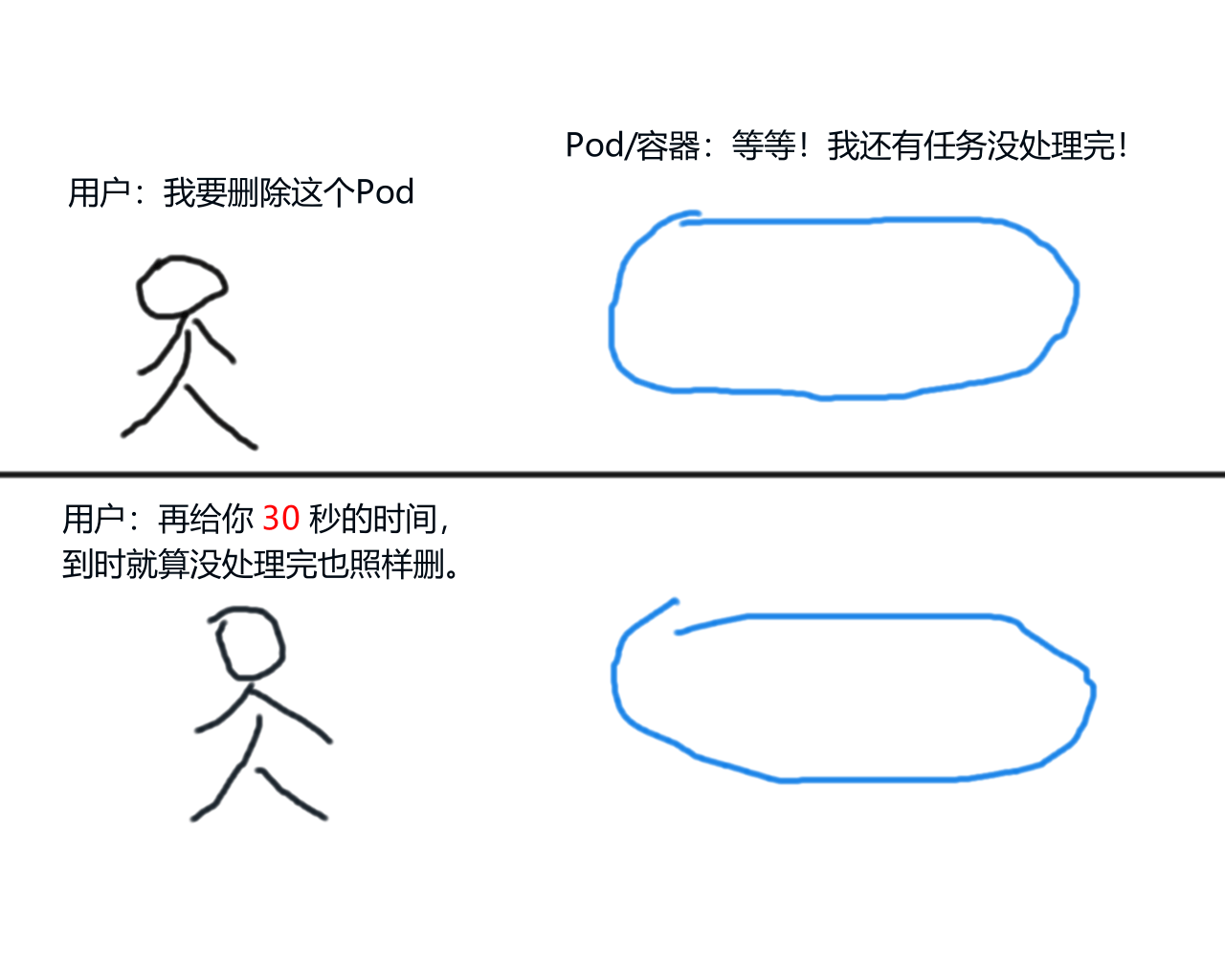
一个 Pod 正在处理某些任务,此时你发出了删除命令,有宽限期的情况下:
- 这个 Pod 并不会被立即删除,它的状态会被标记为 “terminating”
- 然后等待这个 Pod 继续将手头上的任务处理完成
- 如果在 30 秒内完成处理,则 Pod 会被自动删除
- 如果处理超过了 30 秒,则 Pod 会被强制删除
如果没有宽限期:
- 这个 Pod 会被立即删除,而不管它是否正在处理任务
- 可能会造成连接中断、数据丢失等影响
前者被称为 “优雅地删除 Pod”,后者被称为 “粗暴地删除 Pod”。作为一个优秀的 k8s 工程师,当然是想要前者了。
# 1.21.2 指定宽限期
在创建 Pod 的 yaml 文件中,你可以通过spec.terminationGracePeriodSeconds参数来指定宽限时间,单位是 “秒”。
(吐槽:这参数的名称为啥那么长,不好记啊)
以下 yaml 文件指定宽限时间为 15 秒(默认为 30 秒),
...
spec:
terminationGracePeriodSeconds: 15
containers:
- image: alpine
command: ["sh", "-c", "echo hello && sleep 9999"]
...
2
3
4
5
6
7
以上 Pod 在创建之后,会通过echo命令打印字符串 “hello”,然后通过sleep命令休眠 9999 秒。这意味着该 Pod 会在 9999 秒后终止,但是这超过了 15 秒的宽限时间,所以这个 Pod 会被强制删除。
此外,如果你将宽限期设置为零的话(spec.terminationGracePeriodSeconds: 0),意味着没有宽限期(禁用宽限期),这会导致 Pod 被立即删除。
# 22 Pod hook(钩子)
# 2.12.1 钩子概念
虽然可以为 Pod 指定宽限期,实现 “优雅地删除 Pod”。
但是,某些运行在 Pod 中的服务进程,并不会使用这个宽限期。
拿nginx容器来说,由于 nginx 进程处理信号的方式和 k8s 的处理方式不太一样,所以当你向 nginx 容器发出删除信号时,Pod 中的 nginx 进程会很快关闭,Pod 也会被直接删除。这个 Pod 并不会使用 k8s 提供的宽限期,由此造成了一个 “粗暴地删除 Pod”。
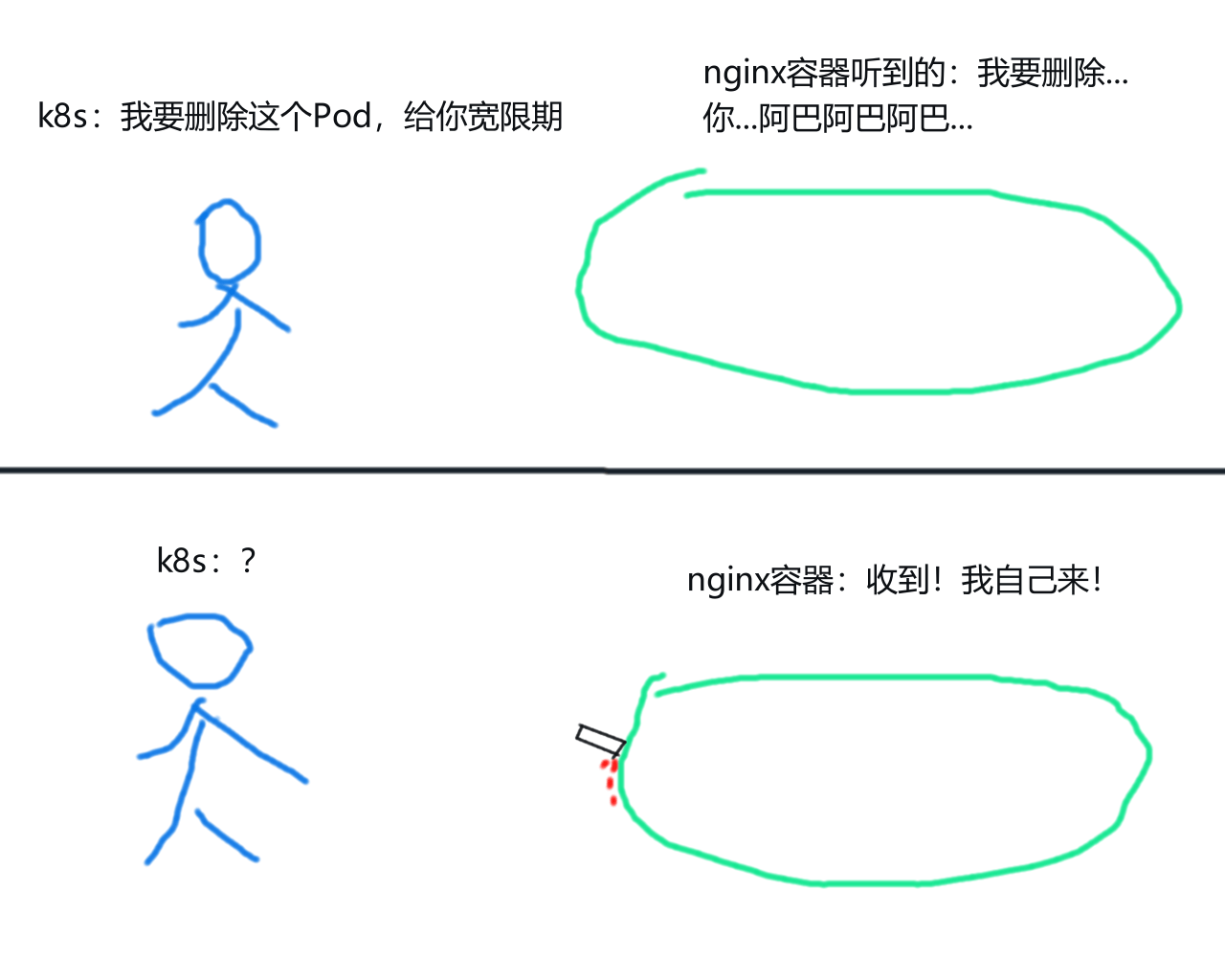
nginx 容器通常用于处理客户端连接,如果在处理任务时被粗暴删除,则客户端可能会访问报错。而钩子可用于解决这类问题。
在 Pod 生命周期中,k8s 提供了两个钩子:postStart和preStop。两个钩子在 yaml 文件中的参数路径:
spec.containers.lifecycle.postStartspec.containers.lifecycle.preStop
# 2.2preStop钩子(结束钩子)
preStop 钩子会在容器关闭之前运行,只有当 preStop 运行完毕,容器/Pod 才会被关闭和删除。
- preStop 中的任务也必须在延迟删除期(宽限期)之前完成处理,否则 Pod 一样会被强制删除
使用 preStop 钩子可以解决 “nginx容器无法优雅关闭” 的问题。
创建以下 yaml 文件:
spec.containers.lifecycle.preStop用于设置容器生命周期中的 preStop 钩子preStop.exec:钩子要处理的任务项preStop.exec.command:通过钩子在容器中执行命令,这和spec.containers.command是一样的
apiVersion: v1
kind: Pod
metadata:
name: prestop-pod
spec:
terminationGracePeriodSeconds: 180
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: prestop-pod
lifecycle:
preStop:
exec:
command: ['sh', '-c', '/usr/sbin/nginx -s quit']
2
3
4
5
6
7
8
9
10
11
12
13
14
以上钩子在容器关闭之前运行命令sh -c /usr/sbin/nginx -s quit,这里直接通过 nginx 可执行程序运行了 “quit”(退出)指令,是一种优雅关闭 nginx 服务的方式。
笔记
退出命令nginx -s quit运行之后,会等待 nginx 处理完现有任务,然后再关闭 nginx 进程。
除此之外,还有一个退出命令nginx -s stop(快速关闭 nginx),这是一种粗暴关闭 nginx 的方式,因为该命令不会等待 nginx,而是直接关闭它。
创建这个 Pod。
当你删除这个 Pod 的时候:
- Pod 的状态会被标记为 “terminating”
- 删除信号发送至 preStop 钩子,命令
sh -c /usr/sbin/nginx -s quit会被执行 nginx -s quit执行后,会等待 nginx 处理完手头上的任务,然后再关闭 nginx 进程- nginx 进程被关闭后,preStop 钩子的使命也完成了,Pod 会被继续删除
宽限期可以尽量设置的高一点(此处为 180 秒),好让 preStop 钩子有足够的时间去处理任务。
# 2.3postStart钩子(启动钩子)
postStart 钩子会在容器创建之后,跟随容器主进程一同运行,没有先后顺序之分(两者异步运行)。postStart 钩子有点类似于初始化容器,但它们有不同点。
# (1)postStart正常运行
创建以下 yaml 文件:
apiVersion: v1
kind: Pod
metadata:
name: poststart-pod
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: poststart-pod
lifecycle:
postStart:
exec:
command: ['sh', '-c', 'echo "Hello k8s, I am postStart" > /opt/hello.txt']
2
3
4
5
6
7
8
9
10
11
12
13
以上钩子在容器启动的同时,使用echo命令将字符串 “Hello k8s, I am postStart” 输出到文件/opt/hello.txt中。
创建 Pod 之后,通过kubectl exec获取容器的终端,在/opt目录下可以找到所生成的文件。
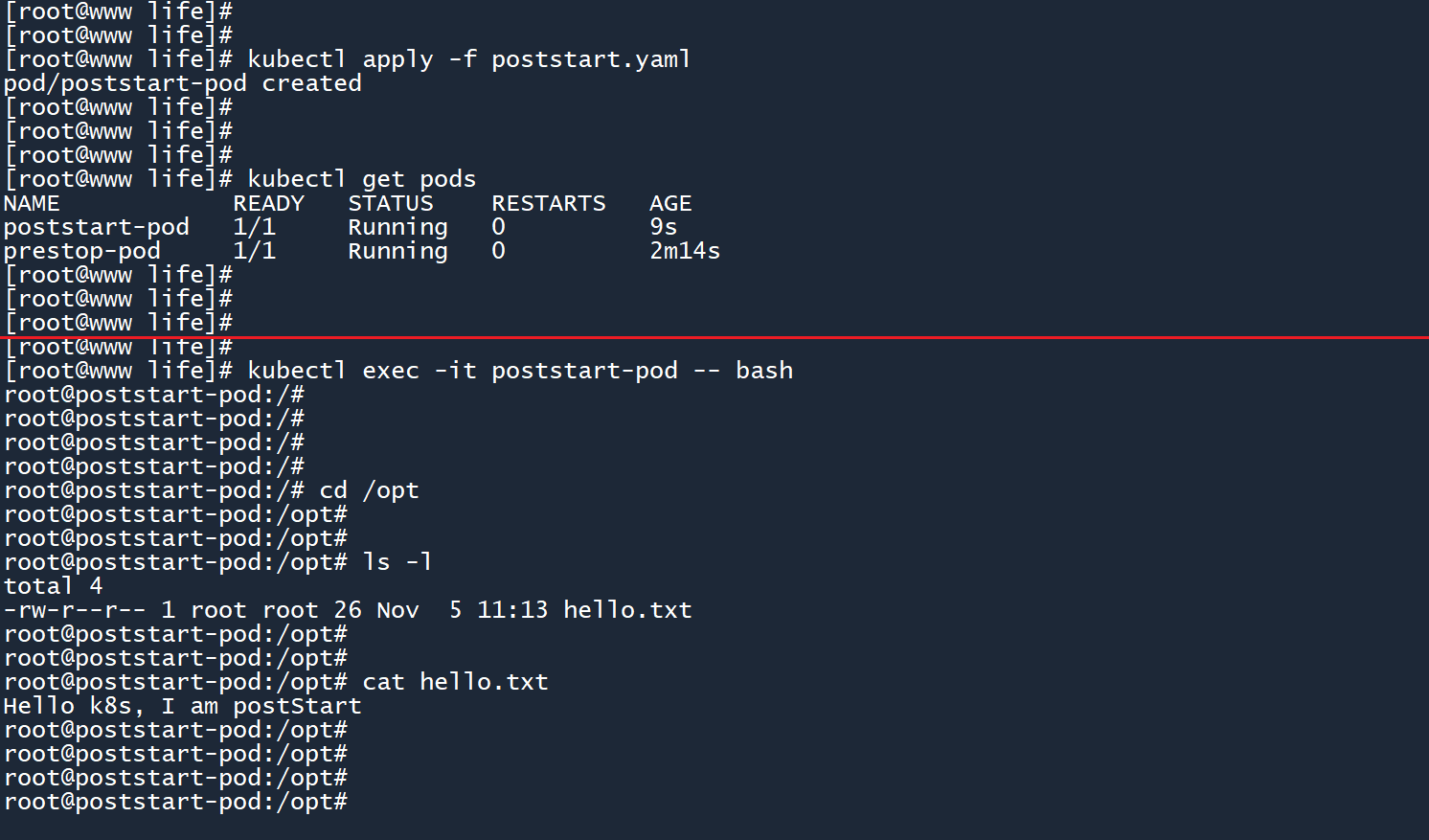
这和初始化容器不太一样,初始化容器在普通容器之前运行,并且拥有一个独立的容器来运行初始化任务。只有当初始化容器全部完成运行,普通容器才会被创建和启动。初始化完毕后,初始化容器会被删除。
postStart 钩子和当前容器一起被创建出来,并且和主进程一起在普通容器中运行,所做的操作和更改 会应用到当前容器中。
# (2)postStart运行错误
如果 postStart 钩子运行出错会发生什么?这里我故意将echo命令打错成ehco:
# poststart-error.yaml
apiVersion: v1
kind: Pod
metadata:
name: poststart-error
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: poststart-error
lifecycle:
postStart:
exec:
command: ['sh', '-c', 'ehco "Hello k8s, I am postStart" > /opt/hello.txt']
2
3
4
5
6
7
8
9
10
11
12
13
14
创建 Pod 后可以看到状态为 “PostStartHookError”(postStart钩子错误),由于 Pod 重启策略默认为 “Always”(遇到错误时总是重启),所以 Pod 会一直通过重启来试图解决错误。
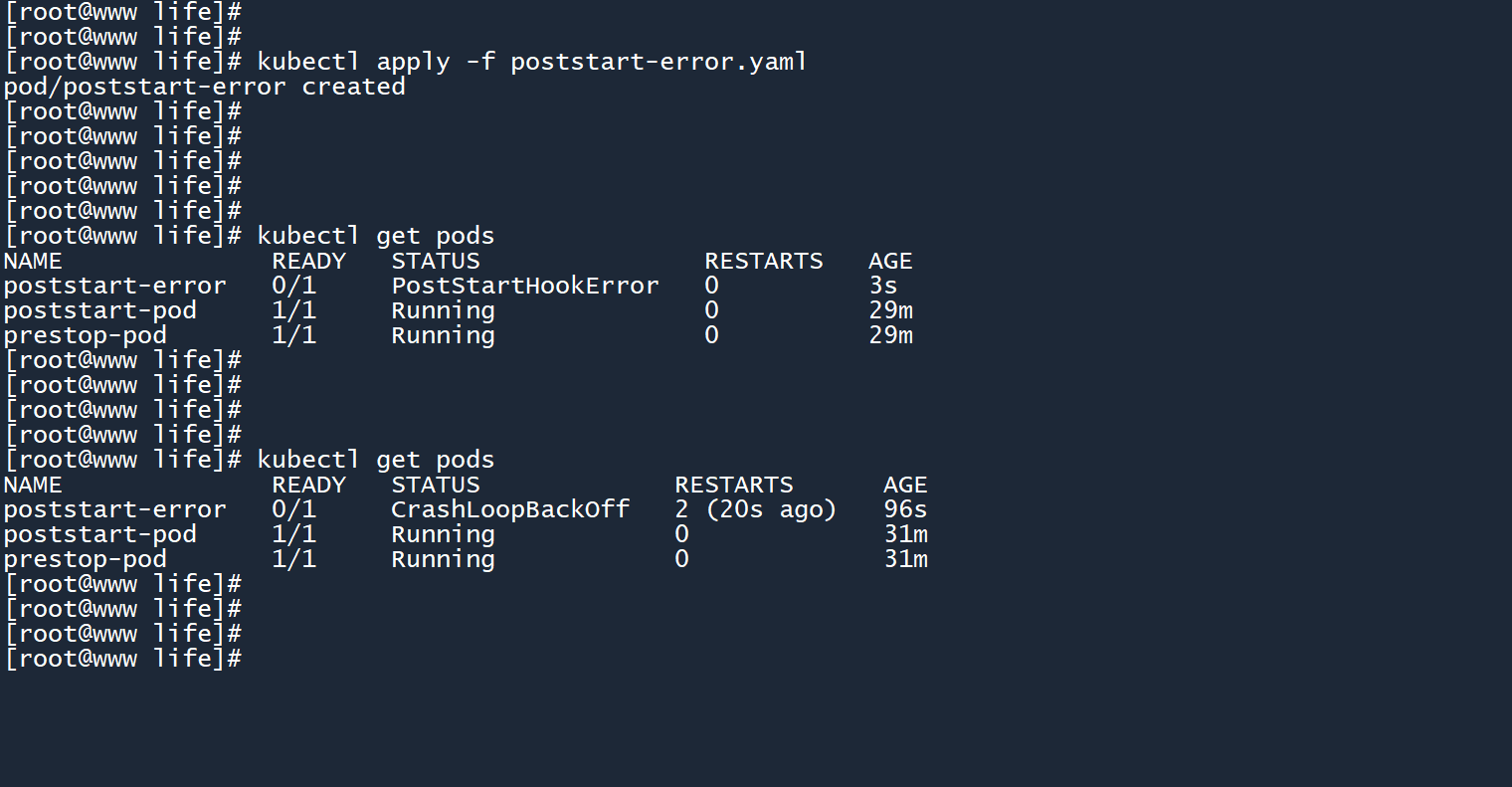
你以为我会说 “这和初始化容器一样”?
其实不一样,还是有根本上的区别:
- 初始化容器 单独创建另一个容器 来执行任务,如果初始化容器运行出错,则后续的普通容器不会被创建和启动
- 创建普通容器之后,postStart 会和主进程一起异步运行,由于 postStart 是在当前容器中执行的,所以 postStart 运行出错意味着普通容器运行出错。此时的容器其实已经被创建出来了,只不过运行期间出现了错误
# (3)postStart阻塞
postStart 处理函数与容器的代码是异步执行的,但 Kubernetes 的容器管理逻辑会一直阻塞等待 postStart 处理函数执行完毕。只有 postStart 处理函数执行完毕,容器的状态才会变成 RUNNING。
以上是官方文档中的一段话,我们通过以下 yaml 文件来验证这段话:
# poststart-sleep.yaml
apiVersion: v1
kind: Pod
metadata:
name: poststart-sleep
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: poststart-sleep
lifecycle:
postStart:
exec:
command: ['sh', '-c', 'sleep 15']
2
3
4
5
6
7
8
9
10
11
12
13
14
以上钩子会在容器创建之后,使用sleep命令休眠 15 秒。
从图中可以看到,在 15s 之前,Pod 状态为 “ContainerCreating”(容器创建),说明 k8s 正在等待 postStart 执行完毕。
而在 15s 后,也就是 postStart 执行完毕之后,Pod 状态正常变为了 “RUNNING”。
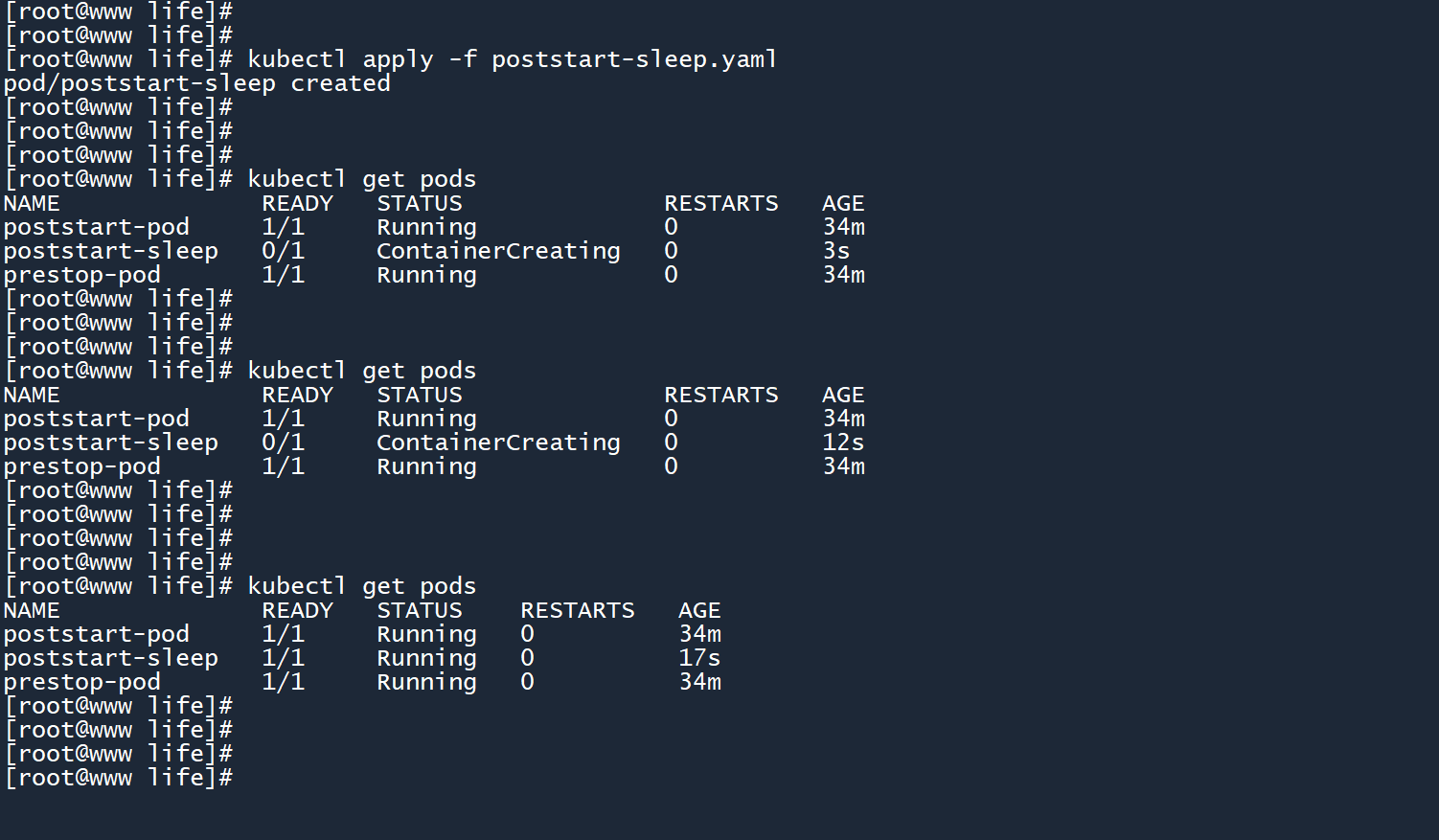
也是和初始化容器不太一样:
- 初始化容器没有运行完毕,则普通容器不会被创建和运行
- postStart 没有运行完毕,此时普通容器已经被创建,但它的状态会停留在 “ContainerCreating”,当 postStart 运行完毕之后才会变为 “RUNNING”。
# 2.42.4 钩子练习
以上两个钩子可以结合使用,下面来做个练习。
创建以下 yaml 文件:
apiVersion: v1
kind: Pod
metadata:
name: pod-life
spec:
terminationGracePeriodSeconds: 120
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod-life
lifecycle:
postStart:
exec:
command: ['sh', '-c', 'echo "<h1>Hello nginx! I am postStart.</h1>" > /usr/share/nginx/html/index.html']
preStop:
exec:
command: ['sh', '-c', '/usr/sbin/nginx -s quit']
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
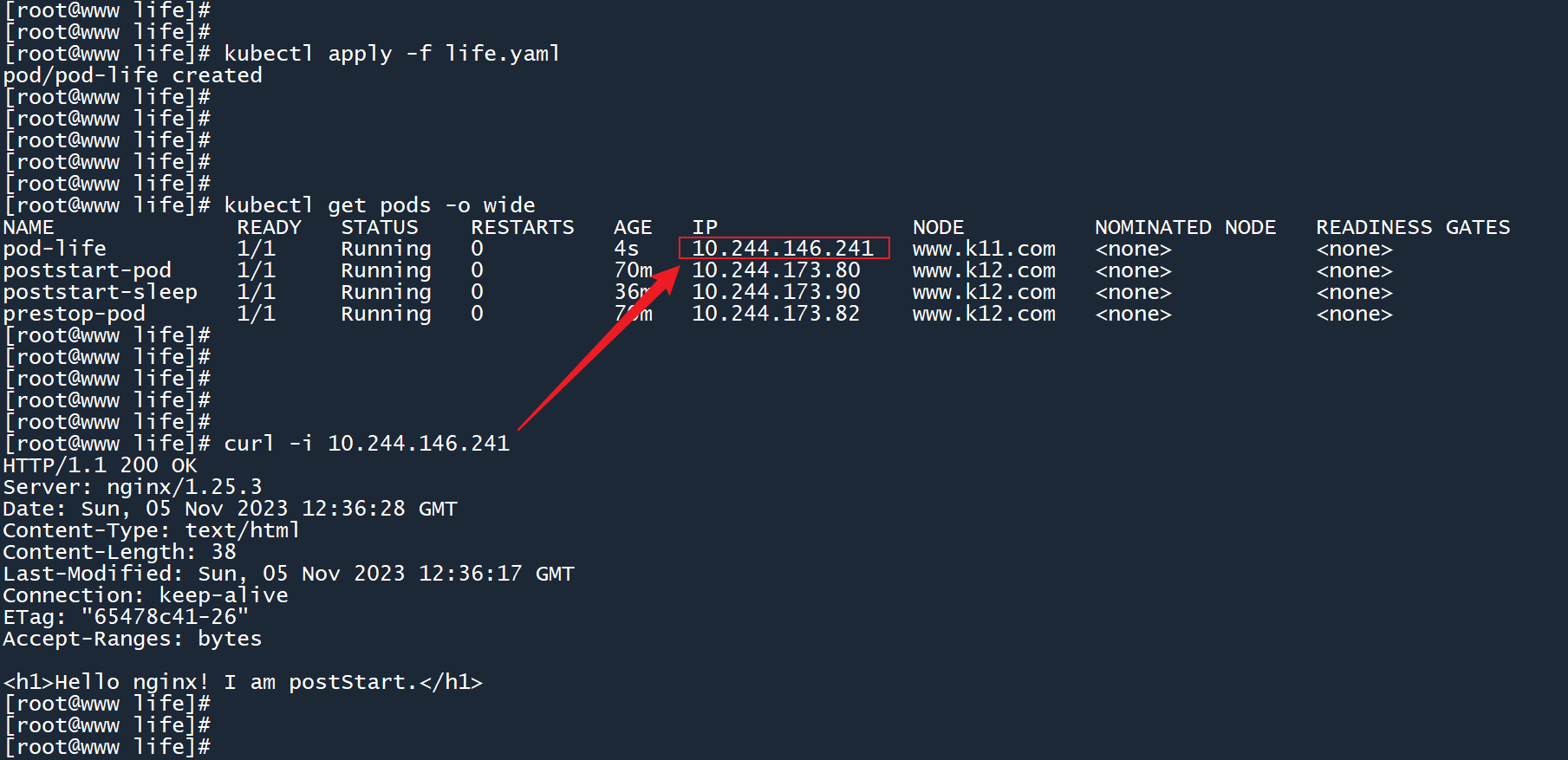
postStart 钩子使用echo将字符串 “Hello nginx! I am postStart.” 输出到 nginx 的默认首页文件当中,这将会覆盖默认的 Web 页面内容。
preStop 钩子则在删除 Pod 之前,通过 nginx 可执行程序运行退出命令,以优雅地关闭 nginx 进程。此外还给予了 120s 的宽限期,使钩子有足够的时间去完成关闭任务。
创建 Pod 之后,通过-o wide选项查看这个 Pod 的 IP 地址。然后使用curl命令发送一个 HTTP 请求,以访问网站首页。
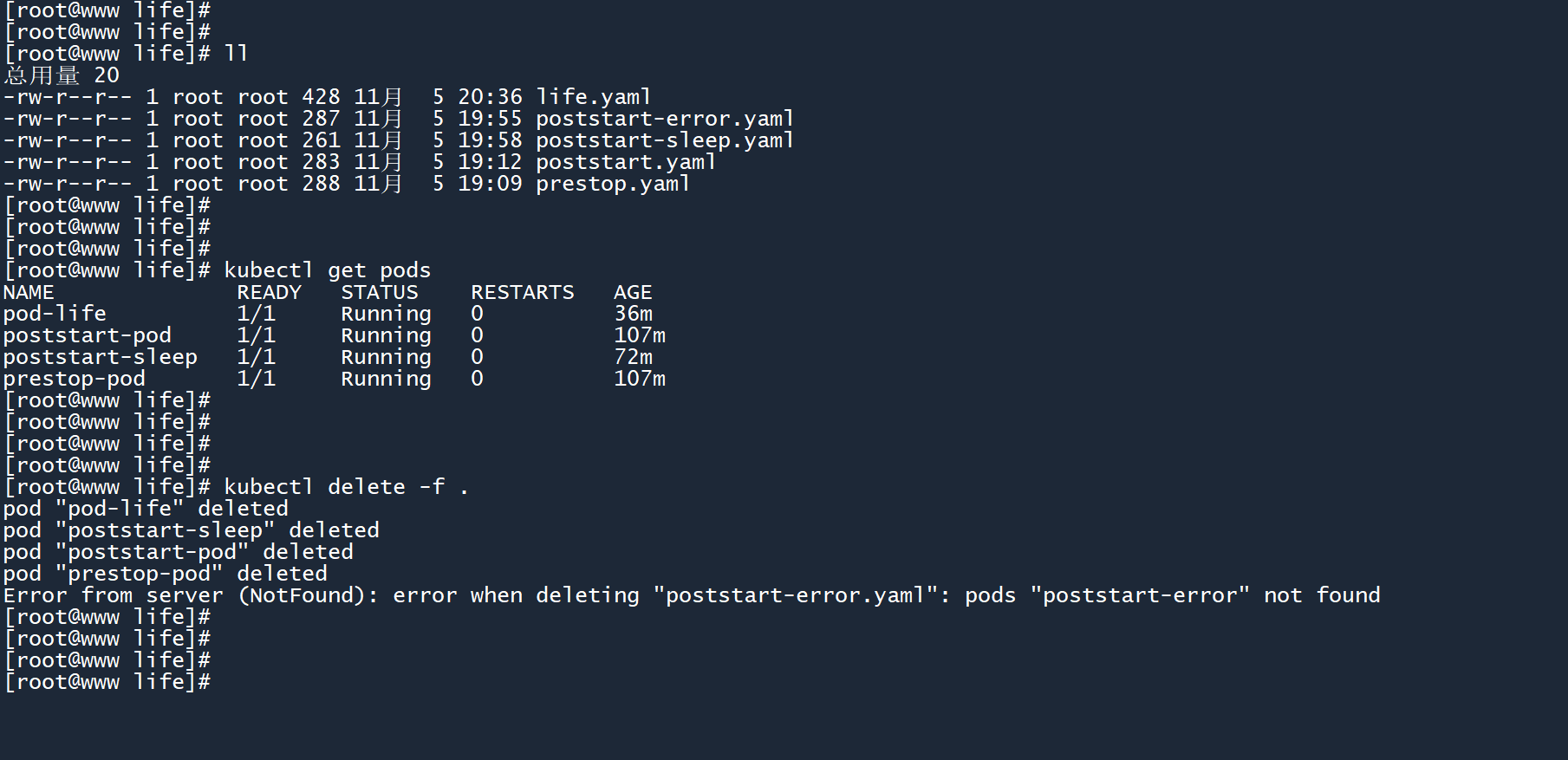
最后教你一招,通过 yaml 文件一次性删除多个 Pod:
.点表示当前目录下的所有文件名称
kubectl delete -f .
删除过程中遇到的错误会被忽略,不会影响后续删除的执行。
# 33. Pod资源限制
Pod 中运行的是容器,由于默认没有资源限制,容器会毫无节制地使用物理机中的 CPU 和内存等资源。由此一来,物理机很容易卡顿甚至宕机,这是一个安全隐患。
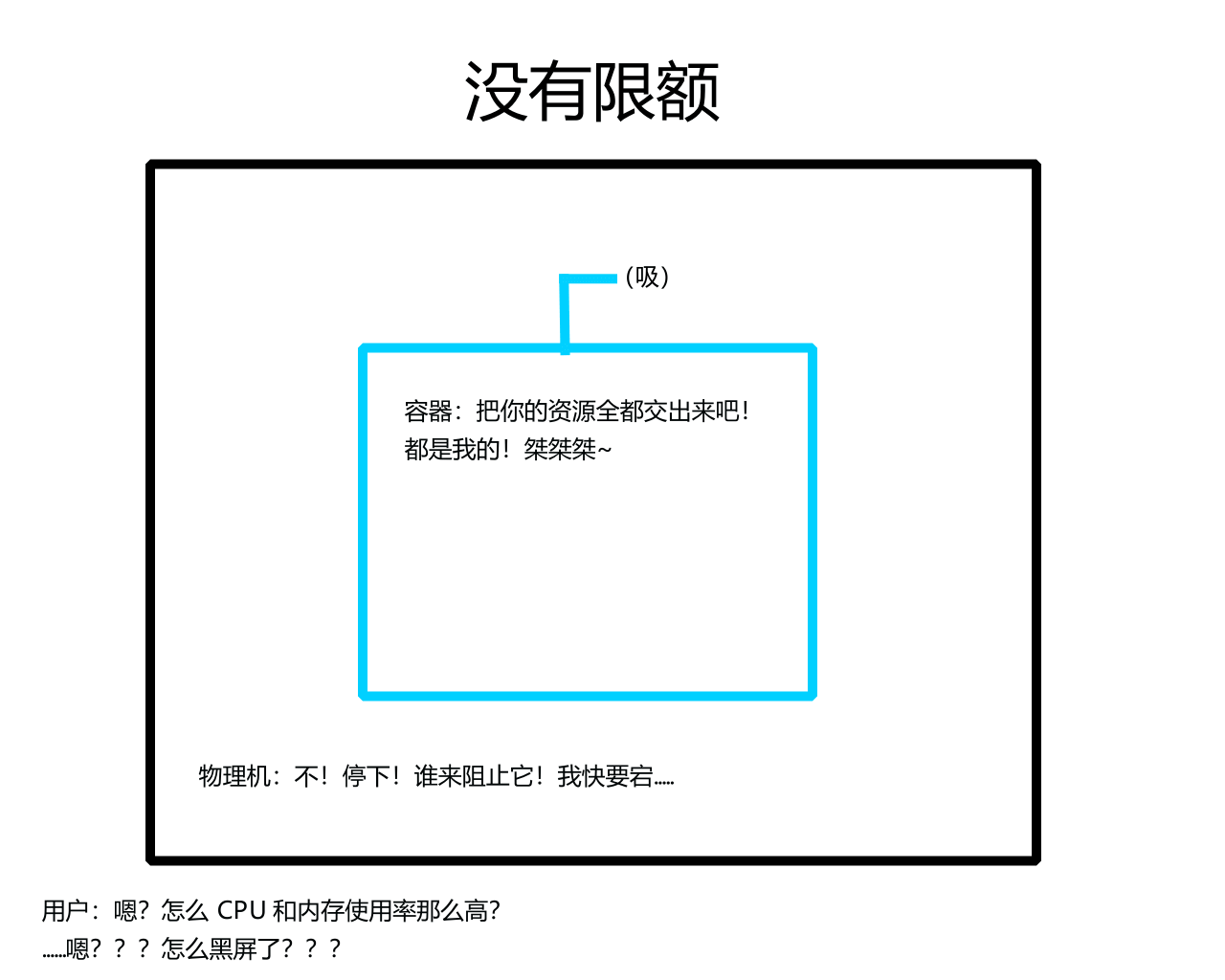
# 3.13.1 resources参数
以下 yaml 文件展示了通过resources.limits参数进行资源限制:
# pod-re.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-re
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod-re
resources:
limits:
cpu: 100m
memory: 500Mi
2
3
4
5
6
7
8
9
10
11
12
13
14
这里需要注意 CPU 和内存的计量单位。
# 3.1.1CPU/内存计量单位
如果 CPU 不带单位,例如cpu: 2则表示两个 CPU 核心,如果带单位例如cpu: 500m则表示 500 个 CPU 微核心。
- 1 核心等于 1000 微核心
- 500m 相当于 0.5 个核心,250m 相当于 0.25 个核心
- 你也可以不指定单位,直接用
cpu: 0.5表示半个核心。但官方推荐你使用cpu: 500m,因为这更加精细
对于内存,你可以使用十进制的计算机存储单位E、P、T、G、M、k,它们分别表示 EB、PB、TB、GB、MB 和 kB。还可以使用二进制的存储单位Ei、Pi、Ti、Gi、Mi、Ki,分别表示 EiB、PiB、TiB、GiB、MiB 和 KiB。
内存单位中间的 “i” 有啥区别?不知道你是否买过 U 盘,存储容量总是缺斤少两,其实是生产 U 盘的厂商,使用了一种和计算机不同的存储计量方式:
- 我们平时说的 GB 指的是十进制存储单位:
1GB=1000MB。U 盘采用的就是十进制存储单位,一个32GB的 U 盘大小是32000 MB - 而计算机使用的是 GiB 二进制存储单位:
1GiB=1024MiB。如果有的话,一个32GiB的 U 盘大小应该为32768 MiB
然后一堆借口,说会有损耗啥啥啥的,导致 32GB 的 U 盘最后只剩下二十多......
在 k8s 中,推荐使用带 “i” 的单位,因为这兼容计算机存储标准,不容易缺斤少两和产生错误。在以上 yaml 文件中,将资源限制为了100个 CPU 微核心(0.1个核心)以及500 MiB的内存。
# 3.23.2 测试资源限制有效性
为了测试资源限制的有效性,我们待会创建一个 Pod,在其中安装并运行 CPU 和内存压力测试工具,看看资源限制是否生效。
# (1)下载容器镜像
这里使用的镜像是centos,因为需要通过 Centos 系统中的 rpm 包管理软件来安装内存测试工具。你可以通过以下命令 提前拉取该镜像:
# 下载速度可能较慢, 需要耐心等待
ctr -n k8s.io i pull docker.io/library/centos:latest
2
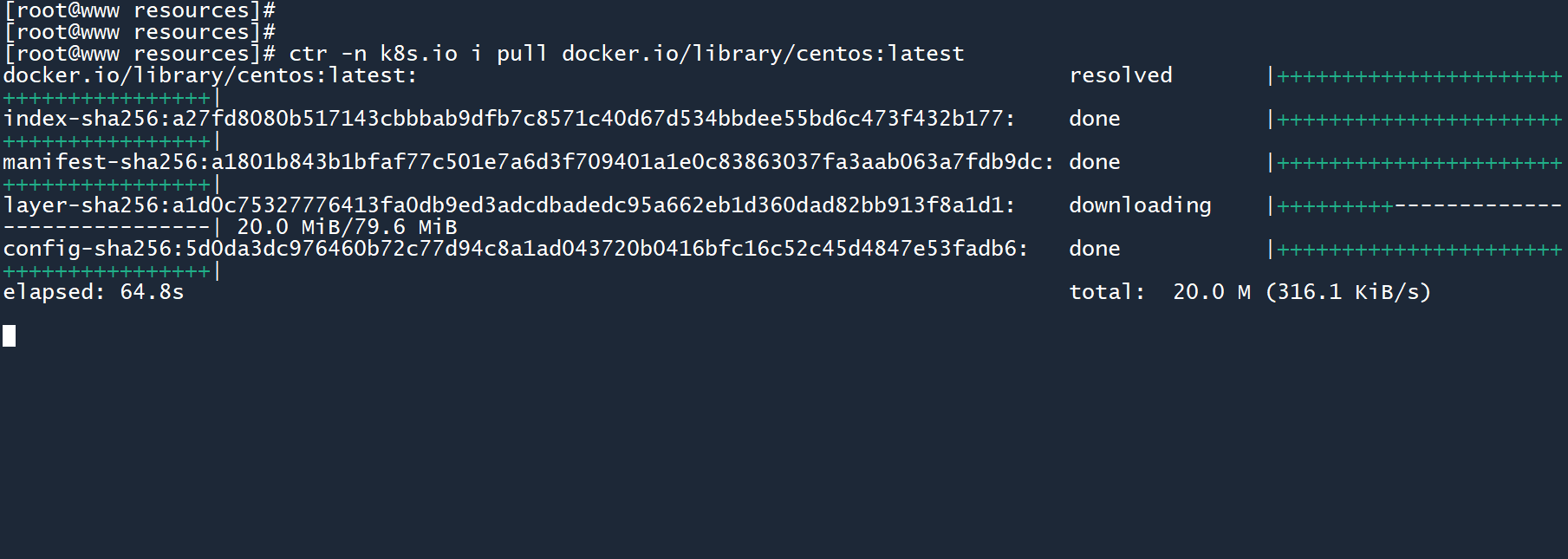
查看镜像是否存在。
ctr -n k8s.io i ls | grep centos
# (2)下载CPU/内存压力测试工具
CPU 压力测试工具可以在此处下载:https://pkgs.org/download/stress (opens new window)
刚刚下载的镜像系统版本是 Centos 8,我的电脑架构是 x86,所以点击中间的 “Centos 8 --> EPEL x86_64” 进入详情页。
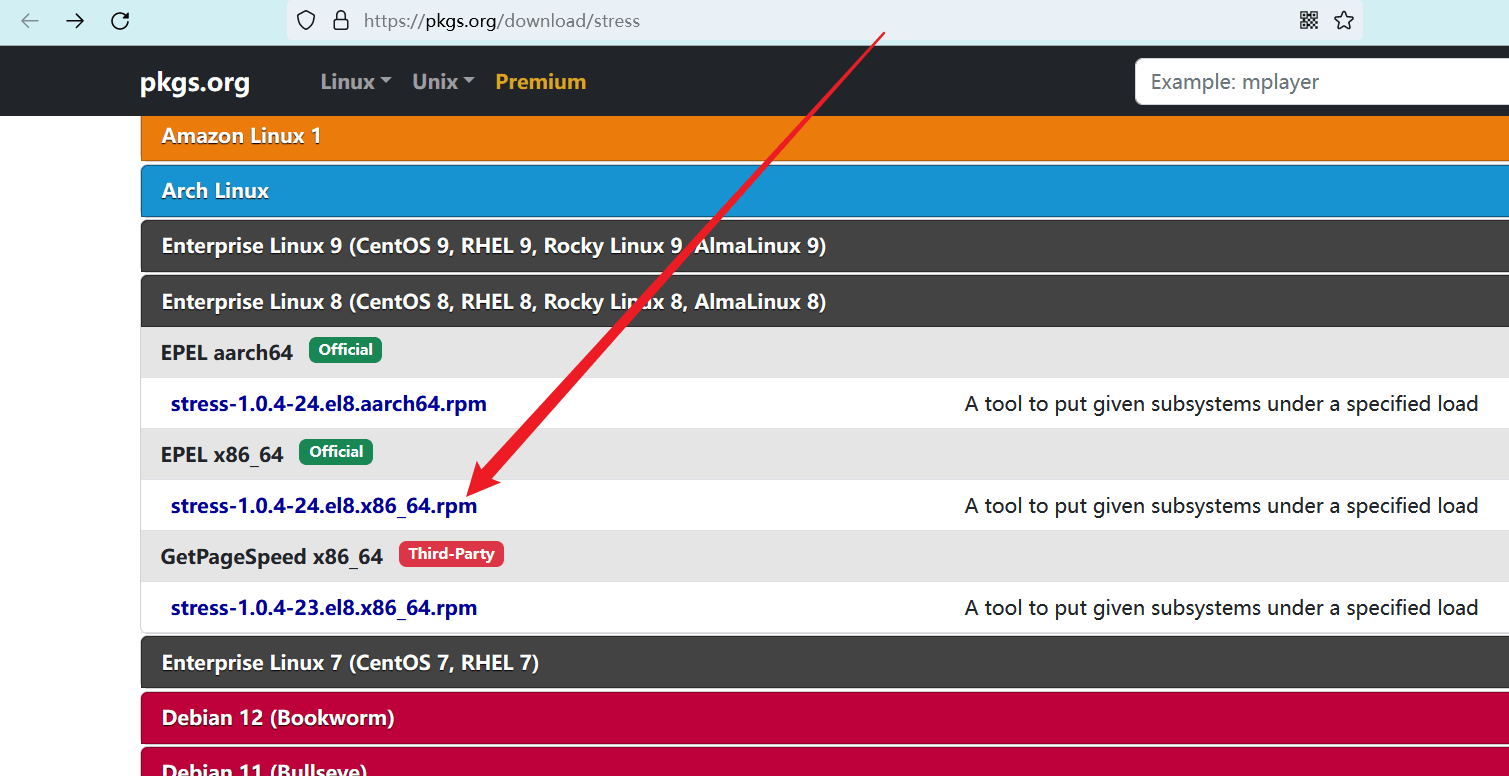
进入详情页后,在 “Download” 栏目中找到安装包下载链接。
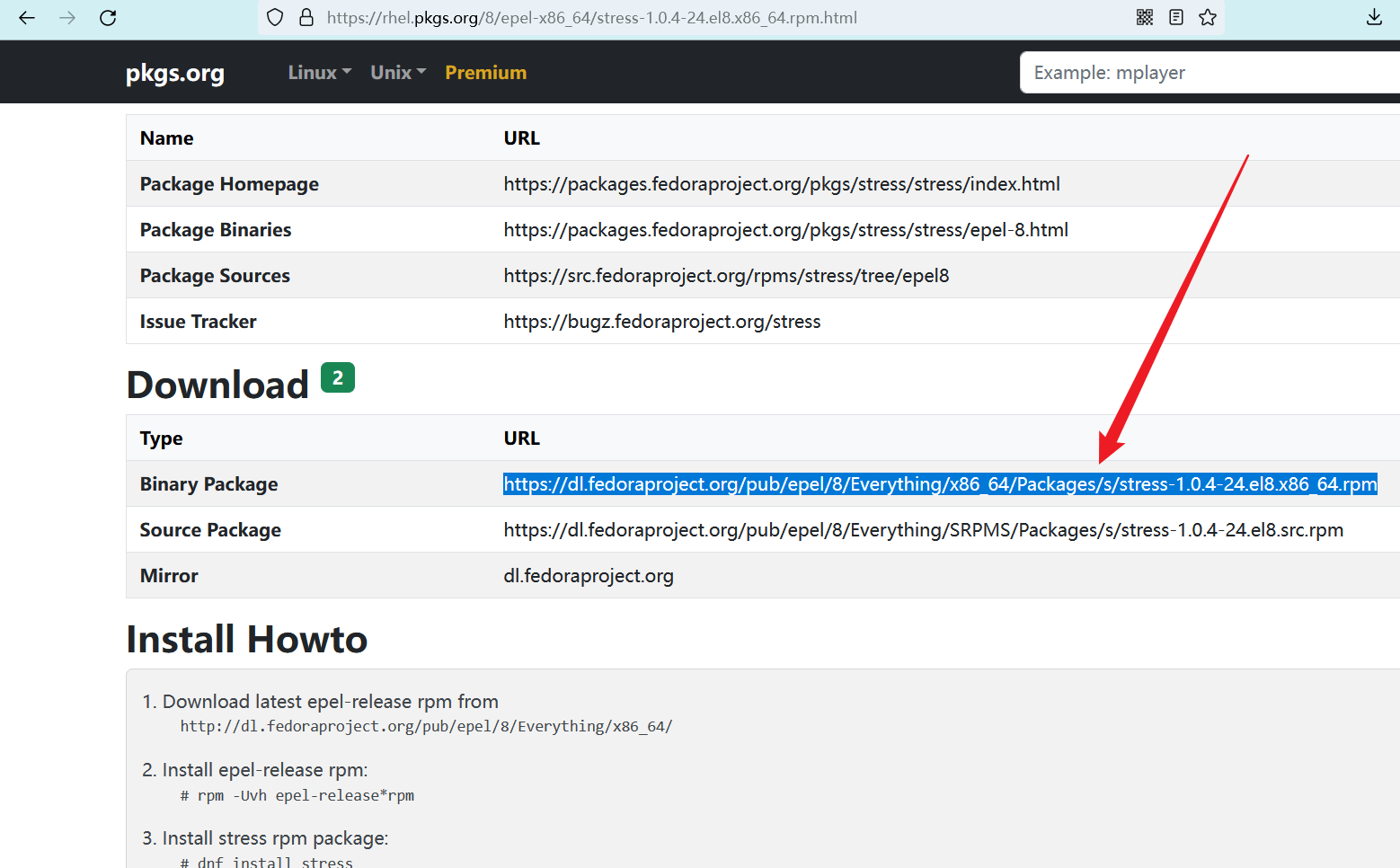
# 下载到 master 节点中
wget https://dl.fedoraproject.org/pub/epel/8/Everything/x86_64/Packages/s/stress-1.0.4-24.el8.x86_64.rpm
2
内存压力测试工具:点我下载
此处使用的工具是 memload,这工具贼难找,也不知道是不是绝迹了。在我的博客上面留个备份吧,反正也不大(6.5 KB)。
# 下载到 master 节点中
wget https://carsaid.github.io/cloud-native-security/kubernetes/memload-7.0-1.r29766.x86_64.rpm
2
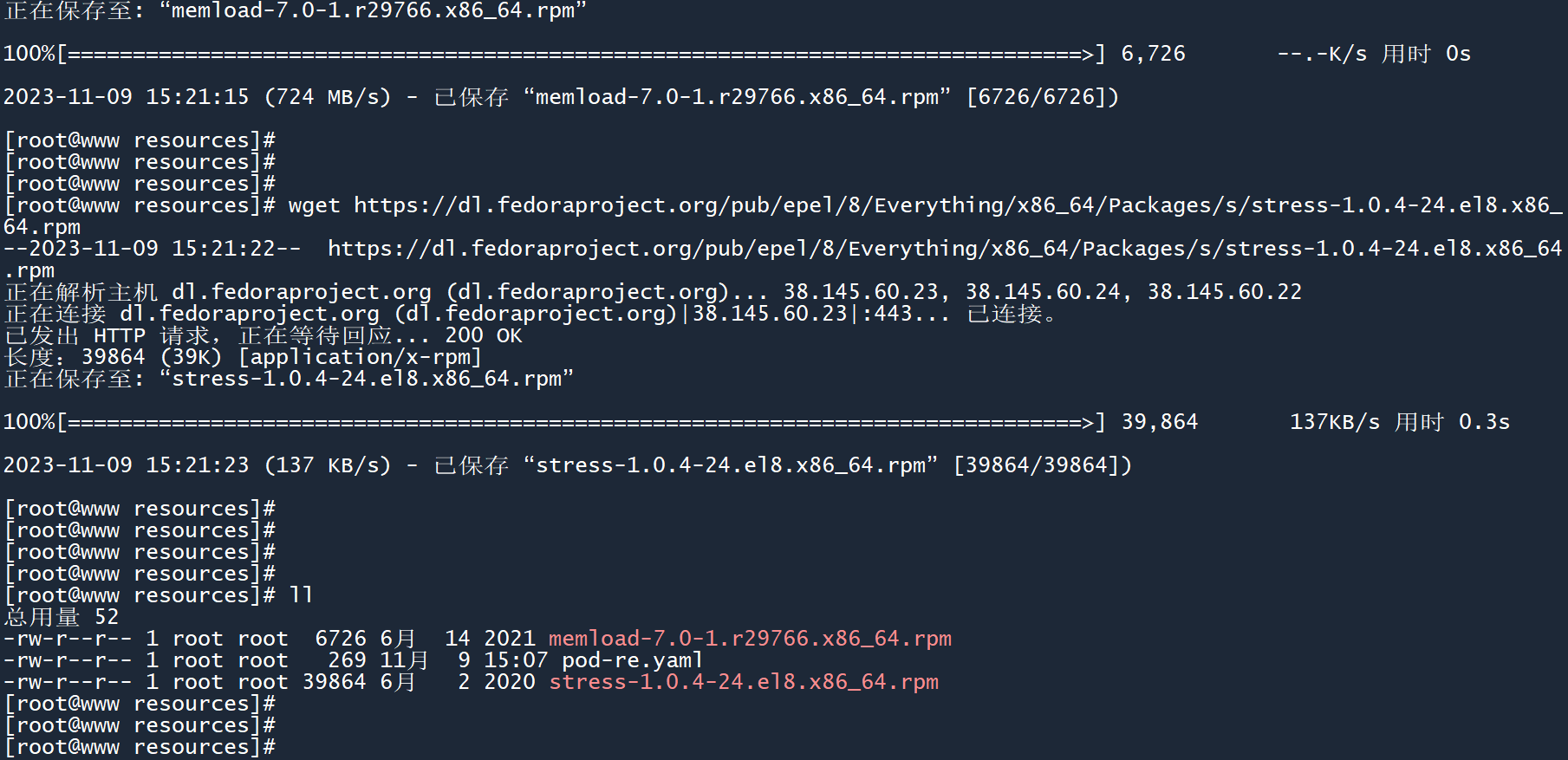
将这两个工具下载到 master 主机上。
# (3)没有资源限制时的压力测试
先创建一个没有资源限制的 Pod:
# pod-undo.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-undo
spec:
containers:
- image: centos
imagePullPolicy: IfNotPresent
name: pod-undo
command: ['sh', '-c', 'sleep 9999999']
2
3
4
5
6
7
8
9
10
11
创建 Pod,将两个工具安装包拷贝到容器中。
kubectl apply -f pod-undo.yaml
kubectl cp ./stress-1.0.4-24.el8.x86_64.rpm pod-undo:/opt/
kubectl cp ./memload-7.0-1.r29766.x86_64.rpm pod-undo:/opt/
2
3
4
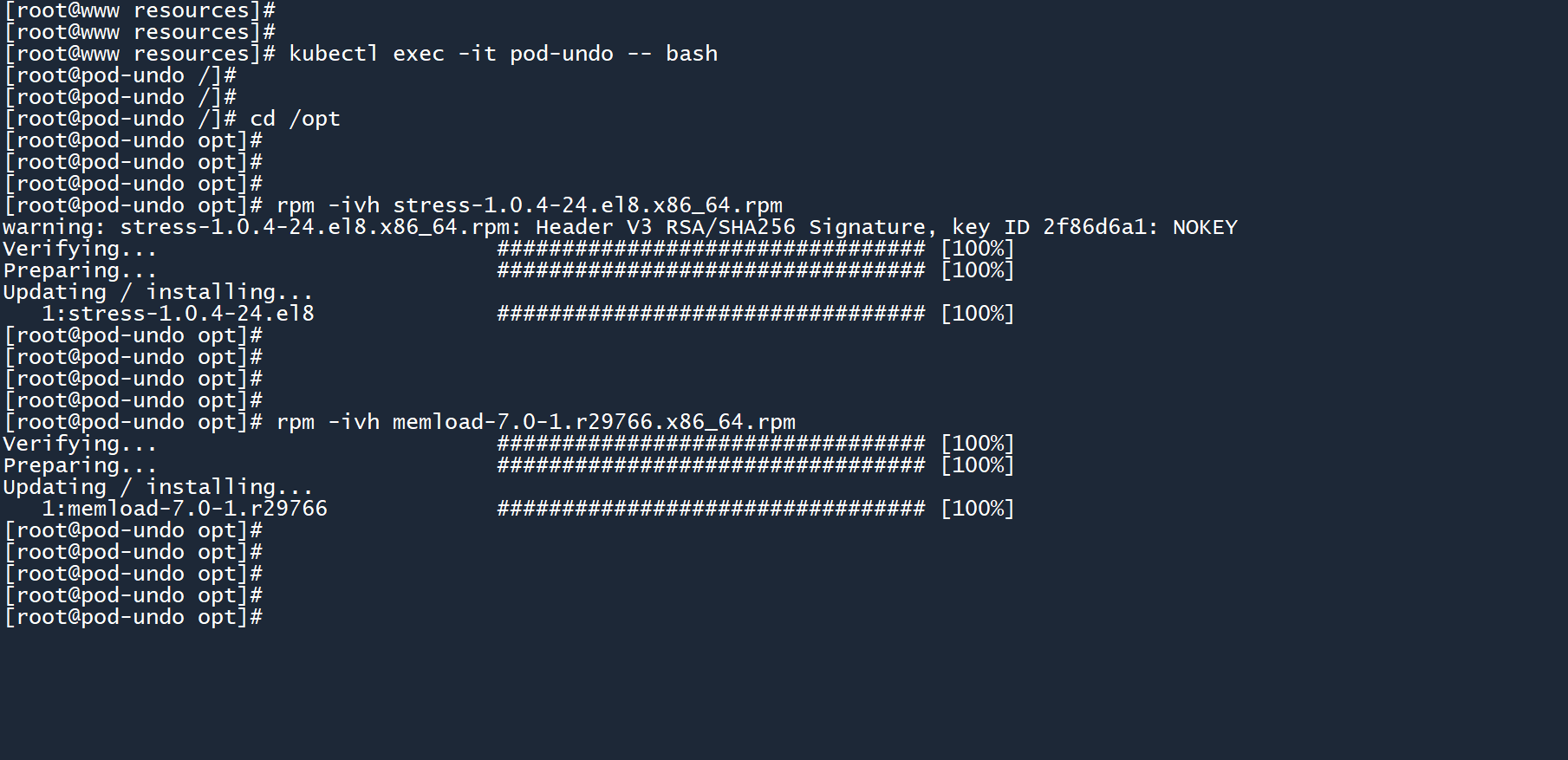
进入容器,然后通过rpm命令安装两个工具。
kubectl exec -it pod-undo -- bash
cd /opt
rpm -ivh stress-1.0.4-24.el8.x86_64.rpm
rpm -ivh memload-7.0-1.r29766.x86_64.rpm
2
3
4
5
在容器中运行memload工具,消耗 800M 内存进行压力测试,这将会模拟一个算力计算。
memload 800

由于运行压力测试工具期间,终端窗口无法动弹。所以此处另外开一个窗口并连接到 master 节点上,查看 Pod 负载信息。
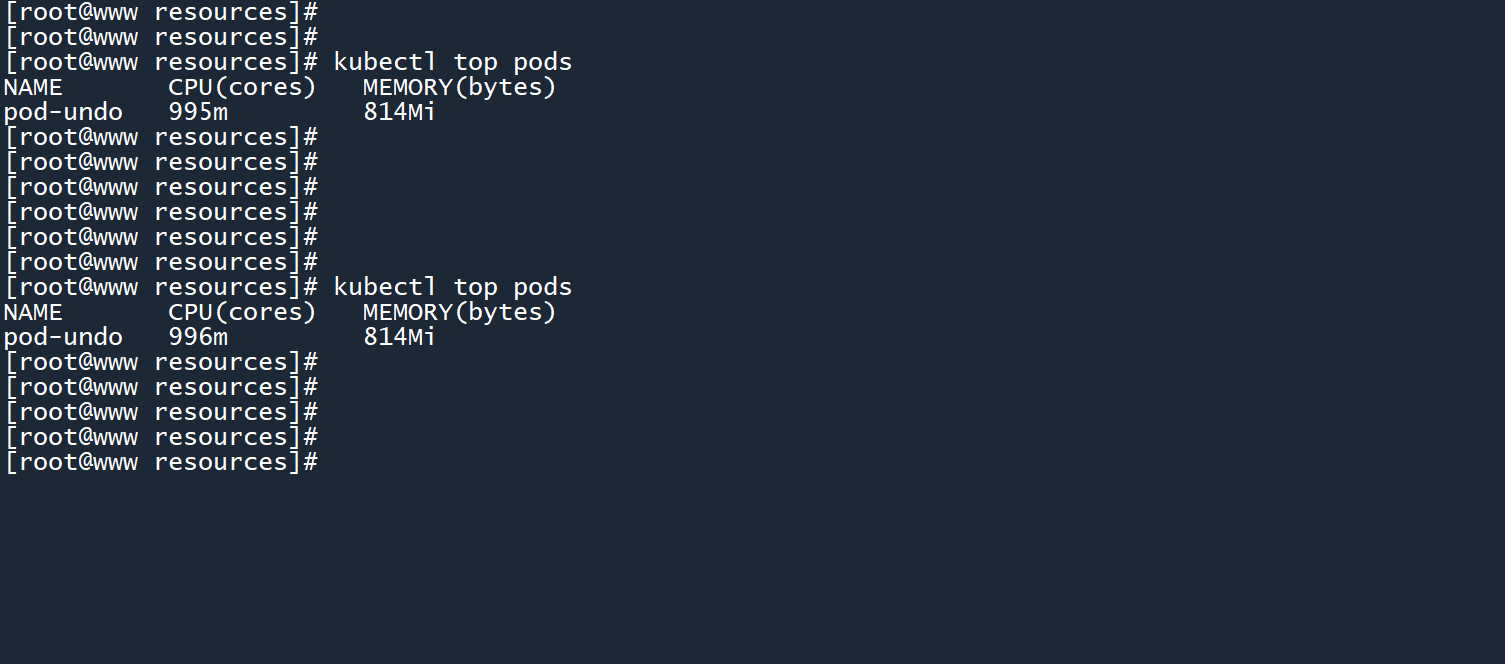
kubectl top pods
从图中可以看到,实际资源占用情况为996个 CPU 微核心和814 MiB 的内存。
回到前一个终端窗口,通过组合键Ctrl+C终止memload工具的运行。然后使用stress工具来消耗 8 个 CPU 核心(如果有那么多的话)进行压力测试。
stress --cpu 8

切换至另一个终端窗口,查看 Pod 负载信息。
kubectl top pods
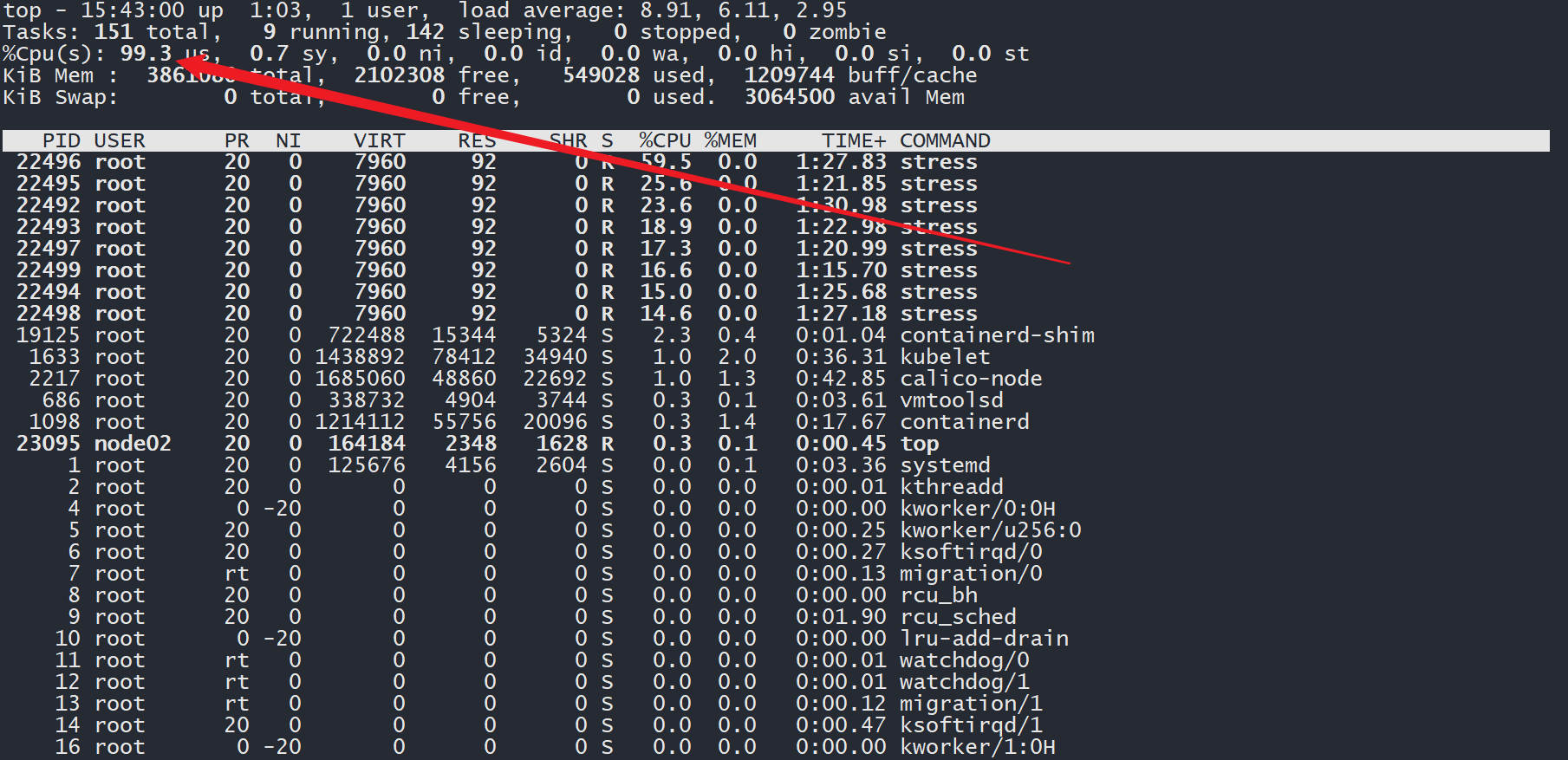
占用了1946个 CPU 微核心,大约等同于 2 个 CPU 核心。我这台虚拟机也才 2 个核心啊......

切换至 Pod 所在的节点,通过top命令查看资源使用情况,发现 CPU 使用率高达99.3%。
这要是一台真的服务器,估计早炸了。
# (4)存在资源限制时的压力测试
在原有 Pod 的基础上,添加resources.limits参数:
- 限制 CPU 使用上限为
300个微核心,也就是0.3个 CPU - 限制内存使用上限为
500MiB
# pod-do.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-do
spec:
containers:
- image: centos
imagePullPolicy: IfNotPresent
name: pod-do
command: ['sh', '-c', 'sleep 9999999']
resources:
limits:
cpu: 300m
memory: 500Mi
2
3
4
5
6
7
8
9
10
11
12
13
14
15
创建 Pod,将两个工具安装包拷贝到容器中。
kubectl apply -f pod-do.yaml
kubectl cp ./stress-1.0.4-24.el8.x86_64.rpm pod-do:/opt/
kubectl cp ./memload-7.0-1.r29766.x86_64.rpm pod-do:/opt/
2
3
4
进入容器,然后通过rpm命令安装两个工具。
kubectl exec -it pod-do -- bash
cd /opt
rpm -ivh stress-1.0.4-24.el8.x86_64.rpm
rpm -ivh memload-7.0-1.r29766.x86_64.rpm
2
3
4
5
在 pod-do 中运行内存压力测试工具,消耗 800M 内存:
memload 800
执行以上命令之后,你会发现一直提示 “Killed”,并且工具被自动中断。
这说明工具memload无法申请到 800M 的内存,内存限制生效了。
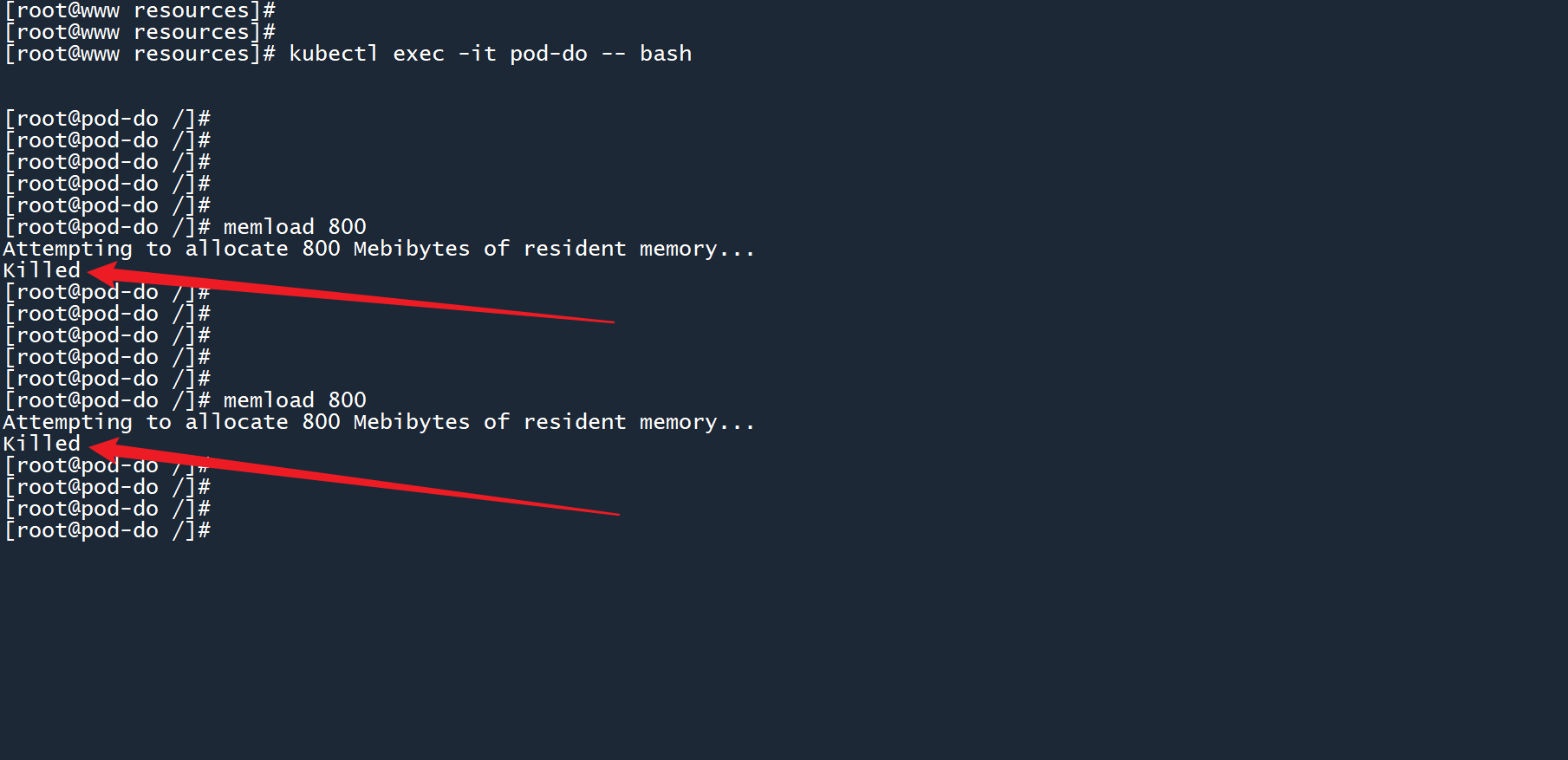
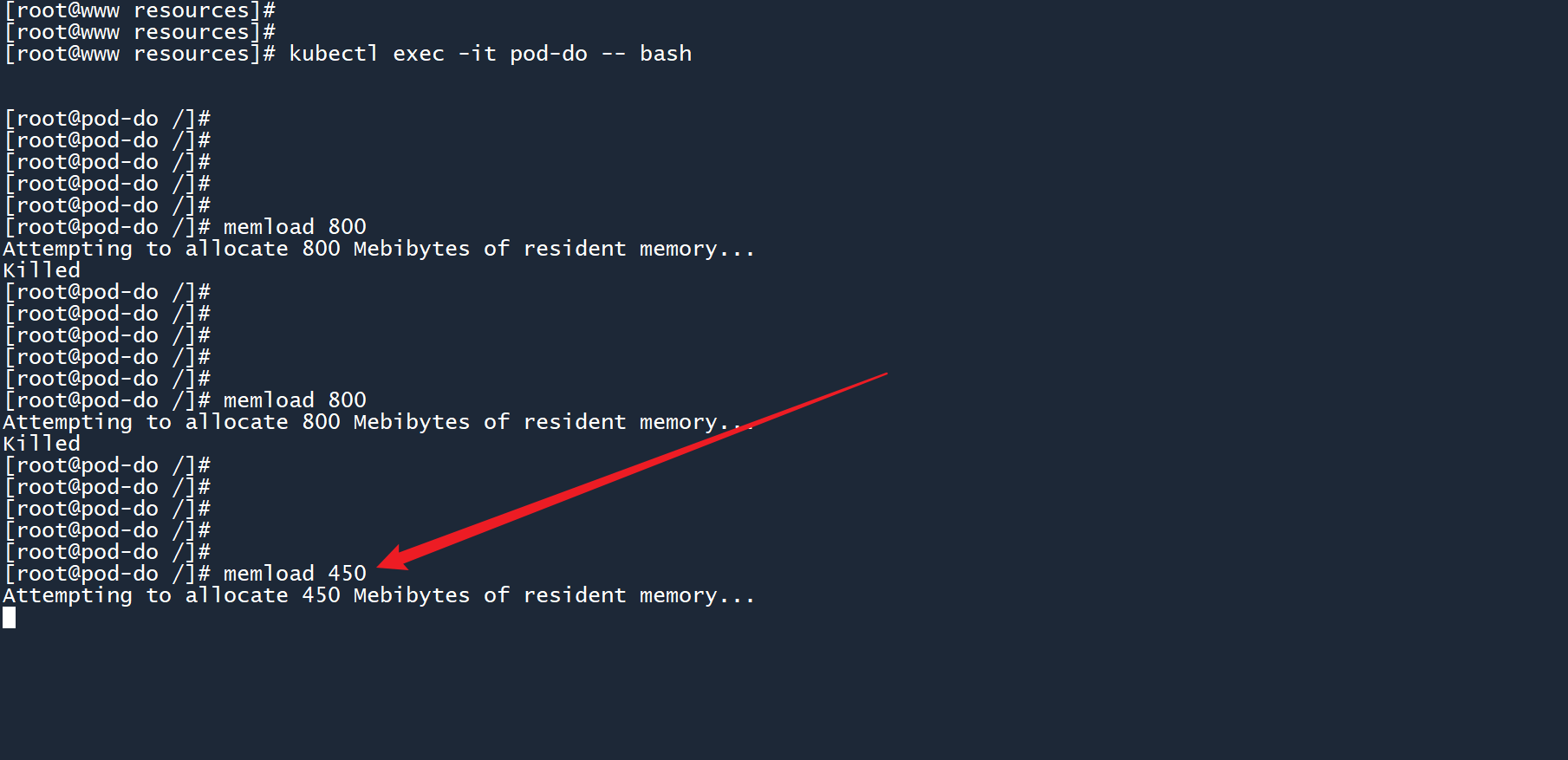
降低内存量,改为消耗 450M 内存:
memload 450
这次执行成功了。
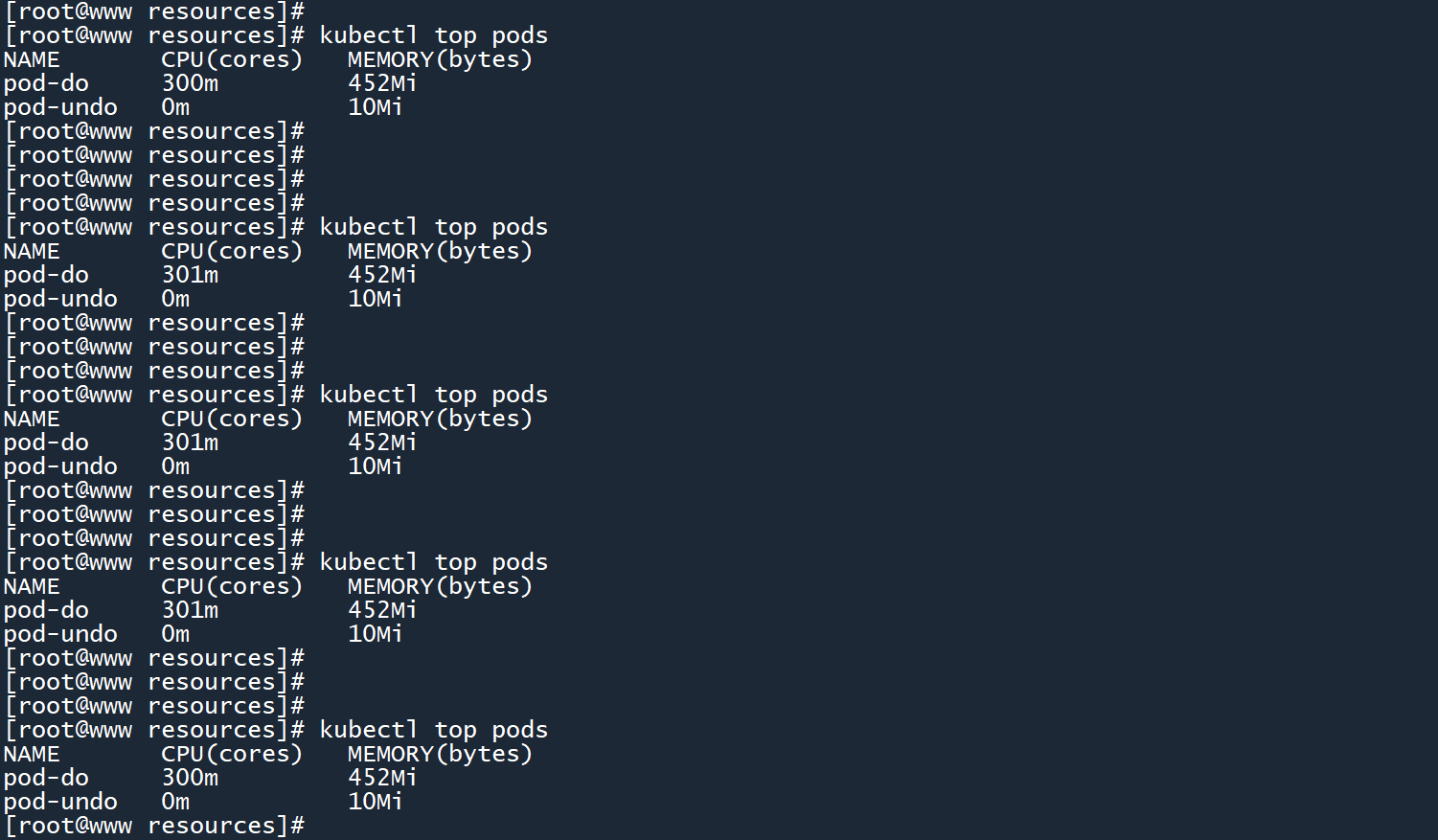
切换至另一个 master 连接窗口,查看 Pod 负载信息。
kubectl top pods
你会发现 CPU 一直被限制在300m,没有前一个 Pod 那么高的使用率。
同样是 CPU 杀手:
stress --cpu 8
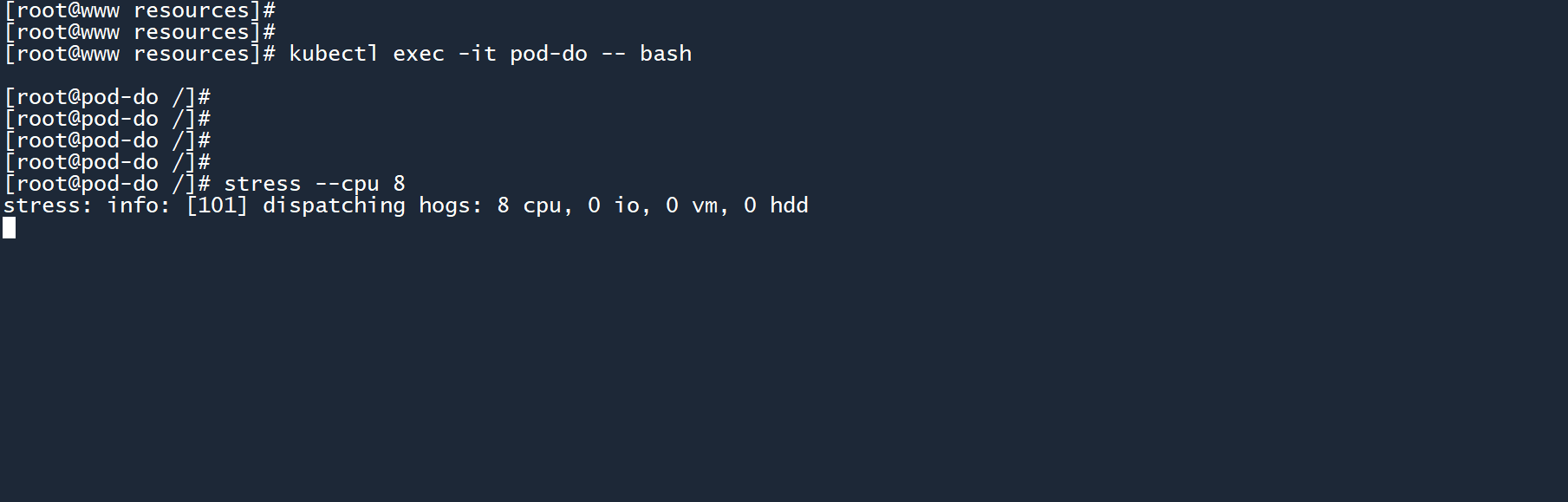
CPU 使用率还是乖乖地待在300m附近,没有严重超出。
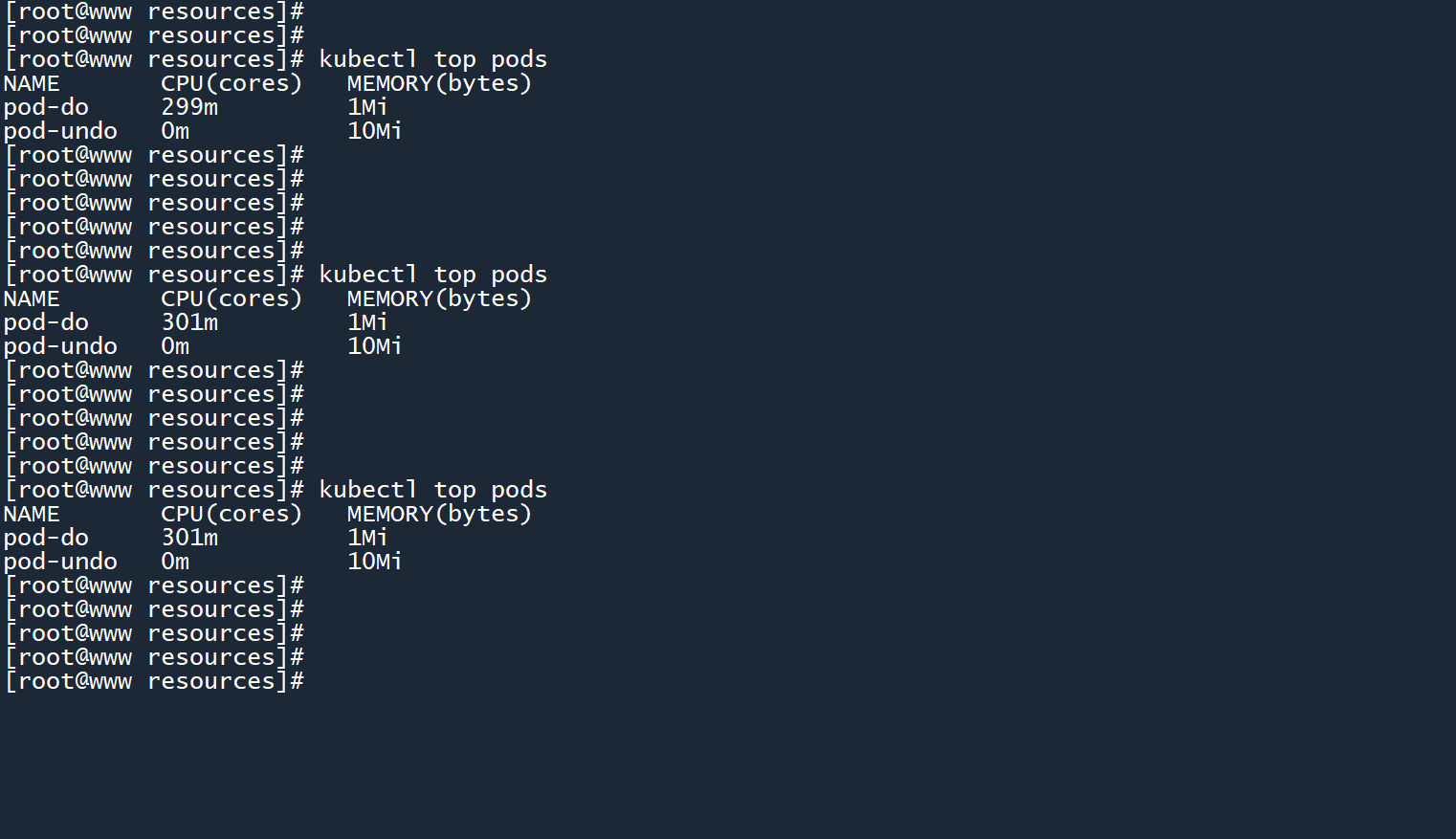
在 Pod 所处节点上运行top命令,查看主机资源使用率。CPU 使用率稳定徘徊在16%左右,没有之前那夸张的 90+% 了。
成功通过resources参数限制了 Pod/容器 的资源使用上限。
# 44. 通过LimitRange进行资源限制
虽然可以通过resources.limits参数对 Pod 进行资源限制,但是该参数需要单独为每个容器进行配置。Pod 数量一旦多起来,不仅配置繁琐、修改麻烦,还容易出错,工作量很大。
有没有一种办法,我只需要设置一次资源限制,就能自动应用到所有 Pod 当中呢?
这时候就需要用到 kubernetes 中的另一种资源类型:LimitRange
# 4.14.1 创建一个LimitRange
LimitRange 并不是某个参数,而是 k8s 中一个单独的资源类型,它也需要通过 yaml 文件来创建:
# limit1.yaml
apiVersion: v1
kind: LimitRange
metadata:
name: limit-range-1
spec:
limits:
- max:
cpu: 400m
memory: 512Mi
type: Container
2
3
4
5
6
7
8
9
10
11
和 Pod 一样,参数apiVersion用于指定 LimitRange 的 API 版本,一般也是固定的v1。
kind指定了当前 yaml 文件所要创建的 k8s 资源类型,此处为LimitRange。
metadata.name是当前资源的名称。
spec.limits.max用于限制资源使用上限。
spec.limits.type表示当前 LimitRange 限制的对象是谁,此处为Container,意思是对 “容器” 施加资源限制。
LimitRange 的创建方式和 Pod 一样:
kubectl apply -f limit1.yaml
kubectl get limitranges
2
3
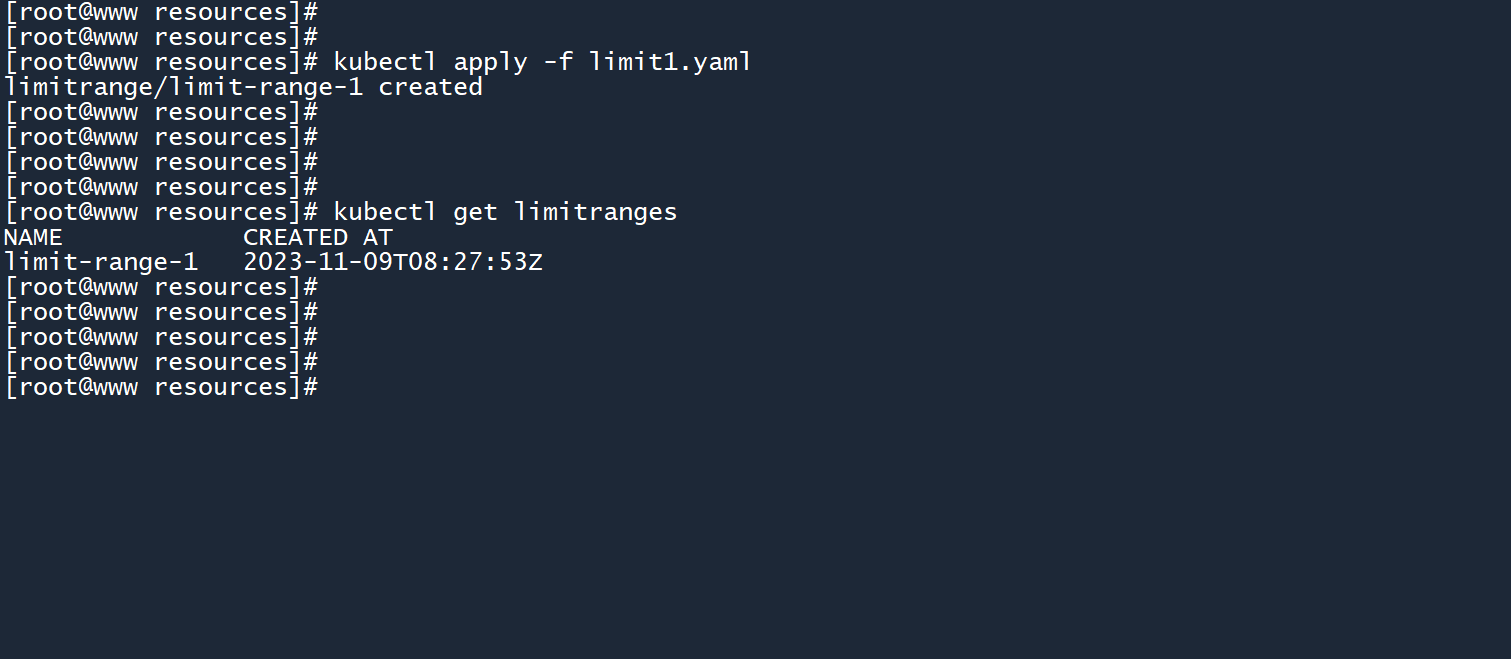
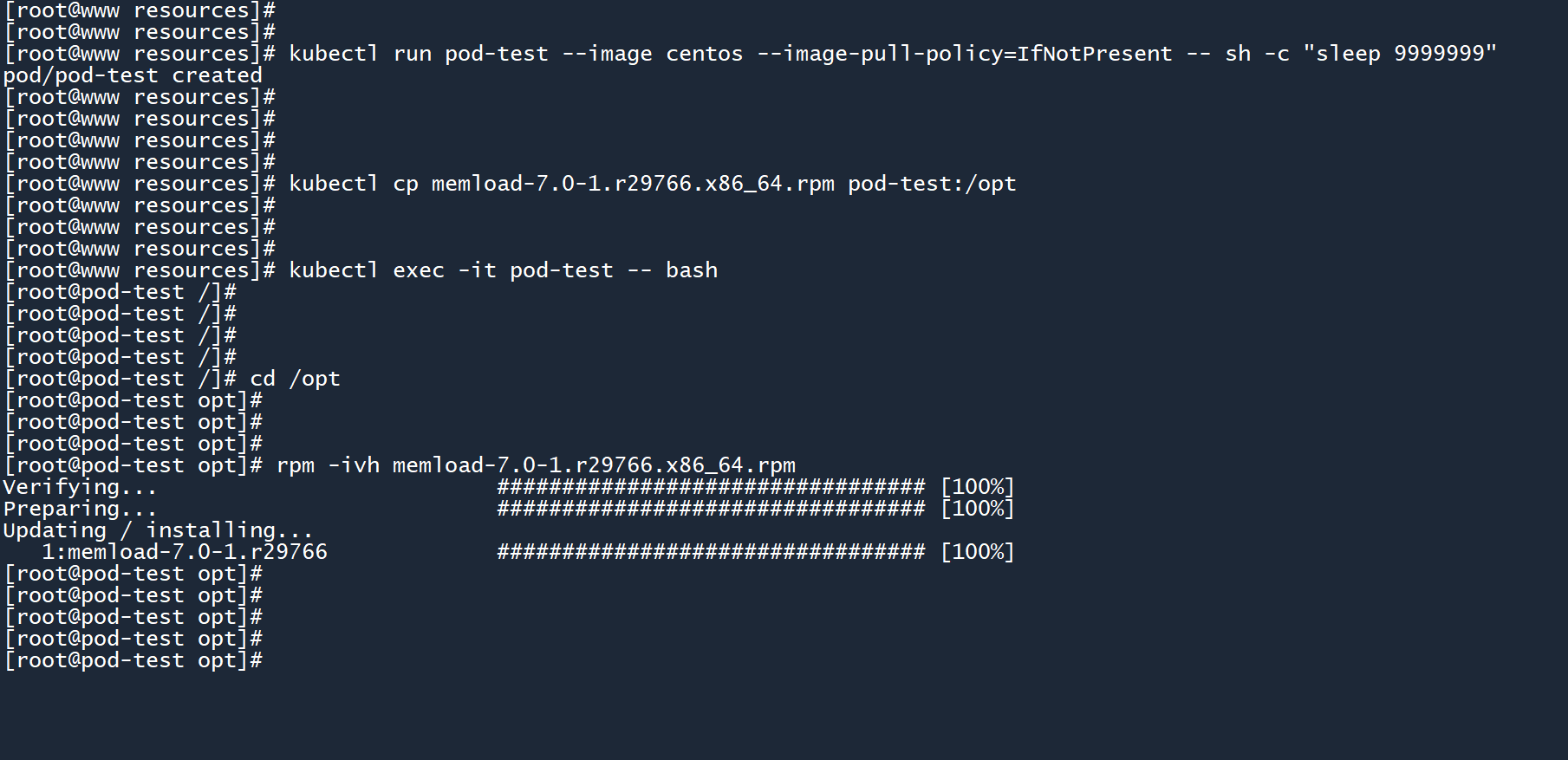
然后我们通过命令行创建一个 Pod,并在其中安装内存压力测试工具:
kubectl run pod-test --image centos --image-pull-policy=IfNotPresent -- sh -c "sleep 9999999"
kubectl cp memload-7.0-1.r29766.x86_64.rpm pod-test:/opt
kubectl exec -it pod-test -- bash
cd /opt
rpm -ivh memload-7.0-1.r29766.x86_64.rpm
2
3
4
5
6
尝试消耗 800M 内存,失败。改为消耗 480M 内存。
memload 800
memload 480
2
3

切换至另一个 master 终端窗口,查看 Pod 负载信息。
kubectl top pods
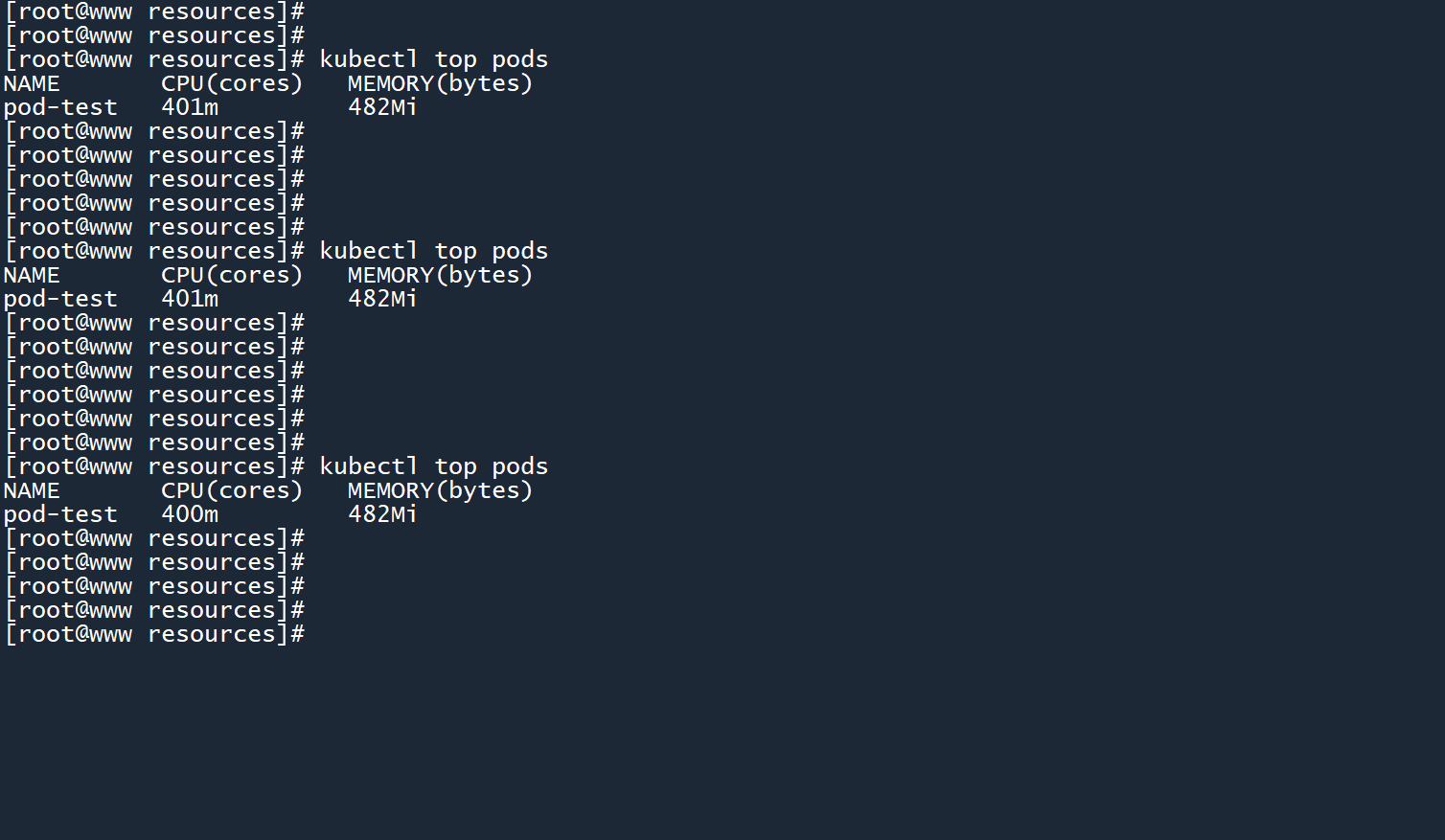
CPU 使用率被限制在400m。
成功通过 LimitRange 限制了容器的资源使用上限。
# 4.24.2 删除LimitRange
如果在 Pod 已经创建的情况下,把 LimitRange 给删除,资源限制策略还会存在吗?
kubectl delete limitranges limit-range-1
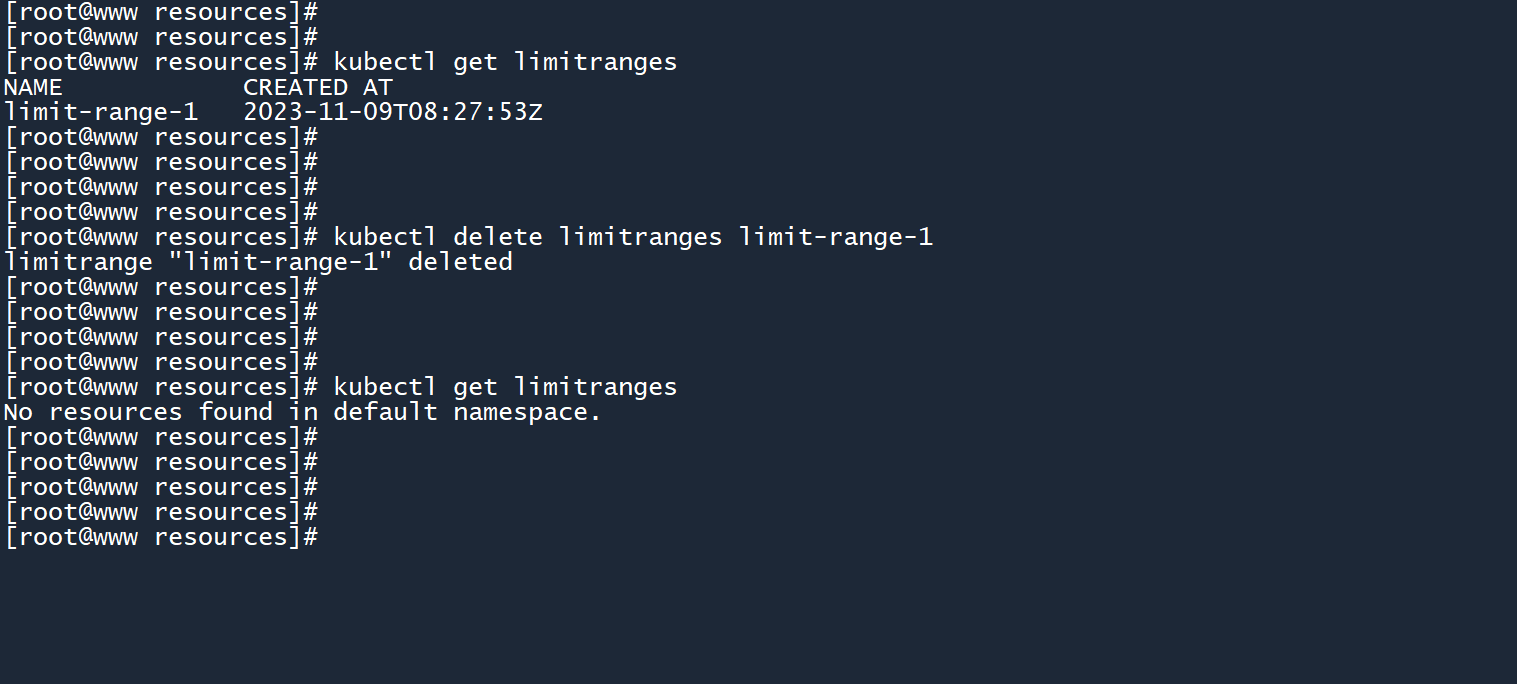
删除 LimitRange 之后,再次进入 pod-test 运行memload工具消耗 800M 内存。
memload 800
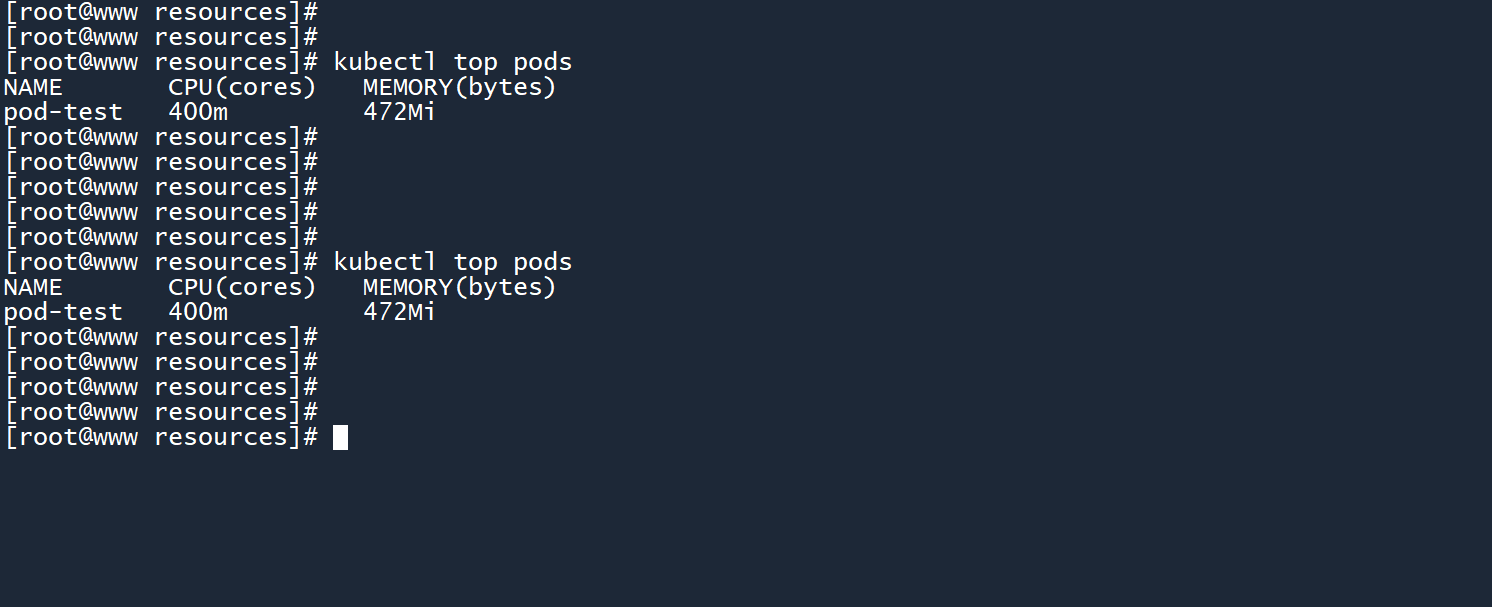
结果你会发现,消耗 800M 失败了!
那改为消耗 470M。

查看 Pod 负载信息,发现 CPU 使用率依旧被限制在400m。
这说明,即使 LimitRange 被删除了,之前创建的 Pod 依然会受到限制。
然后我新创建了一个 Pod,并尝试消耗 800M 内存,成功了。
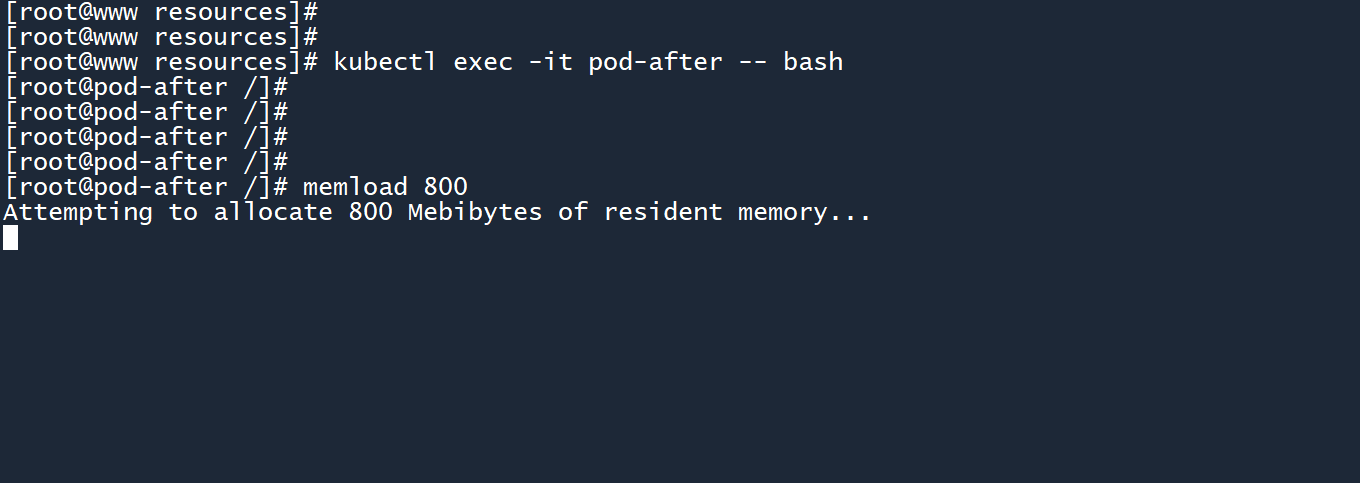
资源使用率也同样是飙升。

笔记
当 LimitRange 存在时,每一个新创建的 Pod 都会被施加资源限制策略。即使该 LimitRange 之后被删除了,资源限制策略也会一直作用于这些 Pod。
LimitRange 只会对新创建的 Pod 施加资源限制策略,在 LimitRange 创建之前已经存在的 Pod 不会被施加策略。
如图所示,pod-after在 LimitRange 之前就已经创建,但依然能够消耗 800M 的内存。
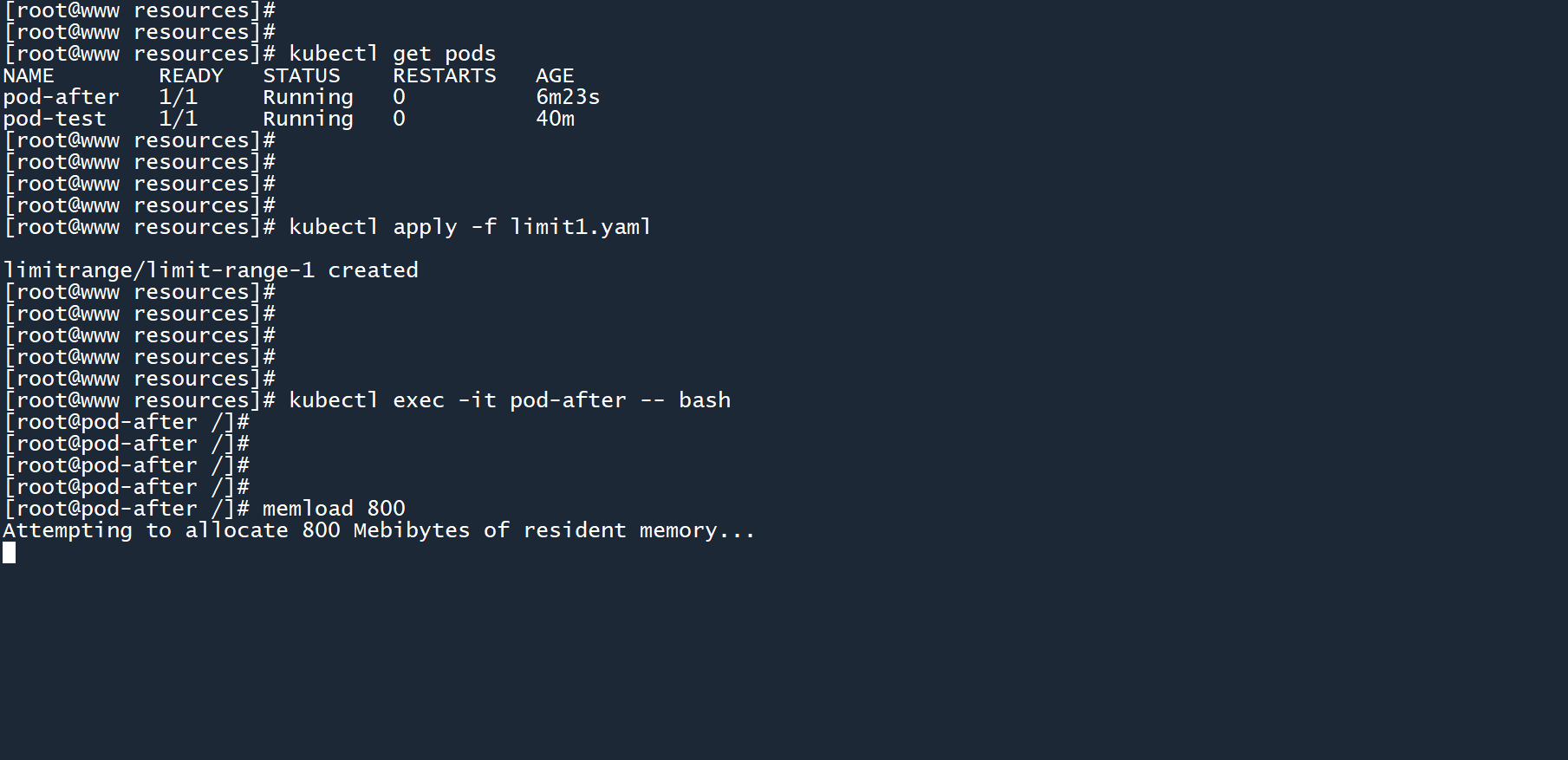
# 4.34.3 LimitRange作用范围
上面创建的 LimitRange 位于命名空间default,它能否作用于其他命名空间呢?
此时,命名空间default中已经创建了一个名为limit-range-1的 LimitRange。
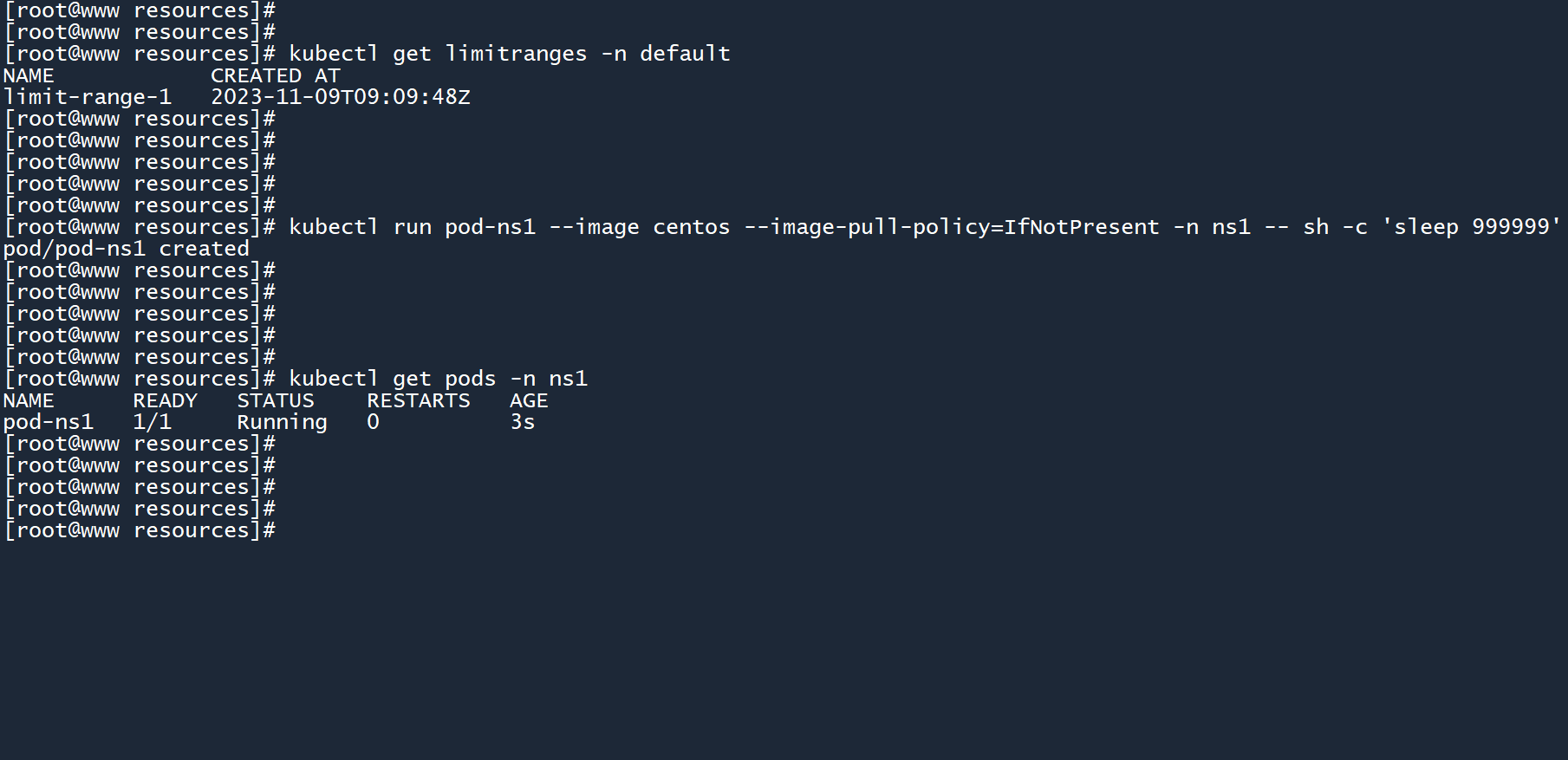
然后,在命名空间ns1中创建一个名为pod-ns1的新 Pod,看看资源限制策略能否应用到该 Pod 中。
kubectl run pod-ns1 --image centos --image-pull-policy=IfNotPresent -n ns1 -- sh -c 'sleep 999999'
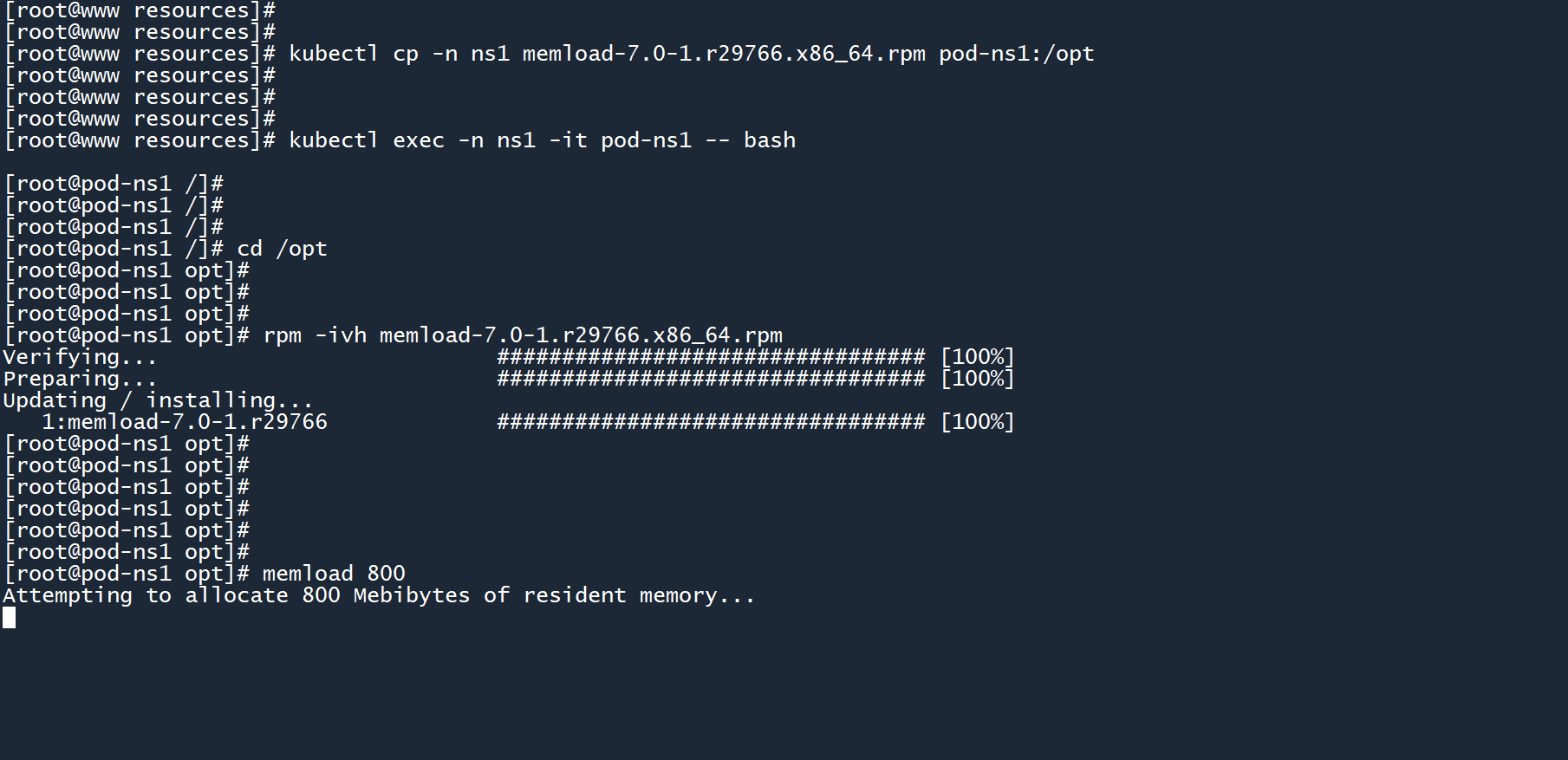
在 Pod 中安装内存压力测试工具,并尝试消耗 800M 内存。
kubectl cp -n ns1 memload-7.0-1.r29766.x86_64.rpm pod-ns1:/opt
kubectl exec -n ns1 -it pod-ns1 -- bash
cd /opt
rpm -ivh memload-7.0-1.r29766.x86_64.rpm
memload 800
2
3
4
5
6
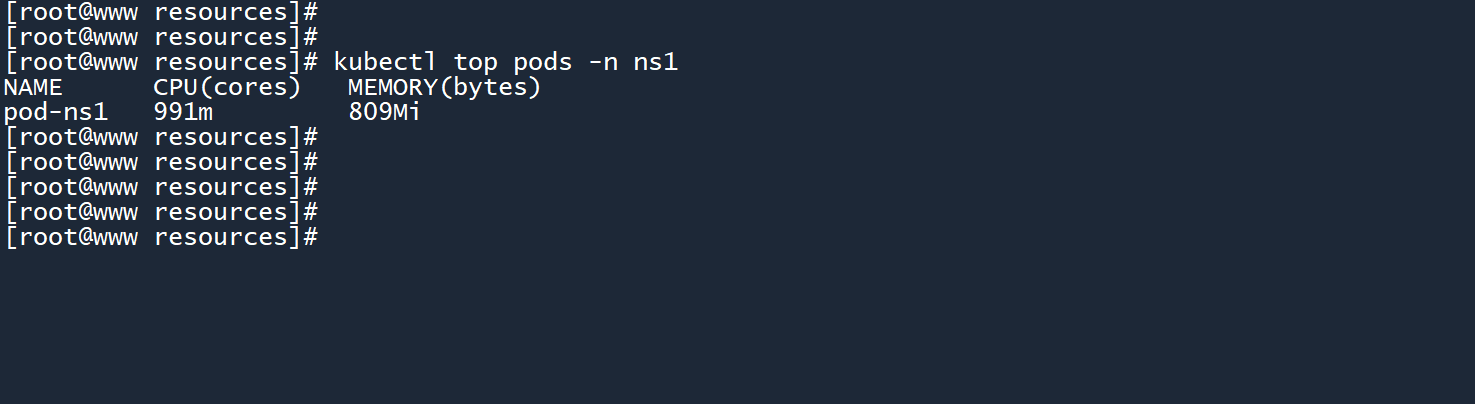
消耗成功了。
可以看到pod-ns1没有被施加资源限制策略。
笔记
LimitRange 只能对当前命名空间中的 k8s 资源施加限制策略,对其他命名空间不起效果。
最后,删除这个 LimitRange,防止影响后续实验。
kubectl delete -f limit1.yaml
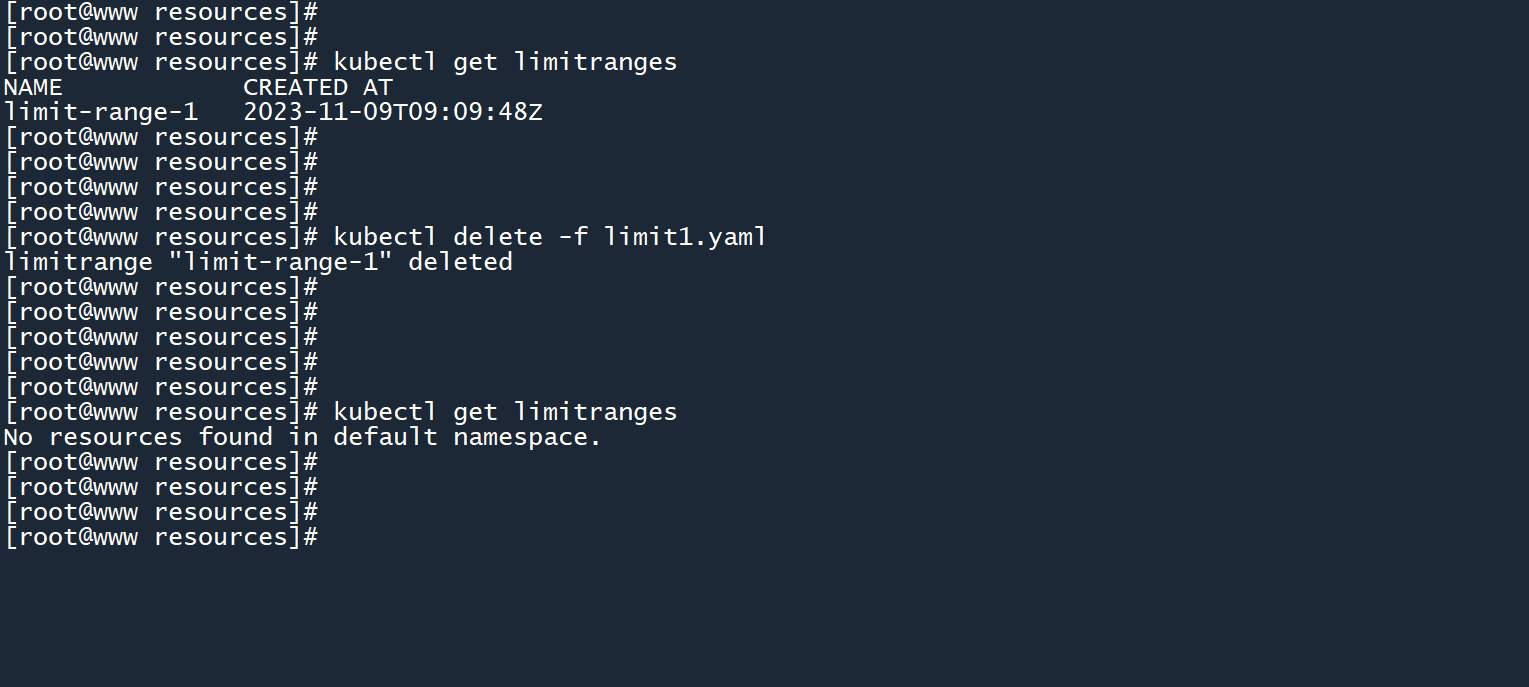
# 4.44.4 LimitRange作用对象
在以上 yaml 文件中,我们通过spec.limits.type: Container指定了资源限制对象为 “容器”。
除了容器之外,LimitRange 还可以用于限制其他 k8s 资源对象。这将在后续的章节中进行介绍。
# 55. 通过ResourceQuota实现资源调度上限
参数spec.containers.resources用于限制单个容器中的资源使用上限。
集群 LimitRange 用于在单个命名空间中,限制某个集群对象的资源使用上限。
而 ResourceQuota 用于在单个命名空间中,限制某个集群对象的数量。
# 5.15.1 创建一个ResourceQuota
多说无益,来看个示例吧。创建以下 yaml 文件:
# re-quota.yaml
apiVersion: v1
kind: ResourceQuota
metadata:
name: re-quota
spec:
hard:
pods: 2
2
3
4
5
6
7
8
参数apiVersion和metadata.name应该很熟悉了吧,不多讲。
kind指定当前 yaml 文件所要创建的集群资源类型,此处为ResourceQuota。
spec.hard用于设置集群资源调度上限。参数pods: 2的意思是——当前命名空间中,最多只能存在 2 个 Pod。
# 创建ResourceQuota
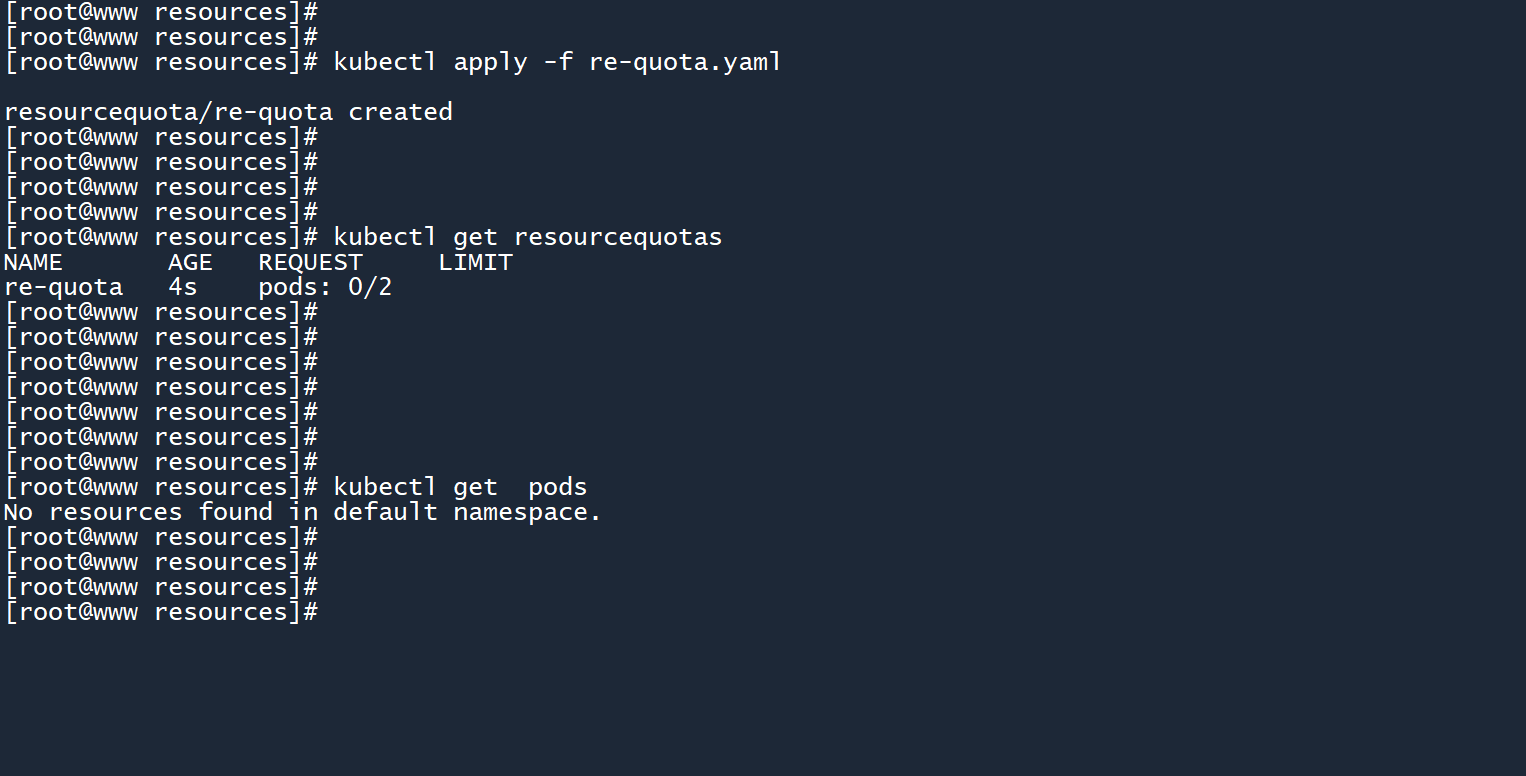
kubectl apply -f re-quota.yaml
kubectl get resourcequotas
2
3
4
可以看到条目pods: 0/2,意思是当前命名空间存在0个 Pod,上限为2个 Pod。
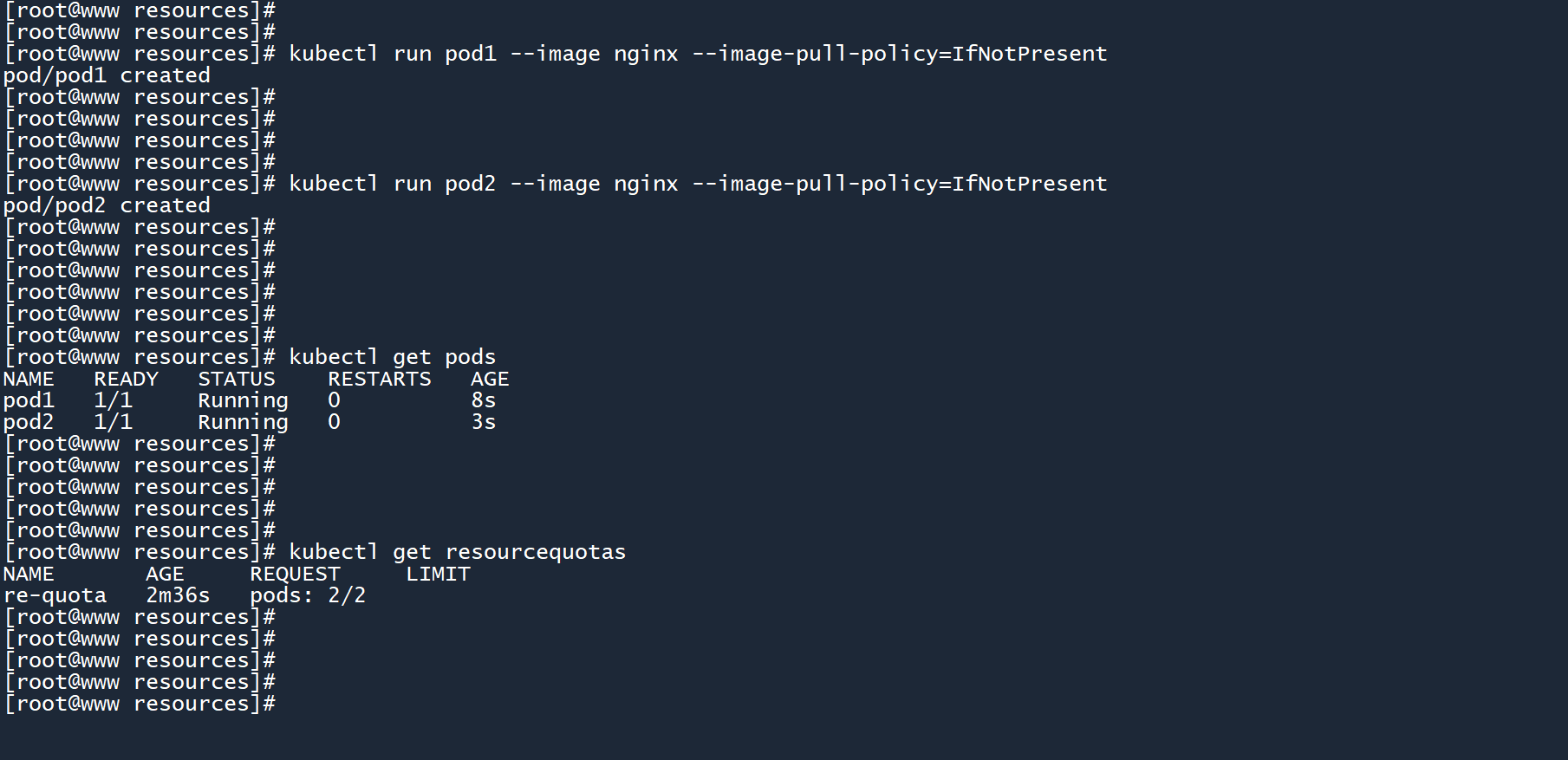
通过命令行创建两个 Pod:
kubectl run pod1 --image nginx --image-pull-policy=IfNotPresent
kubectl run pod2 --image nginx --image-pull-policy=IfNotPresent
2
此时re-quota的上限来到了2/2,如果再创建一个 Pod 会发生什么?
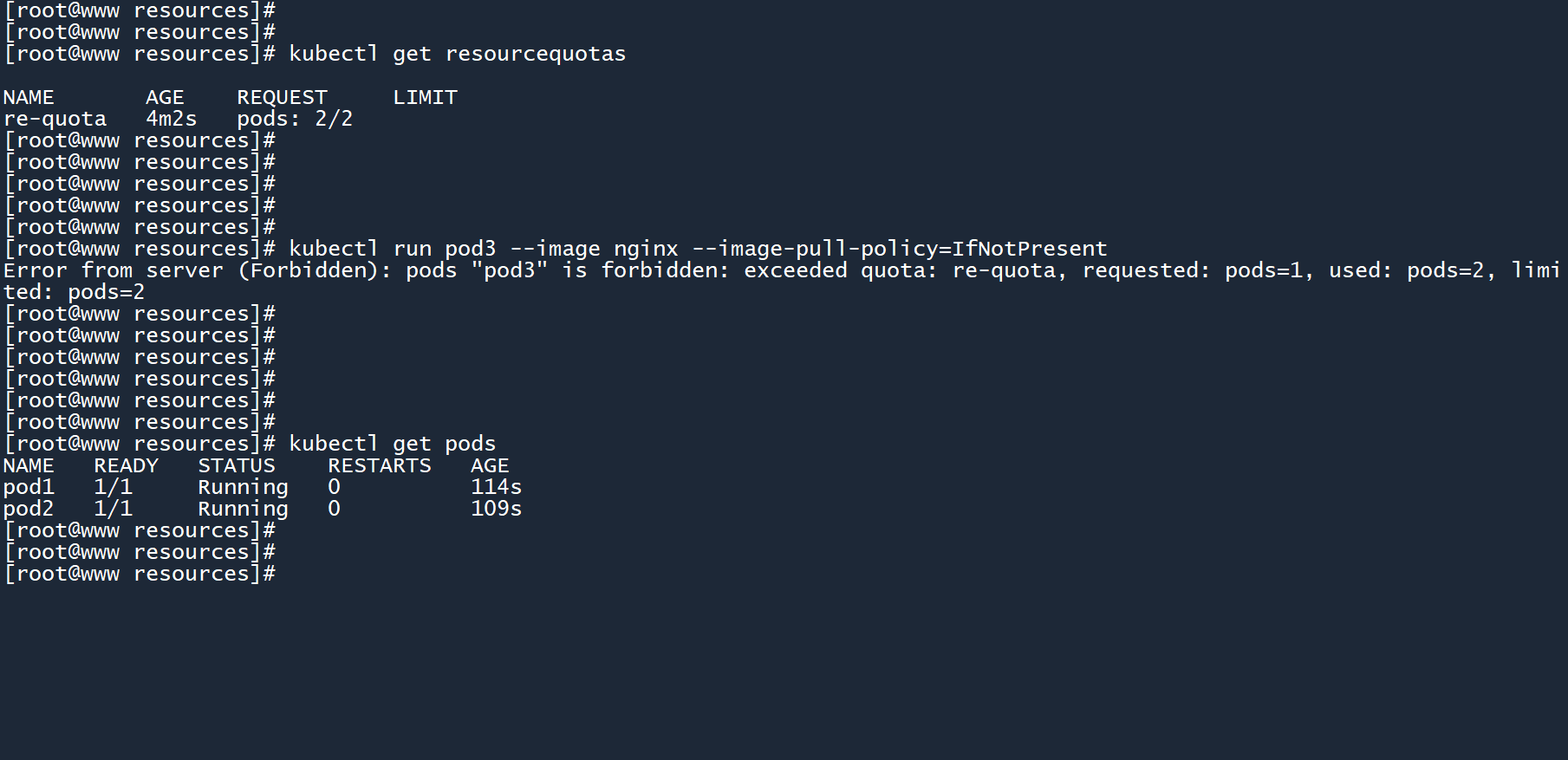
说干就干,创建第三个 Pod。
kubectl run pod3 --image nginx --image-pull-policy=IfNotPresent
创建失败,超出了re-quota的配额,上限为pods=2(最多两个 Pod)。
# 5.25.2 删除ResourceQuota
删除re-quota,并创建第三个 Pod。
kubectl delete -f re-quota.yaml
kubectl run pod3 --image nginx --image-pull-policy=IfNotPresent
2
3
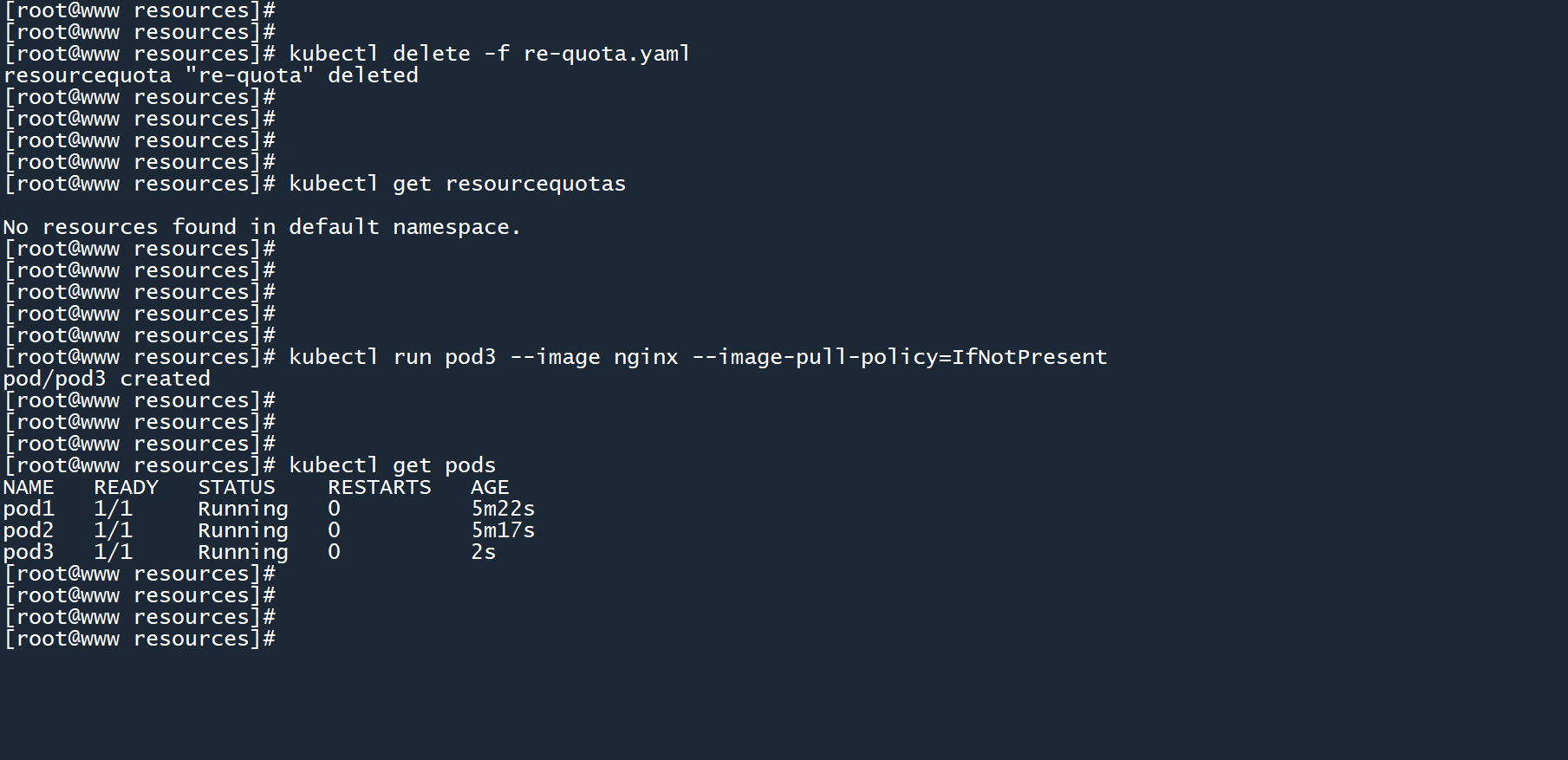
此时已经有三个 Pod 存在,如果再次创建re-quota并把 Pod 上限设置为2个,会发生什么?
kubectl apply -f re-quota.yaml
可以看到条目pods: 3/2,Pod 的数量超出了配额,但是 Pod 依然正常运行。
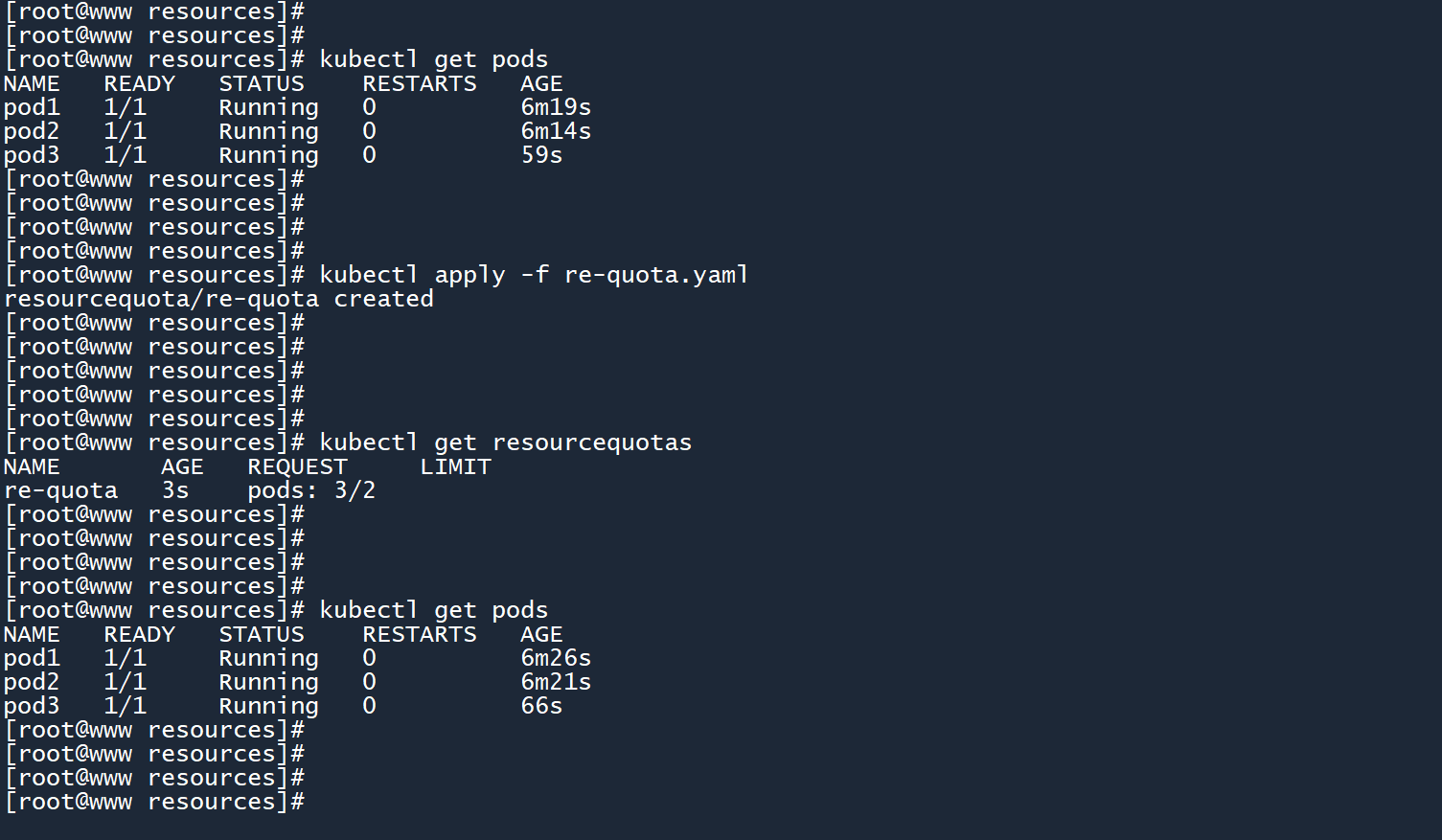
笔记
和 LimitRange 一样,ResourceQuota 只会作用于后续新创建的 Pod,不会对已创建的 Pod 造成影响。
# 5.35.3 ResourceQuota作用范围
和 LimitRange 一样,ResourceQuota 只在单个命名空间中生效。
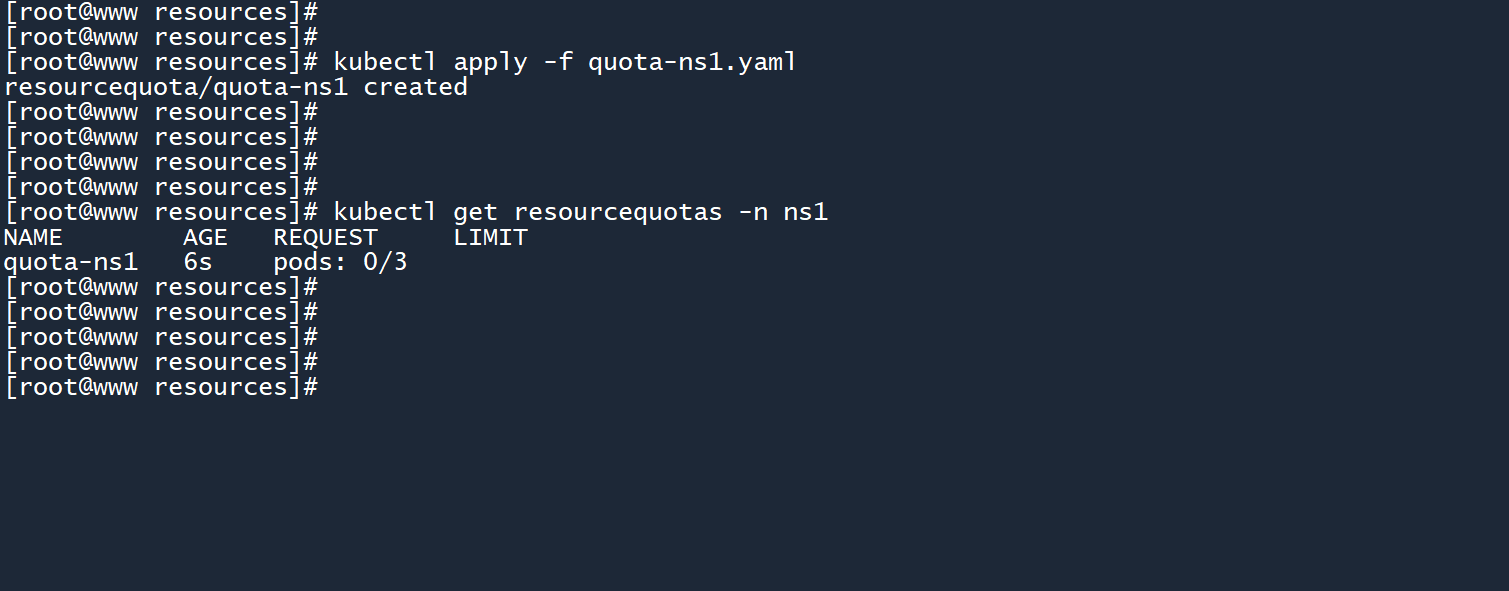
如果你想在其他命名空间中实现资源配额,则需要在对应的命名空间中创建新的 ResourceQuota。你可以在 yaml 文件中添加metadata.spacename参数来实现。例如:
apiVersion: v1
kind: ResourceQuota
metadata:
name: quota-ns1
namespace: ns1
spec:
hard:
pods: 3
2
3
4
5
6
7
8
最后,记得删除这些 ResourceQuota,防止影响后续实验。
kubectl delete -f re-quota.yaml
# 如果有的话
kubectl delete -f quota-ns1.yaml
2
3
4
# 66. kubectl explain命令
现在介绍这个命令正合时宜。
# 6.16.1 yaml文件的参数复杂性
上一章学习了 Pod,以及通过 yaml 文件创建 Pod 的方式,一个简单的 yaml 文件可能看起来像这样:
apiVersion: v1
kind: Pod
metadata:
name: pod-test
spec:
containers:
- image: nginx
imagePullPolicy: IfNotPresent
name: pod-test
2
3
4
5
6
7
8
9
虽然看起来简单,但是创建 Pod 的参数可不止那么一点,诸如metadata.labels、metadata.namespace之类的参数可能会经常用到。还有本章刚刚才学习过的spec.container.lifecycle和spec.containers.resources。
除了 Pod 之外,本章又学习了两个新的集群资源,它们的 yaml 文件长这样:
# 一个LimitRange
apiVersion: v1
kind: LimitRange
metadata:
name: my-limit
spec:
limits:
- max:
cpu: 300m
memory: 1Gi
type: Container
2
3
4
5
6
7
8
9
10
11
# 一个ResourceQuota
apiVersion: v1
kind: ResourceQuota
metadata:
name: my-quota
spec:
hard:
pods: 3
2
3
4
5
6
7
8
随着学习的深入,接触的集群资源和 yaml 文件参数也越来越多。
- 对于一个资深 k8s 专家来说,也许他可以记住所有的配置参数。
- 但对于一个刚入门的小白来说,如何记住这么庞大的内容呢?
多学?多背?多练?多写写 yaml 文件?
# 6.26.2 yaml配置参数查询
其实 k8s 提供了一个命令kubectl explain,可以用来查询 yaml 配置参数。
例如,我想知道一个 Pod 的 yaml 文件是由哪几个部分组成的,可以运行以下命令:
kubectl explain pod
列出了五个字段,字段名称的右边标注了字段类型。例如apiVersion是一个字符串,metadata是一个对象,spec是 Pod 策略。
而在字段的上方,k8s 很贴心地标注了KIND: Pod和VERSION: v1,以此来提醒你资源类型应该写成Pod,而 API 版本应该写成v1。
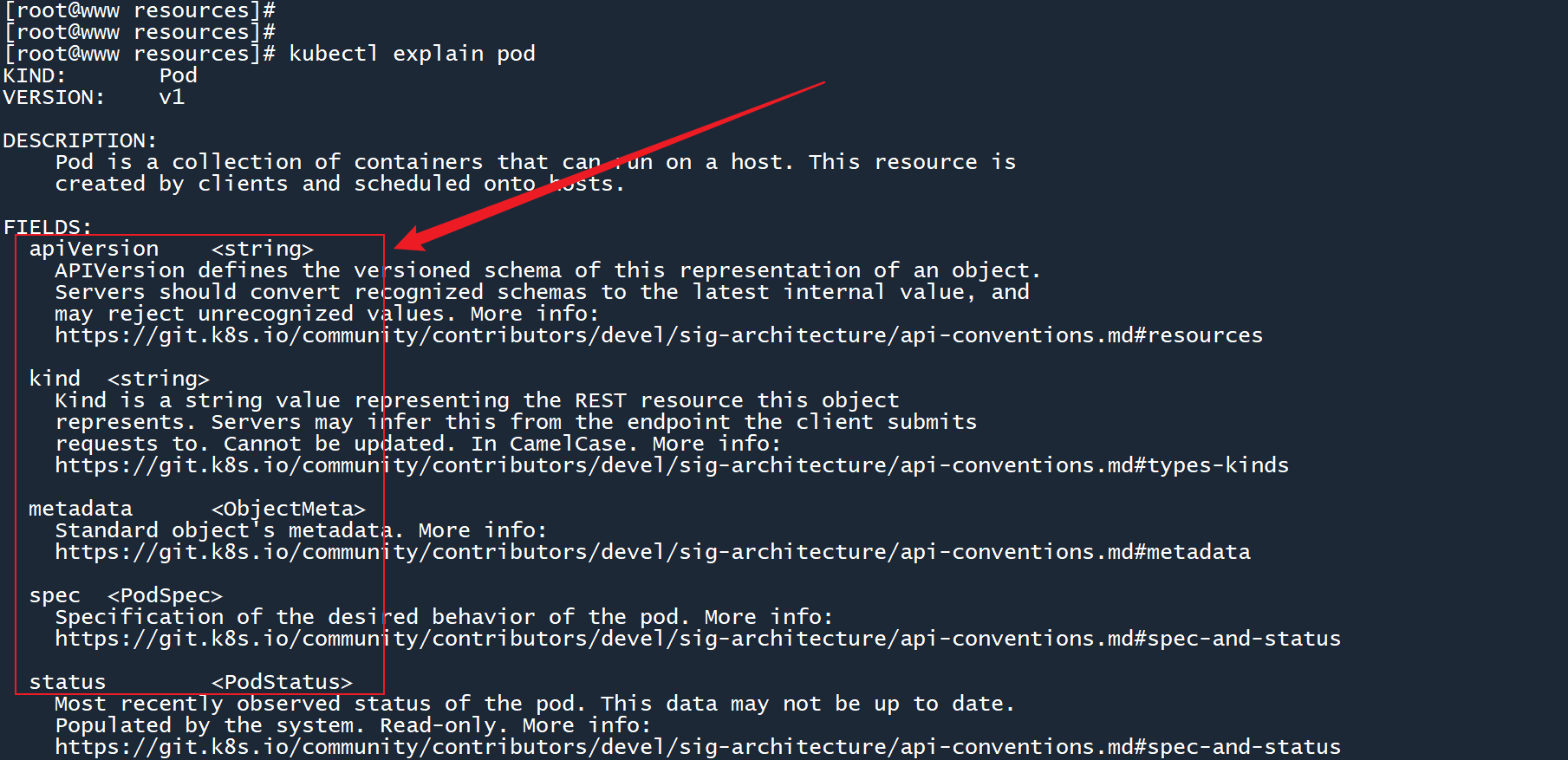
如果我想看 Pod 的spec字段下面有什么呢?只需要用点.隔开每个字段即可,就像这样:
kubectl explain pod.spec
和上个命令一样,列出了spec下的所有可用字段。在其中我们可以看到熟悉的spec.containers。
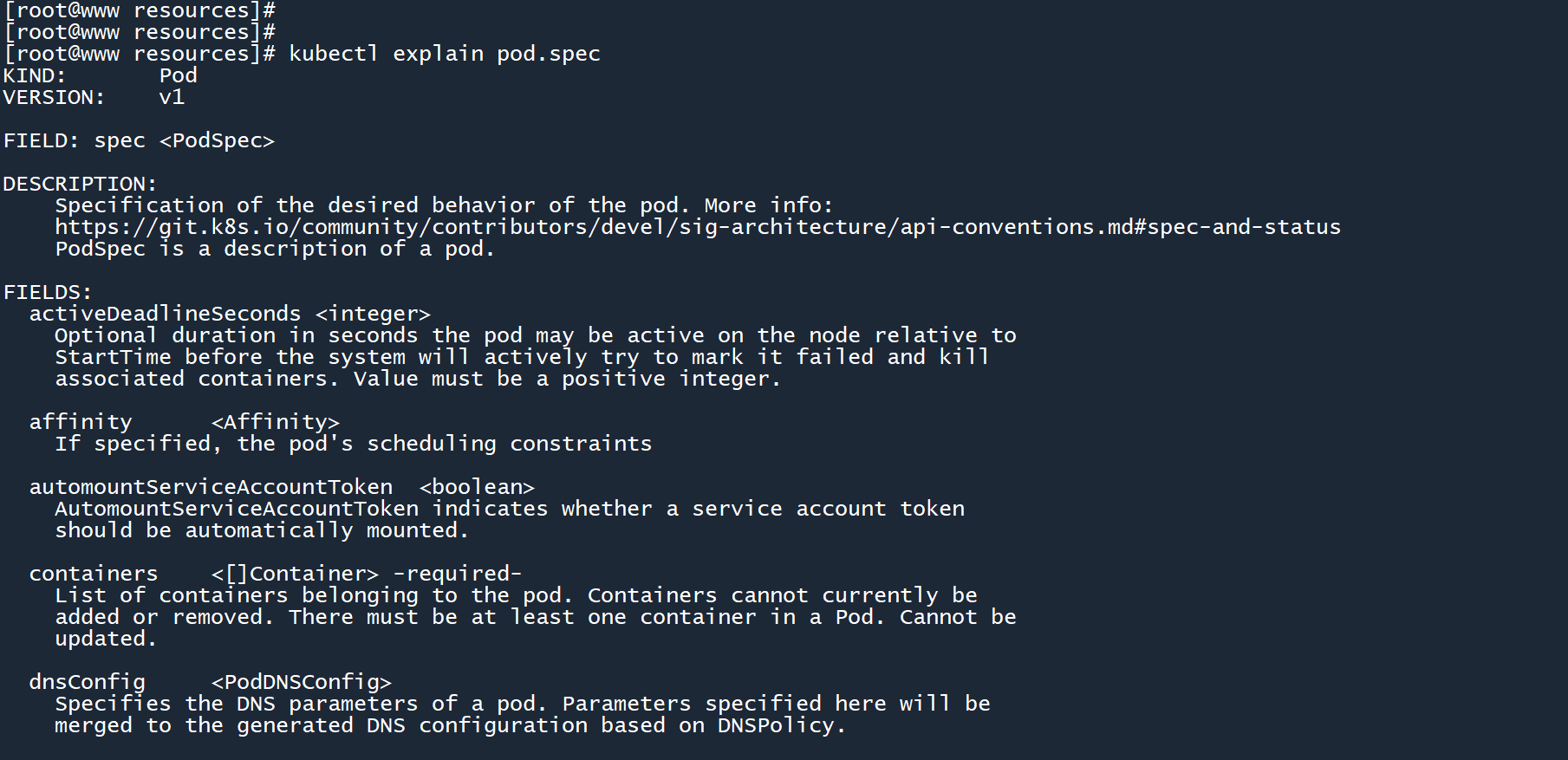
既然提到了spec.containers,那不妨来看看容器的生命周期:
kubectl explain pod.spec.containers.lifecycle
噢,原来在容器的生命周期中,可以使用postStart和preStop钩子呀,差点忘了。
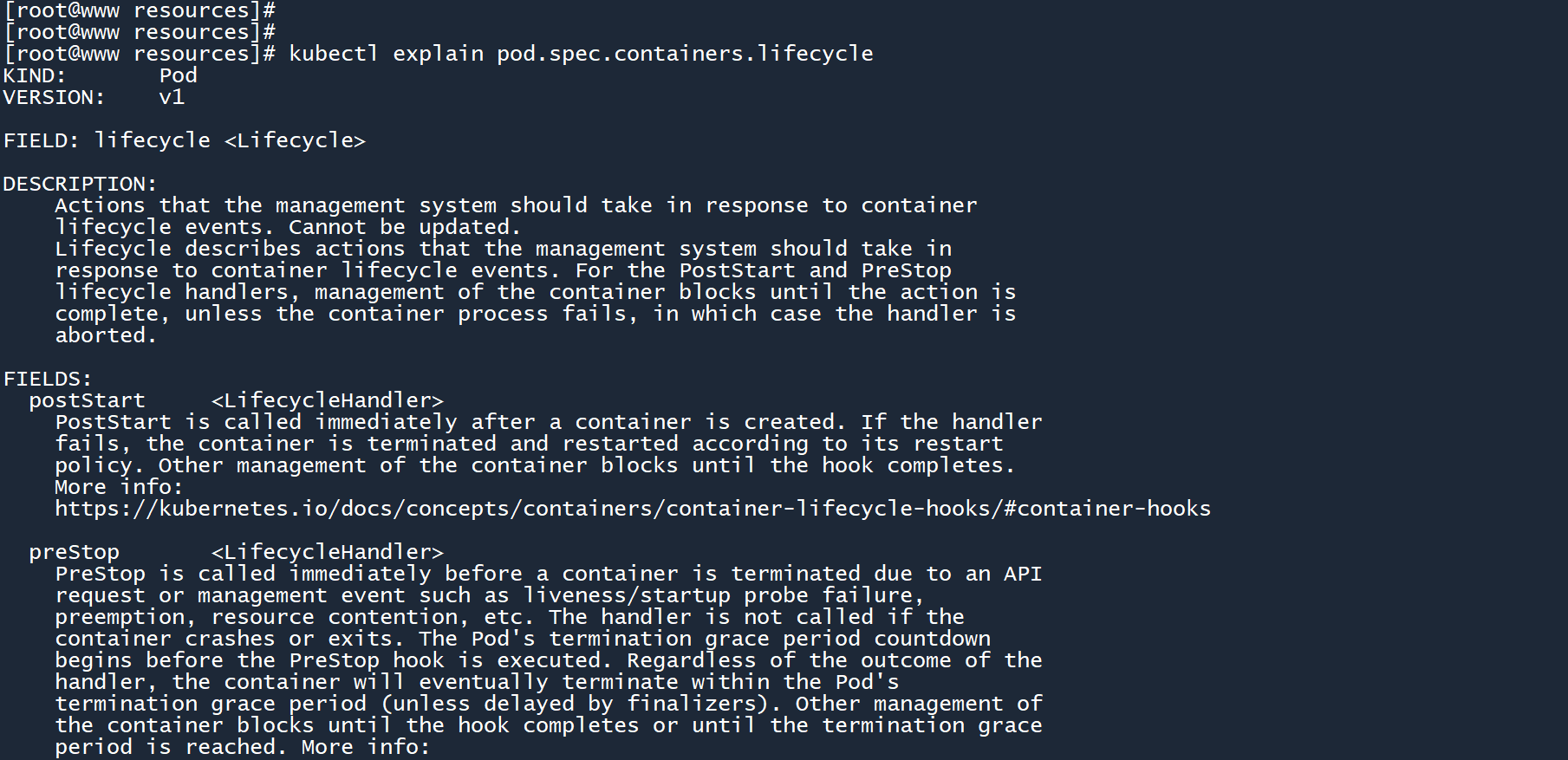
命令kubectl explain可以无限嵌套,只要存在这个字段:
kubectl explain pod.spec.containers.lifecycle.postStart
你可能会看见许多陌生的字段,不用着急,这些字段在后续的章节中都会一一讲解,你将会逐步掌握它们。
你可能已经发现了,命令的格式是这样的:
kubectl explain <资源类型>.<字段>
看看 LimitRange 的spec.limits字段。

看看 ResourceQuota 的metadata字段
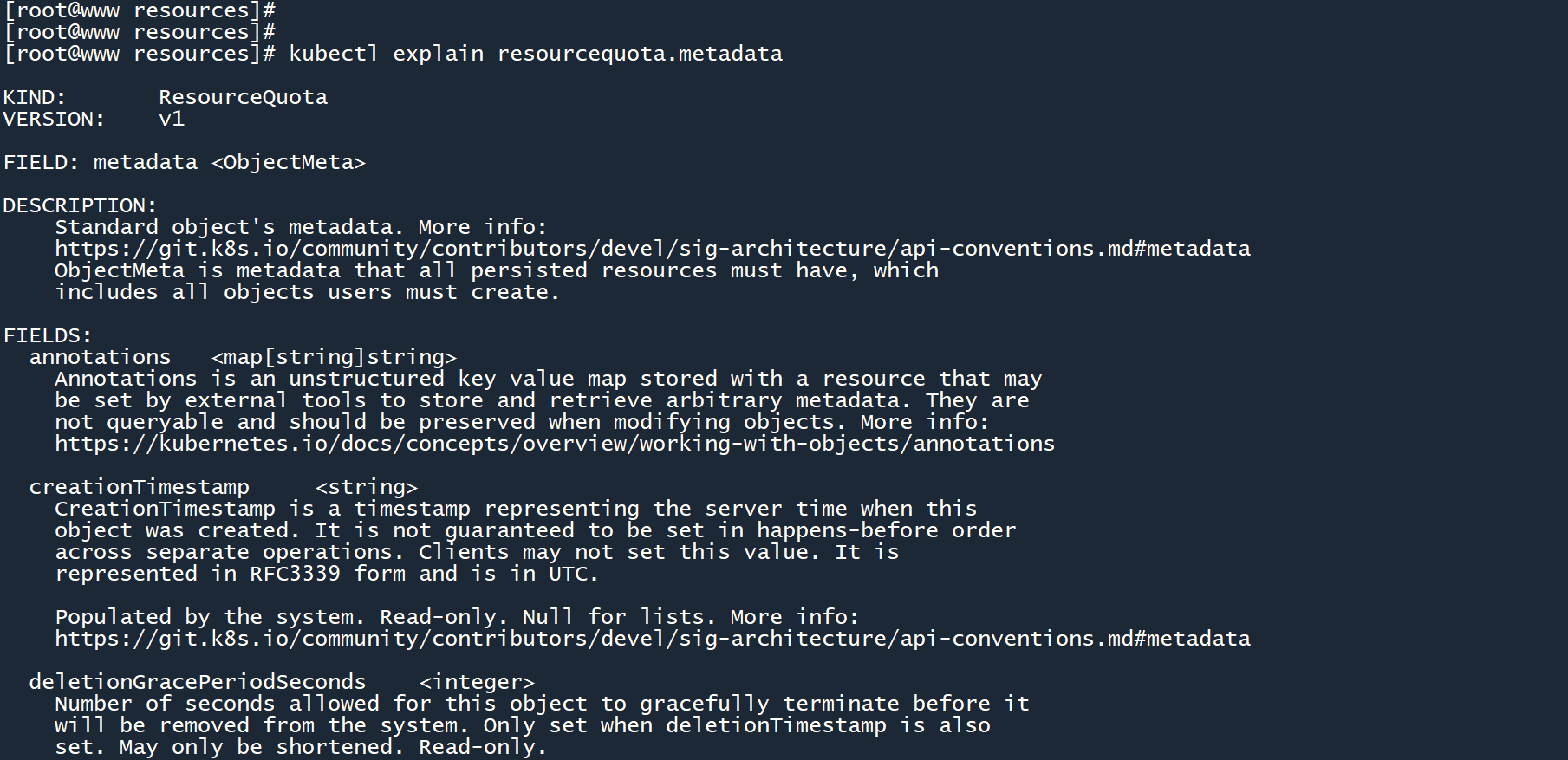
你不必特意花费大量的时间去记 yaml 参数,只需要掌握kubectl explain命令,然后多做做练习题就可以了。
# 77. 小结
本章对 Pod 生命周期做了一个简单的认识,然后学习了钩子的使用方法。还通过 yaml 文件中的参数字段以及外部集群资源对 Pod 施加了资源限制。通过本章的学习,你应该掌握以下技能:
- 宽限期的设置
- “启动钩子” 和 “结束钩子” 的使用
- 通过 yaml 文件中的
resources对容器施加资源限制 - 通过 LimitRange 对集群对象施加资源限制
- 通过 ResourceQuota 对命名空间施加资源调度限制
- 使用
kubectl explain命令查看 yaml 参数字段
如果你准备好了,可以试着去完成一些练习(练习题-4)。